本文首发于微信公众号 CVHub,不得以任何形式转载到其它平台,仅供学习交流,违者必究!
Title: Open World DETR: Transformer based Open World Object Detection
Paper: https://arxiv.org/pdf/2212.02969v1.pdf
Author: Na Dong et al. (NUS)
Introduction
开放世界目标检测其实是一个相对来说比较少人关注的领域,其旨在不限定特定目标类别的情况下,对图像中的所有目标进行检测。与传统的目标检测方法有所不同,传统方法通常需要提前限定目标类别,并且只能检测预先定义好的目标类别。因此,面向开放世界的目标检测具备以下优势,例如:
- 可以检测新出现的未知目标,这对于应用在动态环境中的系统来说是非常重要的
- 可以更快速地进行目标检测,因为无需预先定义目标类别,也无需训练多个分类器(多模型)
本文为大家介绍一种名为Open World DETR的两阶段训练方法,该方法基于Deformable DETR,旨在在没有明确监督的情况下,检测训练数据中不存在的未知对象。此外,必须在持续增量地给出未知对象的相应注释时,识别出未知对象的确切类别,而不会导致先前已知类别的灾难性遗忘。
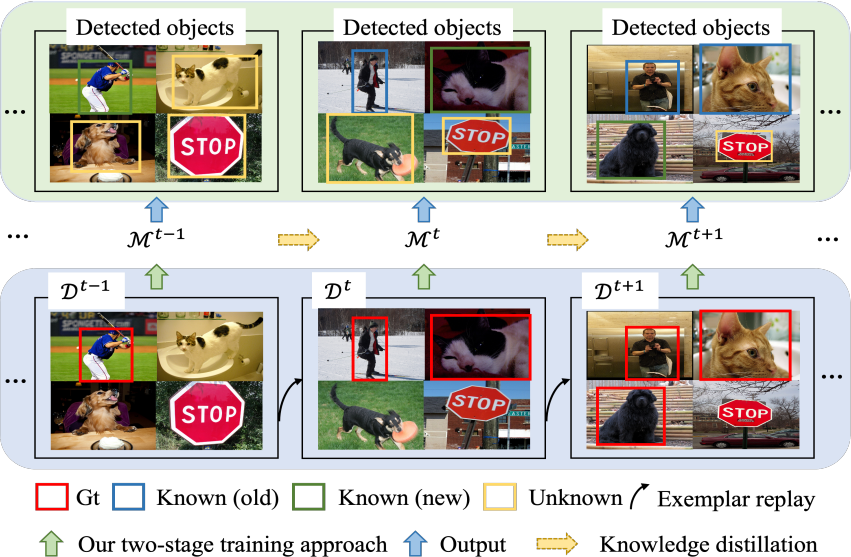
第一阶段:使用当前带标注的数据来训练一个模型,以便从当前已知的类别中检测对象,同时训练一个额外的二分类器,用于将预测分类为前景或背景类别。这有助于模型构建一个不受偏见的特征表示,可以促进在随后的过程中检测未知类别。
第二阶段:使用多视图自标签策略和一致性约束来微调模型的特定组件。此外,通过使用知识蒸馏和典型复现来缓解在未知类别的注释逐渐可用时的灾难性遗忘。
在PASCAL VOC和MS-COCO上的实验结果表明,本文所提出的方法在大幅度上优于其他最先进的开放世界目标检测方法。
exemplar replay,是增量学习领域中一种非常经典的方法,用于缓解遗忘已经学过的知识,以便保留原来的性能。它通过将先前学习的样本(称为“exemplar”)复制并插入新的训练数据中来实现这一目的。这样,模型就可以继续在新的数据上进行训练,同时保持对先前学习的样本的记忆。在本文中,作者使用该方法来缓解在未知类别的注释逐渐可用时的灾难性遗忘。
Motivation
现如今,大部分传统的基于深度学习的目标检测算法是基于封闭世界假设的,因此,即使是当前最先进目标检测方法也很难识别出未知类别的对象,因此学术界延伸出了另外一种新的检测任务—面向开放世界的目标检测。
一般而言,人类比机器更擅长识别未知类别的对象,在绝大多数情况下都能正确区分已知类别中的未知对象并快速识别未知对象。在推理时,即使是当前最先进的基于深度学习的物体检测方法也无法感知未知对象。(对于单纯的通用检测模型严格来说我认为应该不算,毕竟这种方法只能单纯的区分前景和背景,但不能感知到具体的类别)
开放世界物体检测旨在通过训练基于深度学习的物体检测器来检测未知物体,并且不需要明确的监督。此外,在逐步给出未知物体的注释时,必须能够识别这些未知物体,同时不会忘记之前已知的类别。具体来说,要实现开放世界物体检测,必须克服三大挑战:
-
除了准确识别已知类别外,模型还必须学会在无监督的情况下为未知类别生成高质量的
proposal; -
在全监督的情况下,目标检测模型往往会将潜在的未注释的未知物体抑制为背景。在开放世界物体检测设置中,模型必须能够将未知物体与背景分离开来;
-
使用已知类别的注释训练的模型极大概率会偏向于将未知物体检测为已知类别之一。在开放世界物体检测设置中,模型必须能够将未知物体与已知类别区分开来。
下面,让我们看下先前的代表性工作是如何实现的:
先来看下经典的开放目标世界检测工作——ORE,该方法基于Faster R-CNN,其依赖于保留的验证集来估计未知类别的分布。
相比之下,本文方法不需要任何未知类别的监督,相对来说更符合开放世界物体检测的定义。
再来看下基于Transformer的开放世界物体检测方法——OW-DETR,该方法利用基于注意力的伪标签方案来选择注意力分数较高但与任何已知类别的GT边界框不匹配的物体查询框作为未知类别的伪提议框。尽管OW-DETR比ORE的性能有所提高,但该方法本质上对注意图的依赖导致只有少部分具有高注意分数的未知物体被定位,从而抑制了其余的部分未知物体。
Methods
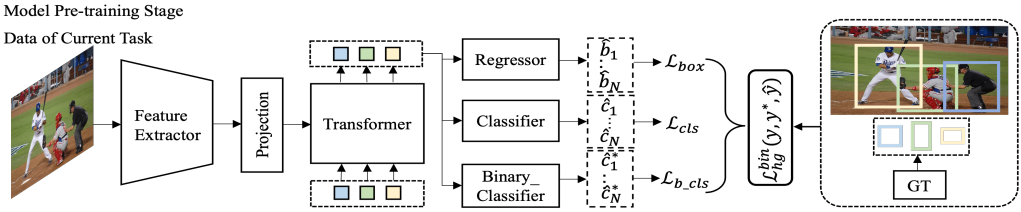
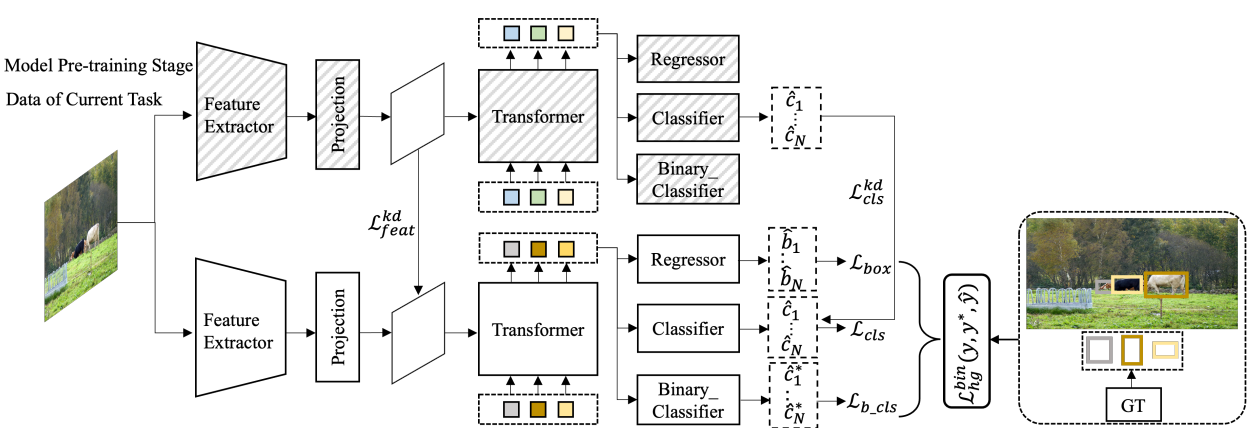
第一阶段的方法如上图所示,结构挺简单的,就是基于Deformable DETR的框架训练处一个检测器出来,Backbone是基于Transformer,Head部分在原有的框架上加多了一个分支:
- Regressor:回归出物体所在的位置;
- Classifier:学习当前物体的类别;
- Binary_Classifier:仅学习如何区分前景和背景,为第二阶段的学习做准备。
第三个分支的具体训练步骤也很简单,只需将所有前景的标签设为0,背景设为1即可,损失函数后面会讲。
Transformer笔者在去年已经大致介绍过了感兴趣的小伙伴可以直接翻阅公众号『CVHub』历史文章,本文不再详述,下面简单讲解下本方法所涉及到的其他相关知识点。
DETR
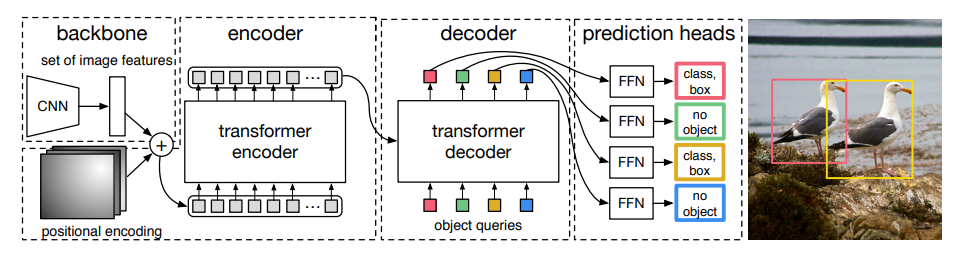
同先前的目标检测器范式不同,DETR框架致力于推断出一个固定长度为N的预测集合(长度序列),即输出N个预测框和对应的类别置信度,其中N远大于实际的GT数(看图理解)。
其次,以往的目标检测器如YOLO系列等,大部分都是通过建立Anchor与GT之间的联系(一般为IoU)来区分正、负样本,而DETR则是基于一种匹配策略来确定正、负样本的,公式如下所示:
σ ^ = arg min σ ∈ S N ∑ i N L match ( y i , y ^ σ ( i ) ) \hat{\sigma}=\underset{\sigma \in \mathfrak{S}_N}{\arg \min } \sum_i^N \mathcal{L}_{\operatorname{match}}\left(y_i, \hat{y}_{\sigma(i)}\right) σ^=σ∈SNargmini∑NLmatch(yi,y^σ(i))
其中, L match ( y i , y ^ σ ( i ) ) \mathcal{L}_{\operatorname{match}}\left(y_i, \hat{y}_{\sigma(i)}\right) Lmatch(yi,y^σ(i))表示的是真值 y ^ \hat{y} y^ 与预测值 y ^ σ ( i ) \hat{y}_{\sigma(i)} y^σ(i) 之间的匹配代价函数。这里,$\mathcal{L}_{\operatorname{match}}$ 通常采用Hungarian loss作为损失函数
Hungarian loss
Hungarian loss最早由Russell Stewart和Mykhaylo Andriluka两人于CVPR 2015所发表的文章中提出,文中首次将二分图匹配(Bipartite Matching)和匈牙利算法(Hungarian Algorithm)引入深度学习目标检测任务中的成功案例。
Hungarian loss其实理解起来也不难,本质上就是先利用匈牙利算法进行配对,然后基于这个匹配结果计算相应的损失。
具体地,我们先基于匈牙利算法来求解出最优的匹配结果:
σ ^ = arg min σ ∈ G N ∑ i N L match ( y i , y ^ σ ( i ) ) L match ( y i , y ^ σ ( i ) ) = − 1 { c i ≠ ∅ } p ^ σ ( i ) ( c i ) + 1 { c ≠ ∅ } L box ( b i , b ^ σ ( i ) ) \begin{gathered} \hat{\sigma}=\underset{\sigma \in \mathfrak{G}_N}{\arg \min } \sum_i^N \mathcal{L}_{\text {match }}\left(y_i, \hat{y}_{\sigma(i)}\right) \\ \mathcal{L}_{\text {match }}\left(y_i, \hat{y}_{\sigma(i)}\right)=-\mathbb{1}_{\left.\left\{c_i \neq \varnothing\right\} \hat{p}_{\sigma(i)}\left(c_i\right)+\mathbb{1}_{\{c} \neq \varnothing\right\}} \mathcal{L}_{\text {box }}\left(b_i, \hat{b}_{\sigma(i)}\right) \end{gathered} σ^=σ∈GNargmini∑NLmatch (yi,y^σ(i))Lmatch (yi,y^σ(i))=−1{ ci=∅}p^σ(i)(ci)+1{ c=∅}Lbox (bi,b^σ(i))
最后,通过获取匹配结果后,计算出损失函数,进行相应的梯度回传:
L Hungarian ( y , y ^ ) = ∑ i = 1 N [ − log p ^ σ ^ ( i ) ( c i ) + 1 { c i ≠ ∅ } L box ( b ˙ i , b ^ σ ^ ( i ) ) ] \mathcal{L}_{\text {Hungarian }}(y, \hat{y})=\sum_{i=1}^N\left[-\log \hat{p}_{\hat{\sigma}(i)}\left(c_i\right)+\mathbb{1}_{\left\{c_i \neq \varnothing\right\}} \mathcal{L}_{\text {box }}\left(\dot{b}_i, \hat{b}_{\hat{\sigma}}(i)\right)\right] LHungarian (y,y^)=i=1∑N[−logp^σ^(i)(ci)+1{ ci=∅}Lbox (b˙i,b^σ^(i))]
需要注意的是,在原始的论文中,作者在进行二分图匹配时,参照物是直接采用GT,即为每个预测值均考虑其最佳的匹配结果,因此预测值的下标是直接采用GT的下标i作为索引,代表与当前GT所匹配的预测框,这便是原文所提及到的置换不变形(Permutation Invariant)。为了消除这种影响,我们可以引入Positional Encoding,使其变为置换同变性(Permutation Variant)。
更详细的解读可参考此篇文章,由于篇幅内容有限,本文不再做详细阐述。
了解完原始的损失函数如何定义后,我们再来看看本文是如何实现的。首先,对于两个分支定义如下:
σ ^ = arg min σ ∑ i = 1 N L match ( y i , y ^ σ ( i ) ) σ ^ ∗ = arg min σ ∗ ∑ i = 1 N L match ( y i ∗ , y ^ σ ∗ ( i ) ∗ ) \begin{aligned} \hat{\sigma} & =\underset{\sigma}{\arg \min } \sum_{i=1}^N \mathcal{L}_{\text {match }}\left(y_i, \hat{y}_{\sigma(i)}\right) \\ \hat{\sigma}^* & =\underset{\sigma^*}{\arg \min } \sum_{i=1}^N \mathcal{L}_{\text {match }}\left(y_i^*, \hat{y}_{\sigma^*(i)}^*\right) \end{aligned} σ^σ^∗=σargmini=1∑NLmatch (yi,y^σ(i))=σ∗argmini=1∑NLmatch (yi∗,y^σ∗(i)∗)
- 定义常规的分类+回归分支:
L match ( y i , y ^ σ ( i ) ) = 1 { c i ≠ ∅ } L c l s ( c i , c ^ σ ( i ) ) + 1 { c i ≠ ∅ } L box ( b i , b ^ σ ( i ) ) \begin{aligned} \mathcal{L}_{\text {match }}\left(y_i, \hat{y}_{\sigma(i)}\right) & =\mathbb{1}_{\left\{c_i \neq \varnothing\right\}} \mathcal{L}_{\mathrm{cls}}\left(c_i, \hat{c}_{\sigma(i)}\right) \\ & +\mathbb{1}_{\left\{c_i \neq \varnothing\right\}} \mathcal{L}_{\text {box }}\left(\mathbf{b}_i, \hat{\mathbf{b}}_{\sigma(i)}\right) \end{aligned} Lmatch (yi,y^σ(i))=1{ ci=∅}Lcls(ci,c^σ(i))+1{ ci=∅}Lbox (bi,b^σ(i))
- 定义前背景二分类+回归分支:
KaTeX parse error: Expected 'EOF', got '_' at position 168: …_{\text {binary_̲cls }}\left(c_i…
最后,基于上面的定义,我们便可以将最终的损失函数定义为如下形式:
L h g b i n ( y , y ∗ , y ^ ) = ∑ i = 1 N [ L c l s ( c i , c ^ σ ^ ( i ) ) + 1 { c i ≠ ∅ } L b o x ( b i , b ^ σ ^ ( i ) ) + λ b − c l s L b − c l s ( c i ∗ , c ^ σ ^ ∗ ( i ) ∗ ) ] \begin{aligned} & \mathcal{L}_{\mathrm{hg}}^{\mathrm{bin}}\left(y, y^*, \hat{y}\right)=\sum_{i=1}^N\left[\mathcal{L}_{\mathrm{cls}}\left(c_i, \hat{c}_{\hat{\sigma}(i)}\right)\right. \\ & \left.+\mathbb{1}_{\left\{c_i \neq \varnothing\right\}} \mathcal{L}_{\mathrm{box}}\left(\mathbf{b}_i, \hat{\mathbf{b}}_{\hat{\sigma}(i)}\right)+\lambda_{\mathrm{b}_{-} \mathrm{cls}} \mathcal{L}_{\mathrm{b}_{-} \mathrm{cls}}\left(c_i^*, \hat{c}_{\hat{\sigma} *(i)}^*\right)\right] \end{aligned} Lhgbin(y,y∗,y^)=i=1∑N[Lcls(ci,c^σ^(i))+1{ ci=∅}Lbox(bi,b^σ^(i))+λb−clsLb−cls(ci∗,c^σ^∗(i)∗)]
这里,常规分类损失和二分类损失均采用Sigmoid Focal Loss,回归损失则结合L1损失和GIoU损失,权重均为0.5,具体参数同Deformable DETR保持一致。
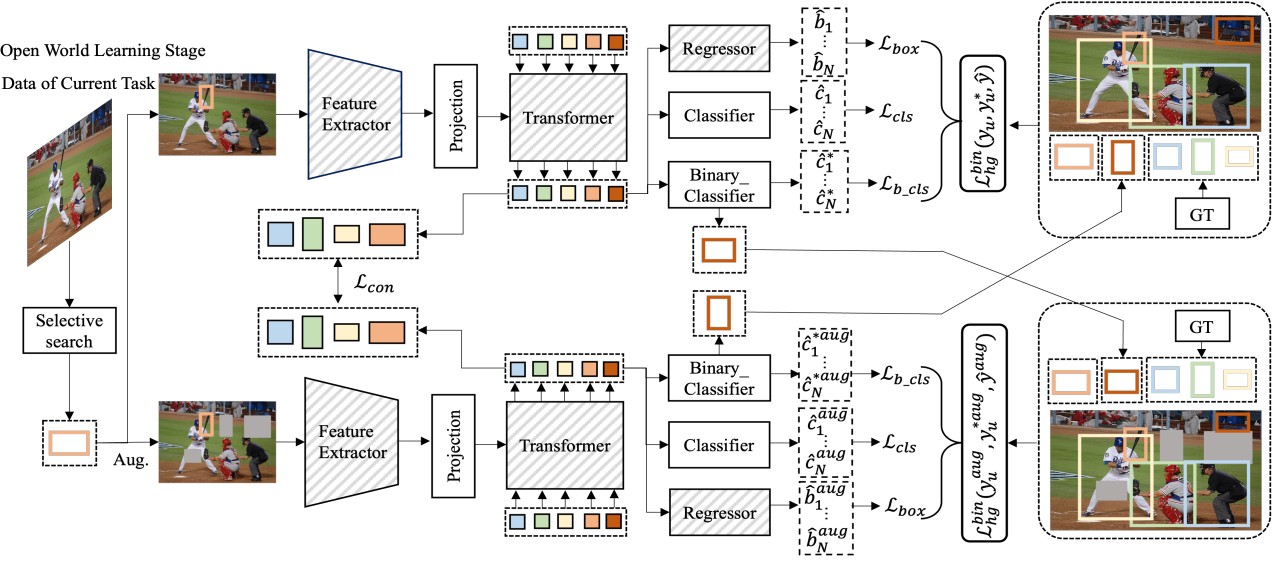
上图描述了一种基于多视图的自动标签策略,它包含两个网络。在训练过程中,灰色斜线模块的参数是fixed的。注意,以上两组损失项是在不同视图上应用同一目标的实例。这里的特征提取器是基于第一阶段训练出来的,由于在一阶段已经学到了如何区分前景和背景(通过Binary_Classifier分支实现),因此这里不需要再单独学习如何定位RoI了,因此直接将Regressor头和Backbone的参数freezed即可。
根据作者的实验结果不难发现,Deformable DETR 中的projection层和classification头是与类别相关的(class-specific),而 CNNs、Transformer 和regressor头是类别不相关的(class-agnostic)。因此,本文提出在从预训练模型初始化模型的参数后,调整类特定组件的参数,而保持类不可知组件的参数不变。在保持类不可知组件的参数不变的同时,调整类特定组件的参数,有助于模型在不遗忘之前检测到的新类别的物体的同时检测到新的类别的物体。
Class-specific 与 Class-agnostic
在目标检测中,我们依据检测器是否关心待检测类别可以简单的划分为class-specific和class-agnostic这两种,下面让我们来简单介绍下它们之间的区别。
首先,class-specific,亦称为class-aware,即与类别相关的或者说是对类别感知的检测算法。早期的经典检测算法如Faster-RCNN系列均属于class-specific,这是因为当我们输入一张图片给检测器时,检测算法会返回特定的类别和对应的边界框给我们,这便称为是与类别相关的。
其次,对于class-agnostic,即与类别无关的或者说是对类别无感的检测算法,大多数是用于诸如显著性检测这类任务上。class-agnostic检测算法中仅区分两类物体——前景和背景。无论你最终检测的目标是阿猫阿狗还是一头猪,在该算法中统称为前景,除前景外的物体全部视为背景。由于检测模型事先并不清楚自己正在检测对象的具体类别,因为我们统称为与类别无关的检测算法。
同样地,延伸到具体架构上,例如CNNs、Transformer和MLP等,这些网络架构宏观上可用于计算机视觉、自然语言处理、语音识别等方向,更细一点就CV而言也可做阿猫阿狗的分类,亦可做行人车辆检测等,因此我们可以简单的理解为class-agnostic,而对于regressor head这个想必更不用说了把?
Multi-view self-labeling
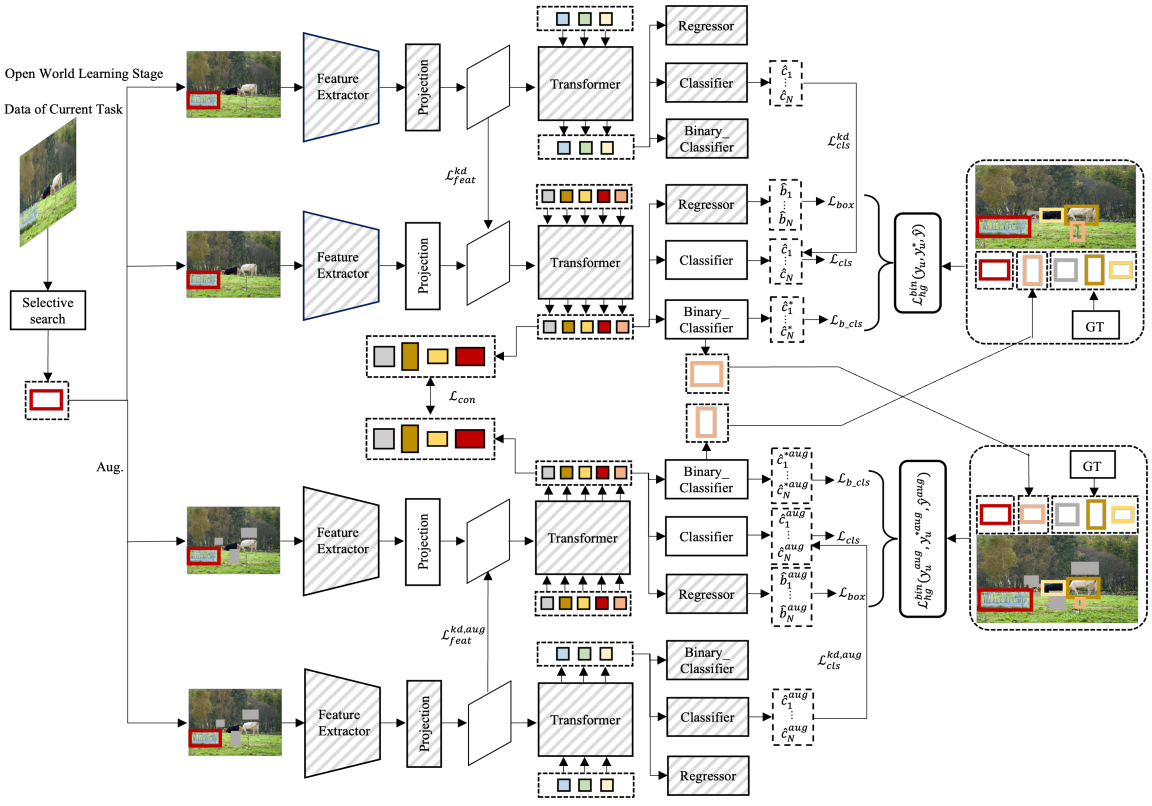
为了解决未知类别的缺失标注问题,如上图所示,作者提出了一种多视角自标签策略来生成未知类别的伪标签以用于训练模型能够学习检测出未知类别。具体做法如下:
- 对输入图像采用通用的数据增强,如随机裁剪和缩放;
- 利用
class-agnostic binary classifier分支为未知类别从预测结果中挑选合适的伪提议框;这里,可以先采用NMS过滤重复的提议框后基于置信度过滤掉分数较低的propossals;
此处需要注意的是,如果这些
pseudo proposals与当前已知类别的真实对象有很多重叠部分,那么这些类别的性能肯定会下降的。为了缓解这个问题,作者通过仅选择非重叠于当前已知类别真实对象的未知类别的最高得分建议,来缓解这个问题,说人话就是挑出最靠谱的。
- 根据两种视图,执行交换预测机制,以鼓励模型对同一图像的不同视图做出一致的预测。这一点其实类似于
Mask的机制,就是强迫网络去学习出这种信息。
此外,为了为未知类别补充更多的 proposals,作者引入了 SSL 选择性搜索算法来生成额外的 proposals,这些提议框不与上述两种方式产生的 proposals 重叠。
选择性搜索算法用于为目标检测算法提供候选区域,优势是速度快,召回率高。首先采用《Efficient Graph-Based Image Segmentation》论文里的方法产生初始的分割区域,然后使用相似度计算方法合并一些小的区域。值得注意的是,
RCNN和Fast RCNN中也用到了这一技术。
Consistency constraint
为了提高特征表示的质量,作者提出在原始图像和增强图像的对象查询特征之间应用一个一致性约束。注意,原始图像的二分类器生成的伪真实对象与增强图像的二类别器生成的伪真实对象不匹配。因此,只在与已知类别的真实对象和选择性搜索生成的伪真实对象匹配的对象查询特征上应用一致性约束。
首先采用 pair-wise matching loss 来找到原始图像和增强图像的最优分配。然后给出匹配的对象查询特征之间的一致性损失,如下所示:
L c o n ( q ^ , q ^ a u g ) = ∑ i = 1 M ℓ 1 ( q ^ σ ^ ( i ) , q ^ σ ^ a u g ( i ) ) \mathcal{L}_{\mathrm{con}}\left(\hat{q}, \hat{q}^{\mathrm{aug}}\right)=\sum_{i=1}^M \ell_1\left(\hat{q}_{\hat{\sigma}(i)}, \hat{q}_{\hat{\sigma}^{\mathrm{aug}}(i)}\right) Lcon(q^,q^aug)=i=1∑Mℓ1(q^σ^(i),q^σ^aug(i))
整体的损失函数为:
L total = L hg bin ( y u , y u ∗ , y ^ ) + L hg bin ( y u aug , y u ∗ aug , y ^ aug ) + λ con L con ( q ^ , q ^ aug ) \begin{aligned} \mathcal{L}_{\text {total }} & =\mathcal{L}_{\text {hg }}^{\text {bin }}\left(y_u, y_u^*, \hat{y}\right)+\mathcal{L}_{\text {hg }}^{\text {bin }}\left(y_u^{\text {aug }}, y_u^{* \text { aug }}, \hat{y}^{\text {aug }}\right) \\ & +\lambda_{\text {con }} \mathcal{L}_{\text {con }}\left(\hat{q}, \hat{q}^{\text {aug }}\right) \end{aligned} Ltotal =Lhg bin (yu,yu∗,y^)+Lhg bin (yuaug ,yu∗ aug ,y^aug )+λcon Lcon (q^,q^aug )
Alleviating catastrophic forgetting
除了能够检测未知对象作为对象外,这个模型还需要在仅训练当前已知类别的注释数据集时克服先前已知类别的遗忘。有许多方法被提出来解决这个问题,包括exemplar replay和knowledge distillation 等。
通过结合上面提到的两种技术可用于减轻先前已知类别的遗忘。具体来说,在每个增量步骤中训练当前已知类别数据集时,应用知识蒸馏到特征和分类输出。此外,存储先前已知类别和当前已知类别的平衡样本集,并在增量步骤后对这些数据进行微调。
更多细节请查阅原始论文,由于篇幅有限,本文不做详细介绍。
Experiments
Benchmark
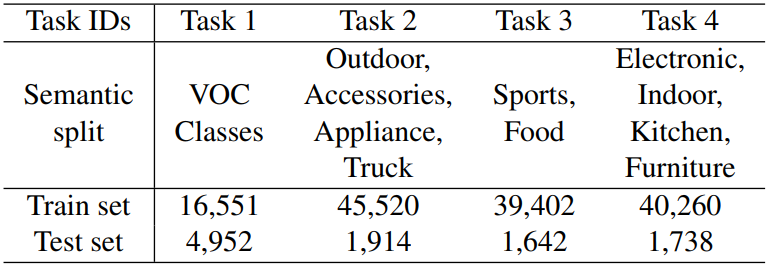
本文在以上四个基准数据集上进行理论验证,同《Open-world detection transformer》(In CVPR, 2022)和《Towards open world object detection》(CVPR2021 Oral)两篇文章的设置保持一致,有兴趣的同学也可以都督这两篇论文。
如上图所示,第一个任务的训练集来自PASCAL VOC,后面三个任务的训练集来自MS-COCO。 来自PASCAL VOC测试集的所有图像和来自MS-COCO的val集的选择图像构成验证集,其中标记了所有以前已知的类和当前已知的类,未知任务的所有类将标记为unknown.
Metrics
对于未知类别,常采用 Unknown Recall, 即U-Recall来衡量模型检索未知实例能力的主要评估指标。此外,除了常规的mAP评估指标,本实验还引入了Wilderness Impact(a.w.a WI)和Absolute Open-Set Error(a.w.a A-OSE)两个评价指标来进一步综合评估所提方法对未知类别和已知类别的效果。
- Wilderness Impact
Wilderness Impact指标用于衡量模型在将未知实例预测为已知类别时的混淆程度,公式如下:
Wilderness Impact ( W I ) = P K P K ∪ U − 1 \text { Wilderness } \operatorname{Impact}(W I)=\frac{P_{\mathcal{K}}}{P_{\mathcal{K} \cup \mathcal{U}}}-1 Wilderness Impact(WI)=PK∪UPK−1
其中, P K P_{\mathcal{K}} PK 和 P K ∪ U P_{\mathcal{K} \cup \mathcal{U}} PK∪U 分别为在已知类别上的precision以及在已知和未知类别并集上的precision,recall取 0.8. 理想情况下,我们希望 WI 等于 0,即当逐渐加入未知类别,在保证召回的情况下,希望精确率越高越好。反言之,如果该指标越大,说明模型无法很好的区分出未知类别。
- Absolute Open-Set Error
A-OSE则是用于衡量检测为已知类的未知实例的总数,即被误分类至已知类别的未知目标的绝对值数量。
- mAP
此处mAP的阈值取 0.5,用于评估模型在引入新类别下的增量学习性能,衡量模型对于已知类别的识别能力。
Implementation details
实验细节是块大头,让我们一看究竟:
- 网络模型:主干为
ResNet-50的Deformable DETR模型。 - 硬件设备:8 *
RTX 3090,每块 GPU 的批次设置为 2。 - 训练阶段:
- 第一阶段基于
ImageNet数据集上以自监督的方式训练初始权重,采用初始学习率为 0.0002 和 权重衰减率为 0.0001 的AdamW优化器;在前50个 epochs 内,学习率在第 40 个 epoch 时衰减 1/10; - 第二阶段采用来自一阶段的权重进行参数初始化,对
binary classification head、class-specific projection layer以及ckassification head这三个部分进行fine-tune的同时冻结其他层的参数;采用的初始学习率为 0.0002 共训练 5 个 epochs,同时在第 3 个 epoch 将学习率降低 1/10; - 损失函数中 λ b c l s \lambda_{b_cls} λbcls 和 λ c o n \lambda_{con} λcon 均设置为 1;
- 其他训练细节同
ORE论文中的参数设置保持一致。
- 第一阶段基于
- 推理阶段:取每张图像的前 50 个得分最高的预测用于模型性能的评估。
Comparison on MS-COCO
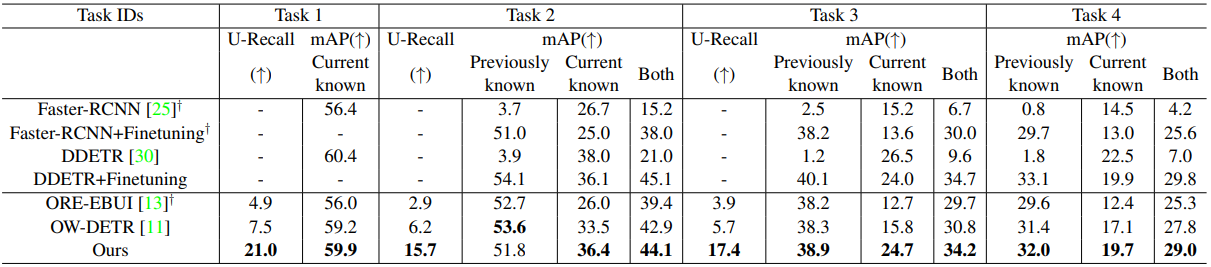

从上述结果可以看出,本文方法的综合性能更强,具有更高准确性和召回率。
Conclusion
本文是继 ORE 和 OW-DETR 后,针对开放世界对象检测场景所提出的一种更加简洁高效的 DETR 目标检测方法。该方法主要涉及到两个阶段,第一阶段训练一个标准的可变性DETR外加接入一个额外的用于前、背景识别的二分类器以构建无偏表示;第二阶段则基于数据增强和增量学习引入了一种多视图自标记策略,通过通过一阶段预训练所得到的二分类器和选择性搜索算法为未知类别生成高质量的伪提议框。同时,通过进一步对对象查询特征实施一致性约束,从而产生更高质量的特征表示。
长远来看,开放世界的目标检测是一个非常值得研究的领域,其在许多应用场景中都具有非常重要的应用价值,如自动驾驶、无人机监控、智能家居等。笔者认为,与其花大把精力在传统的COCO数据集上提高一个百分点,还不如另辟蹊径,解决更具挑战性和更有意义的课题。
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号:cv_huber,一起探讨更多有趣的话题!