Scrapy框架三大优点:
- Scrapy框架是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
scrapy实现流程图:
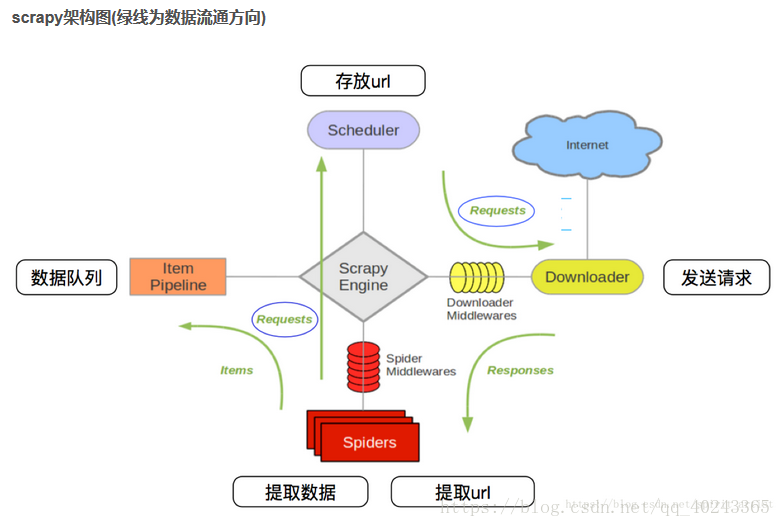
scrapy各个模块简单介绍:
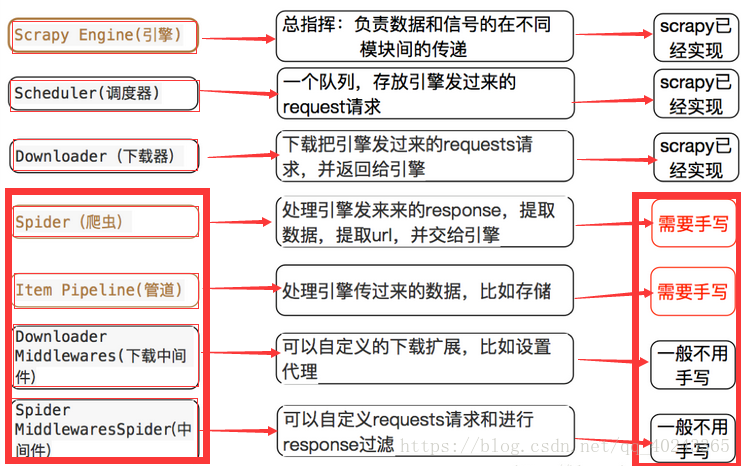
步骤:
1.打开pycharm3.6
2.打开terminal命令行输入’scrapy startproject 项目名’,就会建立一个scrapy项目的文件夹
3.建立scrapy主程序,爬虫主要过程都在这里实现,同样在命令行输入’scrapy crawl -t 文件夹名 url’这里url是要爬取的网址,黏贴进去,就会建立一个模板。
4.打开刚建立的py文件,填入网址,这里以51job为例
代码如下:
from scrapy.spider import CrawlSpider
from scrapy.selector import Selector
from ..items import Job51Item
from scrapy.http import Request
import re
from copy import deepcopy
class Job51(CrawlSpider):
name = 'job51'#与建立的py文件名相同
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,%25E4%25BA%25BA%25E5%25B7%25A5%25E6%2599%25BA%25E8%2583%25BD,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
start_urls = [url]
#可以不用去设置settings文件,直接指定管道文件
# custom_settings = {
# 'ITEM_PIPELINES' : {
# # 'job51.pipelines.Job51Pipeline': 300,
# 'job51.pipelines.saveToJson': 310
# #'job51.pipelines.saveToMongoDB': 320
# }
# }
# 定义一个计数变量
times = 0
def parse(self, response):
self.times+=1
#response是下载器下载的网页内容
selector = Selector(response)#创建selector对象
item=Job51Item()
parent = selector.xpath('//div[@id="resultList"]//div[@class="el"]')
#print(parent)
for each in parent:
#获取职位信息
jobname = each.xpath('./p/span/a/@title').extract()
jobsrc = each.xpath('./p/span/a/@href').extract()[0]
companyname = each.xpath('./span[1]/a/text()').extract()
address = each.xpath('./span[2]/text()').extract()
money = each.xpath('./span[3]/text()').extract()
ptime = each.xpath('./span[4]/text()').extract()
#print(jobname,companyname,address,money,ptime)
if money:
money=money[0]
else:
money='面谈'
item['jobname']=jobname[0]
item['companyname']=companyname[0]
item['address']=address[0]
item['money']=money
item['ptime']=ptime[0]
#因为每一条都在循环内
yield Request(jobsrc,meta={'front_item':deepcopy(item)},callback=self.parse_detail,dont_filter=True)
#实现多页爬取
#寻找下一页的链接
next = selector.xpath('//div[@class="dw_page"]//ul//li[@class="bk"][2]/a/@href')[0].extract()
print("下一页:",next)
#提交请求
if self.times<4:
yield Request(next,callback=self.parse)
#爬取详情页的函数
def parse_detail(self,response):
item = response.meta['front_item']
selector = Selector(response)
#提取信息
div = selector.xpath('//div[@class="bmsg job_msg inbox"]')
if div:
div=div[0]
else:
return
#提取所有文本
#txt = div.xpath('./p/font/font/text()').extract()
txt = div.xpath('string(.)').extract()[0]
#print(txt)
#使用正则去除空格
reg = re.compile('\S*',re.S)
#提取所有非空白符
result = re.findall(reg,txt)
datalist = []
for i in result:
if i :
datalist.append(i)
#print(datalist)
#给item
item['detail']=str(datalist)
yield item
5.打开items的py文件,将爬取的信息提交
代码如下:
import scrapy
from scrapy import Item,Field
class Job51Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
jobname = Field()
companyname = Field()
address = Field()
money = Field()
ptime = Field()
detail =Field()
6.进入settings文件打开下载器中间键开关,程序如下:
根据需要打开,就会进入中间件执行代码
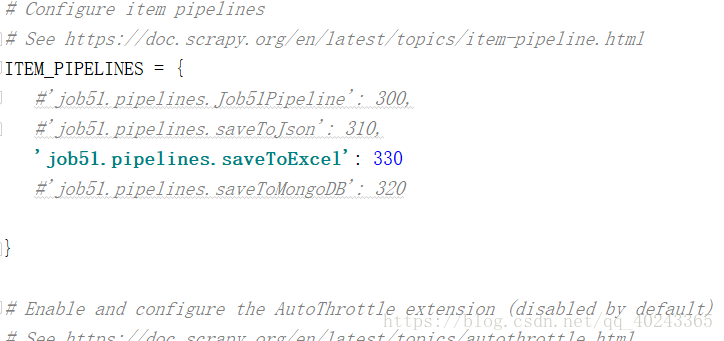
7.打开pipelines文件,写入存储文件的代码
代码如下:(这里提供三种存储方式,根据需要在settings中打开)
import json
class Job51Pipeline(object):
def __init__(self):
pass
def process_item(self, item, spider):
return item
def close_spider(self,spider):
pass
#1.存储为json文件
class saveToJson(object):
def __init__(self):
self.file = open('job51.json','w',encoding="utf-8")
def process_item(self, item, spider):
#把每一个item转化为json
each = json.dumps(dict(item),ensure_ascii=False)
self.file.write(each+'\n')
return item
def close_spider(self,spider):
self.file.close()
from pymongo import MongoClient
#2.存储为MongoDB
class saveToMongoDB(object):
# 1.连接本地数据库服务
def __init__(self):
self.connection = MongoClient('localhost')
# 2.连接本地数据库 没有会创建
self.db = self.connection.job
# 3.创建集合
self.job = self.db.job51
def process_item(self, item, spider):
self.job.insert_one(dict(item))
def close_spider(self, spider):
pass
from openpyxl import Workbook
#3.存入excel
class saveToExcel(object):
def __init__(self):
self.wb = Workbook()
self.ws =self.wb.active
def process_item(self,item,spider):
self.ws.append(list(dict(item).values()))
def close_spider(self,spider):
self.wb.save('岗位详细信息.xlsx')
8.进入中间件,设置头部或代理ip,有的网站必须用到浏览器头部和ip进行爬取才更安全。
代码如下:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import random
from scrapy import signals
#爬虫中间键
class Job51SpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
#下载中间键
class Job51DownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
#设置浏览器头部
request.headers['user_agent']=random.choice(user_agent)
print(22222222222222)
# #设置代理
# request.meta['proxy'] = '114.247.89.49:8000'
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
9.最后就是运行整个框架的关键,这里建议穿件一个运行的py文件,方便快捷,建立main.py文件,写入如下代码:
from scrapy import cmdline
cmdline.execute('scrapy crawl job51'.split())
每次运行main文件就会运行整个程序