系列文章目录
前言
今天我们一起来谈一下pytorch的一个重要特性----自动求导机制Autograd。
一、Autograd是什么?
Autograd自动求导机制,是pytorch中针对神经网络反向求导与梯度更新所开发的便利工具,内嵌在tensor操作中。
二、Autograd的使用方法
1.在tensor中指定
创建Tensor时声明requires_grad参数为true
>>> import torch
>>> a=torch.randn(5, 3, requires_grad=True)
>>> b=torch.randn(5, 3)
>>> a.requires_grad, b.requires_grad
True, False
# 可以看到默认的Tensor是不需要求导的,设置requires_grad为True后则需要求导
# 也可以通过内置函数requires_grad_()将Tensor变为需要求导
>>> b.requires_grad_()
>>> b.requires_grad
True
2.重要属性
tensor的两个重要属性:
.grad:记录梯度
.grad_fn:记录操作
require_grad参数表示是否需要对该Tensor进行求导,默认为False,一旦设定为True,则该Tensor的之后的所有节点都自动默认为True.
>>> import torch
>>> a=torch.randn(3, 3)
>>> b=torch.randn(3, 3, requires_grad=True)
>>> c = a + b
>>> c.requires_grad
True
# 通过计算生成的Tensor,由于依赖的Tensor需要求导,因此c也需要求导
>>> a.grad_fn, b.grad_fn, c.grad_fn
(None, None, <AddBackward1 object at 0x7fa7a53e04a8>)
# a与b是自己创建的,grad_fn为None,而c的grad_fn则是一个Add函数操作
>>> d = c.detach()
>>> d.requires_grad
False
# Tensor.detach()函数生成的数据默认requires_grad为False。
三、Autograd的进阶知识
1、动态计算图
每一步Tensor的计算操作,会生成计算图,并将操作的function记录在Tensor的grad_fn中。每一次前向都会生成新的计算图,这是动态的来源。同时反向一次之后计算图就会清空,不能在此基础上继续进行求导。
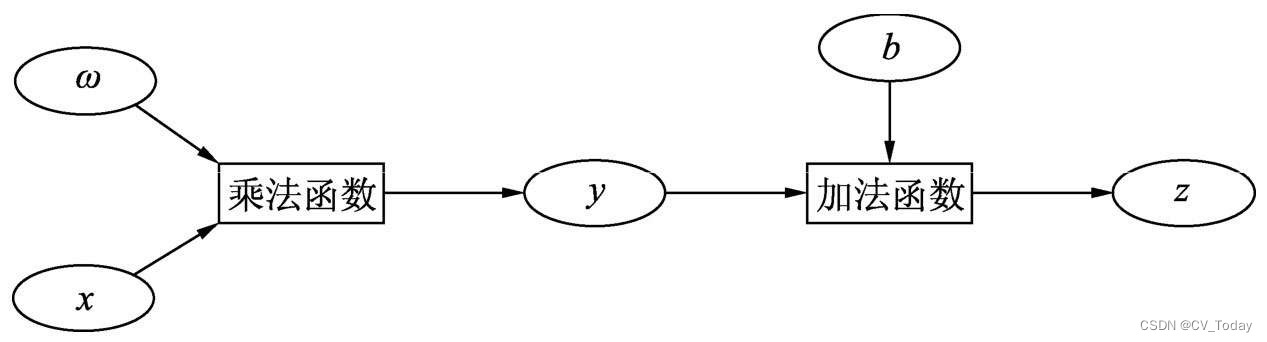
在前向计算完后,只需对根节点进行backward函数操作,即可从当前根节点自动进行反向传播与梯度计算,从而得到每一个叶子节点的梯度,梯度计算遵循链式求导法则。
2、梯度累加
grad一般计算完继续保留,不主动清空会累加。
for i, (inputs, labels) in enumerate(trainloader):
outputs = net(inputs) # 正向传播
loss = criterion(outputs, labels) # 计算损失函数
loss = loss / accumulation_steps # 损失标准化
loss.backward() # 反向传播,计算梯度
if (i+1) % accumulation_steps == 0:
optimizer.step() # 更新参数
optimizer.zero_grad() # 梯度清零
if (i+1) % evaluation_steps == 0:
evaluate_model()
1.正向传播,将数据传入网络,得到预测结果
2.根据预测结果与label,计算损失值
3.利用损失进行反向传播,计算参数梯度
4.重复1-3,不清空梯度,而是将梯度累加
5.梯度累加达到固定次数之后,更新参数,然后将梯度清零
总结来讲,梯度累加就是每计算一个batch的梯度,不进行清零,而是做梯度的累加,当累加到一定的次数之后,再更新网络参数,然后将梯度清零。
通过这种参数延迟更新的手段,可以实现与采用大batch size相近的效果。大多数情况下,采用梯度累加训练的模型效果,要比采用小batch size训练的模型效果要好很多。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了自动求导机制的使用和意义,后续的使用中一般会集成在模块中,熟悉它的相关流程更重要。