专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
专栏链接:
https://blog.csdn.net/qq_39707285/category_11814303.html
此专栏主要介绍RNN、LSTM、Attention、Transformer及其代码实现。
专栏链接:
https://blog.csdn.net/qq_39707285/category_12009356.html
此专栏详细介绍YOLO系列算法,包括官方的YOLOv1、YOLOv2、YOLOv3、YOLOv4、Scaled-YOLOv4、YOLOv7,和YOLOv5,以及美团的YOLOv6,还有PaddlePaddle的PP-YOLO、PP-YOLOv2等,还有YOLOR、YOLOX、YOLOS等。
专栏链接:
https://blog.csdn.net/qq_39707285/category_12184436.html
此专栏详细介绍各种Visual Transformer,包括应用到分类、检测和分割的多种算法。
本章目录
1. 简介
本文提出了一个新的目标检测方法—把目标检测作为直接集合预测问题(即模型直接输出预测框坐标和类别的集合)。这个方法简化了检测流程,去除掉许多手工设计的组件像NMS和anchor等,因为这些组件明显地编码了一些解决任务的先验知识,对于不同的任务需要进行重新的设计。
本文提出的算法名为DEtection TRansformer(DETR),主要有两部分,一种set-based的全局损失(通过二分匹配强制进行唯一预测)和一种Transformer encoder-decoder架构。给定一组固定的小的可学习目标查询(queries),DETR分析目标和全局图像上下文的关系,直接并行输出最终的预测集。与许多其他现代检测算法不同,该算法简单,不需要其他专门的库,详见文末实现代码。
2. 相关知识
构建本算法需要一些领域的知识,包括:集合预测的二分匹配loss、基于Transformer的encoder-decoder结构、并行解码和目标检测方法等。
2.1 Set Prediction(集合预测)
目前许多算法面临的第一个困难是避免near-duplicates(近似的重复),大多数算法采用NMS来处理这个问题,但是直接集预测是无后处理的。集预测需要对所有预测元素之间的交互进行建模以避免冗余的全局推理方案。对于固定大小集预测,密集的全连接网络是足够的,但成本很高。一般的方法是使用自回归序列模型,如递归神经网络。在所有情况下,对于不同的预测排列损失函数都应该保持不变。通常的解决方案是根据匈牙利算法设计损失,找到GT和预测之间的二分匹配。这加强了排列不变性,并确保每个目标元素具有唯一匹配。本文采用二分匹配损失法。然而,与大多数先前的工作相比,本文不再使用自回归模型,而是使用具有并行解码的Transformer。
2.2 Transformer和并行解码
Transformer的介绍可以参考这个文章。Attention机制是从整个输入序列中聚合信息的神经网络层。Transformer引入了self-attention层,类似于非局部神经网络(Non-Local NN),它扫描序列的每个元素,并通过聚合整个序列的信息来更新它。基于注意力的模型的主要优点之一是其全局计算和完美的记忆,这使得它们比RNN更适合长序列。
Transformer首先用于自回归模型,随后是早期的sequence-to-sequence模型,逐个生成输出token。然而,它的推理成本很高(与输出长度成正比,且难以批量处理),本文结合Transformer和并行解码,以在计算成本和执行集合预测所需的全局计算的能力之间进行适当的权衡。
2.3 目标检测
在本文的模型中,去除手工设计的过程,并通过使用相对于输入图像而不是锚点的绝对框预测来直接预测检测集,从而简化检测过程。
-
set-based loss
在早期的深度学习模型中,不同预测之间的关系仅用卷积或完全连接的层建模,手工设计的NMS后处理可以提高其性能。最近的检测器使用GT和预测之间的非唯一分配规则,并使用NMS。
可学习的NMS方法和关系网络明确地对不同预测之间的关系进行了attention建模。它们使用直接集合损失,它们不需要任何后处理步骤。然而,这些方法使用了其他手工设计的上下文特征,如提案框坐标,以有效地建模检测之间的关系,同时本文寻找减少模型中编码的先验知识的解决方案。 -
循环检测器
最接近本文的方法是用于目标检测和实例分割的端到端集合预测。与本文类似,他们使用基于CNN激活的编码器-解码器架构的二分匹配损失来直接生成一组边界框。然而,这些方法只在小数据集上进行了评估,而没有根据现代基准进行评估。特别是,它们基于自回归模型(更准确地说是RNN),因此它们没有利用Transformer进行并行解码。
3. DETR模型
两种组件对于检测中的直接集合预测至关重要:(1)一种集合预测损失,强制预测和GT之间的唯一匹配;(2)预测(在一次传递中)一组目标并对其关系建模的体系结构。整体结构图如下所示:
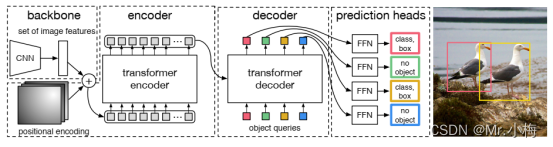
3.1 目标检测集预测loss
DETR在通过解码器的一次传递中推理出N个预测的固定大小集合,其中N显著大于图像中目标的数量。训练的主要困难之一是根据GT对预测目标(类别、位置、大小)进行评分。本文的损失是由预测和GT物体之间产生最佳的二分匹配,然后优化特定目标(边界框)的损失。
用y表示GT目标集合, y ^ = { y ^ i } i = 1 N \hat y = \{\hat y_i\}^N_{i=1} y^={
y^i}i=1N表示预测的集合,N大于图片中目标的数量,用(no object,⊘)y填充使其总数等于N。为了找到这两个集合之间的二分匹配,搜索N个元素的组合 σ ∈ ð N \sigma \in \eth_N σ∈ðN,使其cost最低:
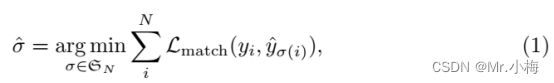
其中 ζ m a t c h ( y i , y ^ σ ( i ) ) \zeta_{match}(y_i,\hat y_{\sigma(i)}) ζmatch(yi,y^σ(i))是GT y i y_i yi和位置为 σ ( i ) \sigma(i) σ(i)的预测之间的成对匹配cost。使用匈牙利算法可以有效地计算该最优分配。
匹配cost同时考虑了类别预测以及预测和GT框的相似性。GT集的每个元素i可以被视为 y i = ( c i , b i ) y_i=(c_i,b_i) yi=(ci,bi),其中 c i c_i ci是目标类标签(可能为⊘),且 b i ∈ [ 0 , 1 ] 4 b_i \in[0,1]^4 bi∈[0,1]4是一个向量,它定义了GT框中心坐标及其相对于图像大小的高度和宽度。对于位置为 σ ( i ) \sigma(i) σ(i)的预测,将 c i c_i ci类的概率定义为 p ^ σ ( i ) ( c i ) \hat p_{\sigma(i)}(c_i) p^σ(i)(ci),预测框为 b ^ σ ( i ) \hat b_{\sigma(i)} b^σ(i)。通过这些符号,定义了 ζ m a t c h ( y i , y ^ σ ( i ) ) \zeta_{match}(y_i,\hat y_{\sigma(i)}) ζmatch(yi,y^σ(i))等于:
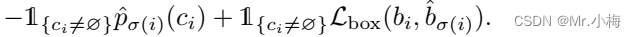
这种寻找匹配的过程与现代检测器中用于将提议框或锚匹配到GT目标的启发式分配规则起着相同的作用。主要区别在于,本文需要找到一对一的匹配,以进行无重复的直接集预测。
第二步是计算损失函数,即前一步匹配的所有pair的匈牙利损失(Hungarian loss)。本文定义的损失类似于普通目标检测器的损失,即用于类别预测的负对数似然和box损失的线性组合:
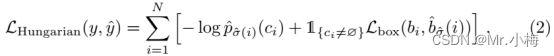
其中 σ ^ \hat \sigma σ^是在第一步中计算的最佳分配(公式1),在实践中,降低对数概率项的权重,把 c i = ⊘ c_i=⊘ ci=⊘的除以10以10以平衡类别。请注意,目标和⊘之间的匹配cost不依赖于预测,这意味着在这种情况下,cost是恒定的。在匹配cost中,使用概率 p ^ σ ( i ) ( c i ) \hat p_{\sigma(i)}(c_i) p^σ(i)(ci)代替对数概率。这使得类预测项与 ζ b o x ( ⋅ , ⋅ ) \zeta_{box}(·,·) ζbox(⋅,⋅)有公度。
Bounding box loss:
匹配cost和匈牙利损失的第二部分是对边界框进行评分的 ζ b o x ( ⋅ ) \zeta_{box}(·) ζbox(⋅)。与许多检测器不同,这些检测器将box预测为∆w.r.t,本文直接进行预测。虽然这种方法简化了实现,但它对损失的相对规模造成了问题。最常用的l1损失对于小box和大box会有不同的尺度,即使它们的相对误差相似。为了缓解这个问题,我们使用l1损失和广义IoU损失的线性组合, ζ b o x ( ⋅ , ⋅ ) \zeta_{box}(·,·) ζbox(⋅,⋅)是尺度不变的。总的来说,损失是 ζ b o x ( b i , b ^ σ ( i ) ) \zeta_{box}(b_i,\hat b_{\sigma(i)}) ζbox(bi,b^σ(i)),定义为:
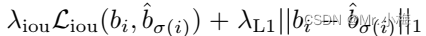
其中 λ i o u , λ L 1 ∈ ℜ \lambda_{iou},\lambda_{L_1} \in \Re λiou,λL1∈ℜ是超参数。这两个损失通过batch内目标的数量进行归一化。
3.2 DETR结构
3.2.1 backbone
输入图片尺寸: x i m g ∈ ℜ 3 × H 0 × W 0 x_{img} \in \Re^{3×H_0×W_0} ximg∈ℜ3×H0×W0通过一个卷积backbone生成一个低分辨率的特征图: f ∈ ℜ C × H × W f \in \Re^{C×H×W} f∈ℜC×H×W,C设置为2048, H , W = H 0 32 , W 0 32 H,W= \frac {H_0}{32},\frac {W_0}{32} H,W=32H0,32W0。
3.2.2 Transformer encoder
首先,1x1卷积将特征图f的通道维度从C减小到更小的维度d,得到一个新的特征图 z 0 ∈ ℜ d × H × W z_0 \in \Re^{d×H×W} z0∈ℜd×H×W,编码器期望一个序列作为输入,因此将z0的空间维度折叠为一维,得到一个 d × H × W d×H×W d×H×W的特征图。每个编码器层都有一个标准架构,由一个multi-head self-attention模块和一个前馈网络(FFN)组成。由于Transformer结构是平移不变的,用固定的位置编码对其进行补充,添加到每个attention层的输入中。
3.2.3 Transformer decoder
解码器遵循Transformer的标准架构,使用multi-head self-attention和encoder-decoder attention机制转换大小为d的N个嵌入。与原始Transformaer不同之处在于,每个解码器层并行解码N个目标,而Vaswani等人使用一个自回归模型,一次预测一个元素的输出序列。由于解码器也是排列不变的,所以N个输入嵌入必须不同才能产生不同的结果。这些输入嵌入是学习的位置编码,称之为目标查询,与编码器类似,将它们添加到每个attention层的输入中。解码器将N个目标查询转换为输出嵌入。然后,通过前馈网络(在下一小节中描述)将它们独立地解码为框坐标和类标签,得到N个最终预测。通过对这些嵌入的self-attention和encoder-decoder attention,该模型使用它们之间的成对关系全局地推理所有目标,同时能够将整个图像用作上下文。
3.2.4 Prediction feed-forward networks (FFNs)
最终预测由具有ReLU激活函数和隐藏维度d的3层感知器和线性投影层计算。FFN预测输入图像框的标准化中心坐标、高度和宽度,线性层使用softmax函数预测类标签。由于预测了一组固定大小的N个边界框,其中N通常比图像中的目标的实际数量大得多,因此需要额外的特殊类标签⊘,用于表示在没有检测到目标时使用。该类在标准目标检测方法中扮演类似于“background”类的角色。
3.2.5 辅助解码损失
本文发现在训练期间在解码器中使用辅助loss是有帮助的,特别是帮助模型输出正确的每个类的目标数字。在每个解码器层之后添加预测FFN和匈牙利损失。所有预测FFN共享其参数。使用额外的共享层规范来规范来自不同解码器层的预测FFN的输入。
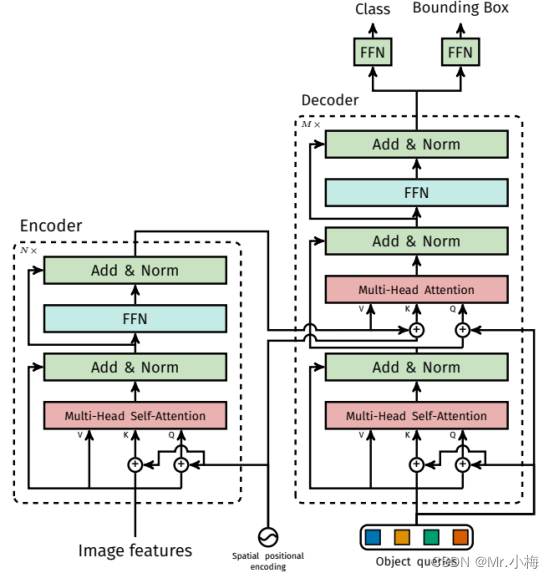
3.3 DETR详细结构
下图给出了DETR中使用的变Transformer的详细描述,以及在每个attention层传递的位置编码。来自CNN backbone的图像特征通过Transformer编码器,连同空间位置编码一起被添加到每个multi-head self-attention层的查询和键中(queries and keys)。然后,解码器接收查询(queries,最初设置为零)、输出位置编码(目标查询)和编码器存储器,并通过多个multi-head self-attention和decoder-encoder attention来生成预测类标签和边界框的最终集合。第一解码器层中的第一个self-attention层可以跳过。
4. 结论
本文提出了DETR,这是一种基于Transformer和用于直接集预测的二分匹配损失的目标检测系统的新设计。该方法在具有挑战性的COCO数据集上实现了与优化的Faster R-CNN相当的结果。DETR易于实现,并且具有灵活的架构,可轻松扩展到全景分割,具有竞争性的结果。此外,与Faster R-CNN相比,它在大型物体上的性能明显更好,这可能得益于self-attention注对全局信息的处理。
这种新设计的检测器也带来了新的挑战,特别是在小物体的训练、优化和性能方面。
5. 实现代码
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads, num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=False).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1), ], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
if __name__ == "__main__":
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
print(logits.shape)
print(bboxes.shape)