Transformer是一种基于自注意力机制的神经网络架构,它能够从序列中提取重要信息,已被广泛应用于自然语言处理和语音识别等领域。随着Transformer的提出和发展,目标检测领域也开始使用Transformer来提高性能。
DETR是第一篇将Transformer应用于目标检测领域的算法,论文与代码地址如下:
论文地址:[2005.12872] End-to-End Object Detection with Transformers (arxiv.org)
代码地址:GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers
DETR将Transformer应用至目标检测领域,虽然没有取得当时的SOTA,但其为目标检测打开了一扇新的大门,并且在后续的研究中为目标检测带来了许多创新,在目标检测与实例分割领域持续霸榜。
DETR论文通篇在强调一个重点:简单。那么它究竟有多简单呢?论文的最后给出了一段代码
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)DETR仅用几十行代码即可完成模型的构建,其结构图如下:

按照前向传播的思路,梳理DETR:
1. 图像先经过卷积骨干网络的处理,得到特征图,随后为了减少计算复杂度,通过conv层对特征图进行降维,此时特征图的维度为:(b,c,w,h)。为了将特征输入进Transformer,需要沿w、h维度将特征图拉平,得到:(b,c,s),其中s=w*h,表示序列长度。随后调整特征维度为(s,b,c),输入进Transformer。
2.通过Transfomer Encoder的全局建模处理,特征序列被赋予了更多语义信息,论文中将其称为memory。此时将object queries与memory共同输入至Transformer Decoder中。
3.Decoder通过Cross Attention机制,在memory中提取有助于object queries预测的特征,并输入至分类头与测头中,得到类别与预测框。
在下文中,我们将详细介绍这三个主要步骤,以更深入地理解DETR的工作原理。
卷积骨干网络
DETR论文发表于2020年,此时Vision Transformer还没有被提出,因此DETR使用的是卷积骨干网络ResNet50,用于特征提取。
ResNet50对图像输入进行32倍下采样。当图像尺寸为(batch_size,3,640,640)时,经过ResNet50的处理,得到(batch_size,2048,20,20)的特征图。
为了减少计算复杂度,使Transformer更高效的处理序列,使用一个1*1卷积,对输出的特征图进行降维,得到(batch_size,256,20,20)的特征图。
Transfomer Encoder的输入形式为(s,bach_size,c),其中s表示序列长度,c表示特征维度,因此要将特征图拉平为序列,并调整为(s,bach_size,c)形式,再加入位置编码,即可输入至Encoder中。
Transformer Encoder
Transformer Encoder的作用是特征加强。Encoder可以捕获序列之间的依赖关系,输出仍为(s,batch_size,c)的特征序列。Encoder结构如下,这里不对结构进行讲解。

之所以说Encoder的作用是特征加强,是因为Encoder不是必须的,论文中给出了不同数量的Encoder对结果的影响,如下表:

从表中可以看出,即使不使用Encoder结构,也能得到36.7的AP。
下面用一张图来具体演示Encoder的作用:

上图为Encoder中注意力机制的可视化,原理是在目标身上取一像素(上图中的红点),然后将这一像素与图上所有像素的注意力权重进行可视化。可以看出,Encoder中的注意力机制几乎将整个目标都抠了出来,即使是在遮挡严重的情况下也能较好的完成注意力的分配。
Encoder将ResNet提取的特征进行了加强,捕获了空间层面的依赖关系,使得特征能够更好的表示出目标的轮廓。
Transformer Decoder
Decoder的输入有两个:object queries与memory(Encoder的输出)。
Decoder可以看作是object queries“生长”的过程。
object queries有些类似于YOLO中的anchor,关于YOLO算法的讲解可以看我的这篇文章YOLOv5深度剖析_yolov5骨干网络-CSDN博客。从object queries到预测框的过程中可以看作是一个生长的过程。有别于标准的Transformer Decoder,object queries首先通过一个不带掩码的多头自注意力机制,以协调object queries之间工作,随后通过Cross Attention机制,在memory中查询待检测物体,最后经过分类头与预测头的处理,输出类别与检测框。

下面通过可视化的方式来展示Decoder学到了哪些信息:

通过上图可知,Decoder的注意力均集中在目标的边缘位置,这说明Decoder学习到了目标的边缘信息,有助于更加精准的定位目标。
二分图匹配
DETR除了检测流程上的创新,还将二分图匹配应用至检测框的匹配上,使得模型无需非极大值抑制,实现端到端的输出检测框。
DETR的输出是一个集合,无论输入什么样的图像,模型最后都会输出固定数量的集合,这个集合就是预测框与类别。在训练过程中,如何完成输入框与Ground Truth(真实框)的匹配,也成为了训练的核心问题。
假设现在有4个object query,和3个Ground Truth
| Ground Truth 1 | Ground Truth 2 | Ground Truth 3 | |
| object query 1 | 0.13 | 0.54 | 0.22 |
| object query 2 | 0.45 | 0.67 | 0.12 |
| object query 3 | 0.45 | 0.12 | 0.73 |
| object query 4 | 0.25 | 0.46 | 0.57 |
上面的矩阵记录了每种匹配方式产生的损失,而二分图匹配的任务就是找到一种方式,使得匹配产生的损失最小,一种时间复杂度较小的二分图匹配的方式叫做匈牙利算法,匈牙利算法能够在时间复杂度较低的情况下很好的解决二分图匹配问题。
DETR的源码中,直接使用了scipy库中提供的匈牙利算法函数linear_sum_assignment来解决二分图匹配的问题。
总结
DETR(Detection Transformer)是一种基于Transformer架构的目标检测器,为目标检测领域打开了一扇新的大门。但值得注意的是,DETR在COCO数据集上的AP并没有达到SOTA水平,并且存在着难以收敛的问题。
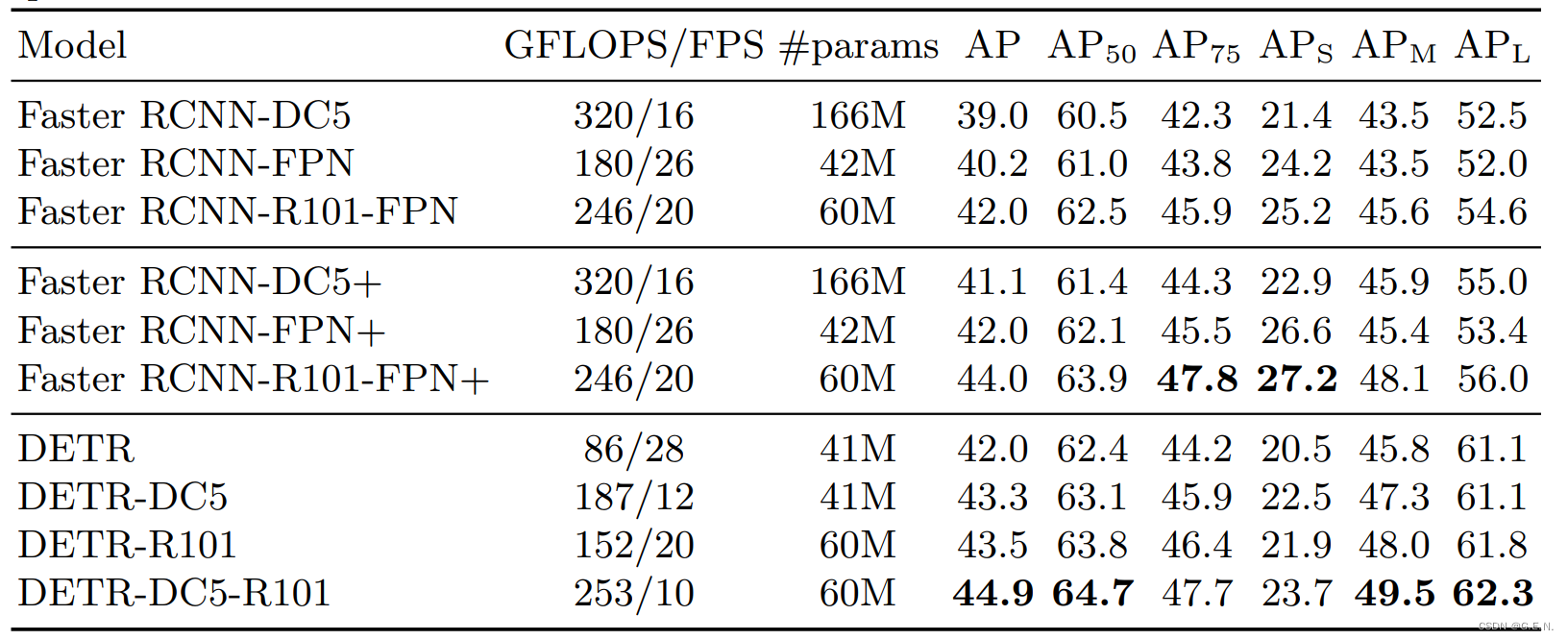
随着后续的不断改进,DETR在目标检测任务中越来越好,解决了AP不高和难以收敛等问题。COCO数据集也被DETR后续的不同改进霸榜。期待DETR涌现更多优秀的后续工作。