如有错误,恳请指出。
paper:End-to-End Object Detection with Transformers
code:https://github.com/facebookresearch/detr

摘要:
paper提出将目标检测问题看作是集合预测问题,简化了检测流程,有效的消除了一些设计需要:如非最大抑制程序或锚生成。DETR是一种基于集合的全局损失,通过双向匹配进行唯一预测,同时也是一种encoder-decoder结构。
实现了给定一个固定大小的query,DETR根据目标对象与全局图像的上下文关系直接并行输出最终的预测集。
其中,paper涉及到了一些transformer的概念,有关transformer的介绍可以查看我另外的两篇博客:
1. Transformer介绍
2. Vit 介绍(Transformer用于分类任务)
1. Introduction
在以往主流的目标检测框架中都是通过对anchor定义代理回归和分类问题来解决检测任务,但是这种方式需要人为自觉的设定anchor相关参数与一些后处理的方法。为此,作者提出DETR,一种直接集预测方法来绕过代理任务,同时使用了transformer结构。
通过将目标检测看作直接集预测问题,简化了训练流程,采用了一种基于transformer的编解码器结构。transformer的自注意机制,显式地建模序列中所有元素之间的成对交互,使这些架构特别适合于特定的集预测约束,如删除重复预测。结构如图1所示:

与以往大多数直接集预测的工作相比,DETR的主要特点是将二部匹配损耗和transformers与(非自回归)并行解码结合起来。相比之下,以前的工作集中于使用rnn的自回归解码。DETR中的匹配损失函数唯一地将一个预测框给一个ground truth对象,并且对预测对象的排列不变。
DETR在大型对象上展示了明显更好的性能,这很可能是由transformers的非局部计算实现的。然而,它在小对象上的性能较低。同时,其需要需要超长的训练时间。
2. Related work
作者的工作建立在以下几个领域:
1)用于集预测的二分匹配损耗
2)基于transformers的编码器-解码器体系结构
3)并行译码
4)目标检测方法
2.1 Set Prediction
在深度学习中,没有特定的结构用于直接集合预测。最典型的集合预测任务当属多标签分类问题,但这类方法不可以直接迁移到目标检测中(目标检测中还需要对目标进行定位)。这类任务中首要问题是重复检测,当前目标检测方法使用的是非极大值抑制。但集合预测不需要后处理,它通过全局推理来预测元素之间的关系。同时,可以使用全连接网络预测固定大小的集合,但同时会带来庞大的计算量。一种可能的解决办法是使用自递归序列模型,如循环神经网络。在这种情况下,损失函数应该对预测目标保持不变,一种解决办法是使用匈牙利算法设计损失函数来唯一匹配预测结果和标注信息。与以往方法不同的是,论文没有采用自回归模型,而是使用了带并行编码器的Transformer模型。
2.2 Transformers and Parallel Decoding
注意机制是神经网络层,从整个输入序列中聚集信息。Transformer引入了自注意层,类似于非局部神经网络,扫描序列的每个元素,并通过从整个序列中聚合信息来更新它。基于注意力的模型的主要优点之一是其全局计算和完美的记忆性,这使得它比rnn更适合长序列。
Transformer首先在自回归模型中使用,遵循早期的序列-序列模型,逐个生成输出tokens。但由于推理成本的限制,以并行的方式产生序列没能得到发展。为此,作者结合了Transformer和并行解码,以便在计算成本和执行集合预测所需的全局计算能力之间进行适当的权衡。
2.3 Object detection
在DETR中,通过直接预测输入图像的检测集,而不是锚框,从而简化检测过程。
一些目标检测器使用了二分匹配损耗。然而,在这些早期的深度学习模型中,不同预测之间的关系仅采用卷积或全连接层建模,而手工设计的NMS后处理可以提高它们的性能。最近的探测器与NMS一起对ground truth和预测值之间使用非唯一的分配规则。使用直接的集合损失,不需要任何后处理步骤。然而,这些方法使用额外的手工上下文特征,如提议框坐标,以高效地建模检测之间的关系。
还有使用基于CNN激活的编码器-解码器架构的两分匹配损失来直接产生一组包围盒的检测器,但是这些方法仅在小数据集上进行评估,而没有参照现代基线,且没有利用并行解码的最新transformers。
3. DETR model
在预测过程中,有两条因素对直接的集合预测至关重要:
1)预测的损失函数确保预测框与真实框的唯一匹配
2)确保检测结构可以预测一组对象且对他们之间的关系建模
DETR的具体结构如图所示:
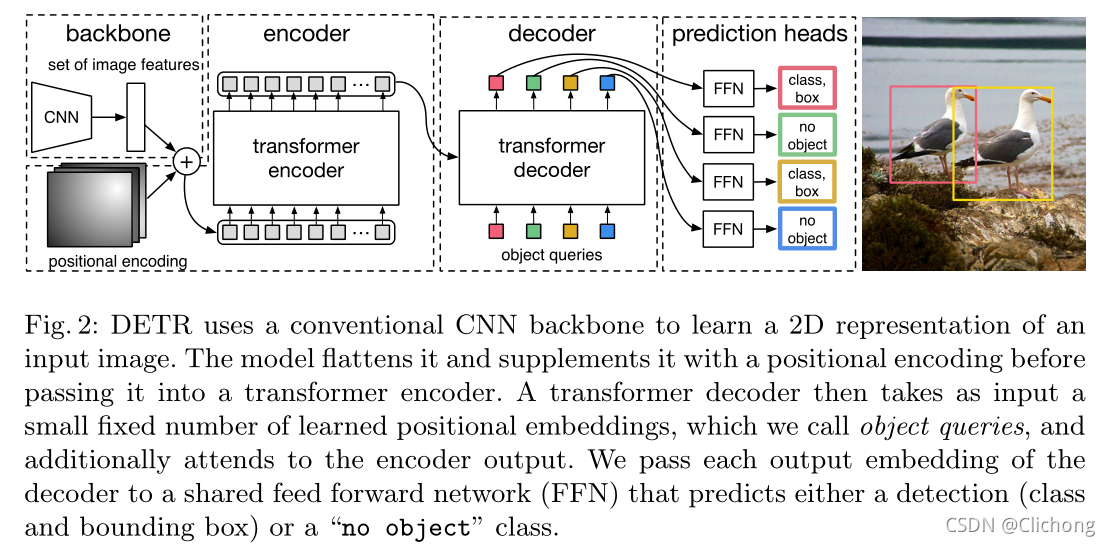
3.1 Object detection set prediction loss
通过解码器的输出,DETR会输出一组N个固定大小的预测,其中N是要比图像中的目标数量要大的。训练的主要难点之一是根据ground truth对预测对象(类别、位置、大小)进行评分。作者提出的损失产生了预测对象和ground truth之间的最佳二分匹配,然后优化特定对象(边界框)的损失。
用 y y y来表示对象的ground true集合,用 y ^ = { y ^ } i = 1 N \hat{y} = \{\hat{y}\}^{N}_{i=1} y^={
y^}i=1N来表示N个预测的集合。假设N的数目是要比一副图像上的对象要多的,其实也可以认为 y y y是一组数目也是N的集合,但是多出来的部分为null,也就是∅(no object)。为了找到这两个集合之间的二分匹配,作者寻找代价最低的n个元素的排列 σ ∈ S N σ∈S_{N} σ∈SN,公式可以表示为:
σ ^ = arg min σ ∈ S N ∑ i N L m a t c h ( y i , y ^ σ ( i ) ) (1) \hat{σ} = \arg \min_{σ\in S_{N}} \sum^{N}_{i}L_{match}(y_{i}, \hat{y}_{σ}(i)) \tag{1} σ^=argσ∈SNmini∑NLmatch(yi,y^σ(i))(1)
其中, L m a t c h ( y i , y ^ σ ( i ) ) L_{match}(y_{i},\hat{y}_{σ}(i)) Lmatch(yi,y^σ(i))表示的是ground truth y i y_{i} yi与预测框 σ i σ_{i} σi之间的成对匹配代价。其中匈牙利算法有效地计算了这种最优分配。
匹配代价既考虑了类预测,也考虑了预测框和ground true的相似性。其中ground true集合中的每个成员都可以看成是 y i = ( c i , b i ) y_{i} = (c_{i}, b_{i}) yi=(ci,bi),其中 c i c_{i} ci表示目标类别(可能是null,也就是没有目标对象);而 b i ∈ [ 0 , 1 ] 4 b_{i} \in [0, 1]^{4} bi∈[0,1]4是定义ground truth中心坐标及其相对于图像大小的高度和宽度的向量。而对于预测的边界框 σ i σ_{i} σi,定义其类别概率为: p ^ σ ( i ) ( c i ) \hat{p}_{σ(i)}(c_{i}) p^σ(i)(ci) ,定义其预测框坐标为: b ^ σ ( i ) \hat{b}_{σ(i)} b^σ(i)。利用这些符合,定义成对匹配代价函数为:
L m a t c h ( y i , y ^ σ ( i ) ) = − 1 { c i = ∅ } p ^ σ ( i ) ( c i ) + 1 { c i ≠ ∅ } L b o x ( b i , b ^ σ ( i ) ) (2) L_{match}(y_{i},\hat{y}_{σ}(i)) = -1_{\{c_{i}=∅\}}\hat{p}_{σ(i)}(c_{i})+1_{\{c_{i}≠∅\}}L_{box}(b_{i},\hat{b}_{σ(i)}) \tag{2} Lmatch(yi,y^σ(i))=−1{
ci=∅}p^σ(i)(ci)+1{
ci=∅}Lbox(bi,b^σ(i))(2)
这种寻找匹配的过程与现代探测器中用于匹配提议或锚点到ground true的启发式分配规则相同。主要的区别是,需要找到一对一的匹配来进行没有重复的直接集预测。
第二步是计算损失函数,即前一步中匹配的所有配对的匈牙利损失。这里作者对损失的定义类似于普通检测器的损失,即类预测的负对数似然和后面定义的边界框损失的线性组合:
L H u n g a r i a n ( y , y ^ ) = ∑ i = 1 N [ − log p ^ σ ^ ( i ) ( c i ) + 1 { c i ≠ ∅ } L b o x ( b i , b ^ σ ( i ) ) ] (3) L_{Hungarian}(y,\hat{y}) = \sum^{N}_{i=1} [-\log \hat{p}_{\hat{σ}(i)}(c_{i})+1_{\{c_{i}≠∅\}}L_{box}(b_{i},\hat{b}_{σ(i)})] \tag{3} LHungarian(y,y^)=i=1∑N[−logp^σ^(i)(ci)+1{
ci=∅}Lbox(bi,b^σ(i))](3)
其中, σ ^ \hat{σ} σ^是公式(1)中计算的最优分配计算。在实践中,作者对对数概率 c i = ∅ c_{i} = ∅ ci=∅的释然函数项进行了10倍减重,以解释阶级不平衡。这类似于Faster R-CNN训练程序如何通过子采样来平衡正/负候选框。注意,对象和∅之间的匹配成本并不取决于预测,这意味着在这种情况下,成本是一个常数。(第一项中由于某些标注信息集合内的 c i = ∅ c_{i} = ∅ ci=∅,所以该部分的分类损失为定值。
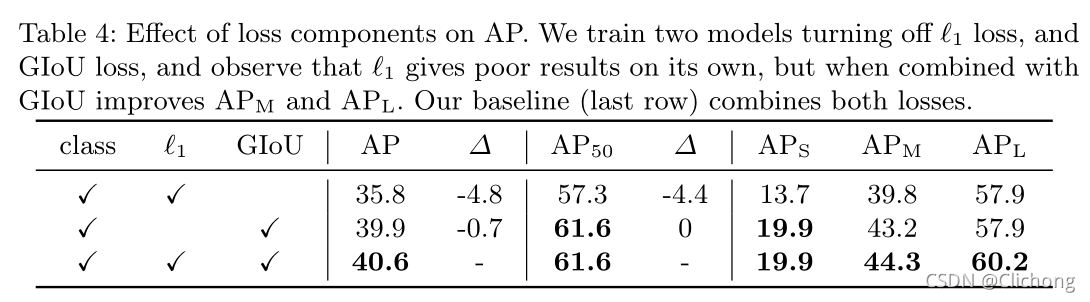
对于回归损失项,以前的目标检测算法的回归目标大都是预测值相对于标注信息的偏移,而文中使用的是直接回归的方式。虽然这种方法简化了实现,但它提出了一个相对缩放损失的问题。最常用的 l 1 l o s s l1 loss l1loss对于大盒和小盒有不同的刻度,即使它们的相对误差是相似的。为了缓解这个问题,DETR的回归损失结合了 l 1 l_{1} l1损失与 G I o U GIoU GIoU损失。为此,边界框损失定义为:
L b o x ( b i , b ^ σ ( i ) ) = λ i o u L i o u ( b i , b ^ σ ( i ) ) + λ L 1 ∣ ∣ b i − b ^ σ ( i ) ∣ ∣ (4) L_{box}(b_{i},\hat{b}_{σ(i)}) = \lambda_{iou}L_{iou}(b_{i},\hat{b}_{σ(i)}) + \lambda_{L_{1}}||b_{i} - \hat{b}_{σ(i)}|| \tag{4} Lbox(bi,b^σ(i))=λiouLiou(bi,b^σ(i))+λL1∣∣bi−b^σ(i)∣∣(4)
其中, λ i o u \lambda_{iou} λiou与 λ L 1 \lambda_{L_{1}} λL1分别是各自的超参数。这两个损失是根据批处理中对象的数量规范化的。
3.2 DETR architecture
总体的DETR体系结构非常简单。它包含三个主要组成部分,在下面描述:一个CNN主干提取一个紧凑的特征表示,一个编码器-解码器转换器,和一个简单的前馈网络(FFN),进行最终的检测预测。
DETR可以在任何深度学习框架中实现,该框架提供了一个通用的CNN主干和一个只有几百行代码的转换器架构实现,在PyTorch中,用不到50行代码就可以实现用于DETR的推理代码。
3.2.1 Backbone
初始的输入图像大小为: x i m g ∈ 3 × H 0 × W 0 x_{img} \in 3 \times H_{0} \times W_{0} ximg∈3×H0×W0,通过一个CNN的主干网络提取一个低分辨率的特征图: f ∈ C × H × W f \in C \times H \times W f∈C×H×W,其中 C = 2048 C = 2048 C=2048, H 、 W = H 0 32 、 W 0 32 H、W = \frac{H_{0}}{32}、\frac{W_{0}}{32} H、W=32H0、32W0。
3.2.2 Transformer encoder
首先,一个1x1的卷积层将一个高层特征图 f ∈ C × H × W f \in C \times H \times W f∈C×H×W的channels数 c c c降维成 d d d,变成一个新的特征图 z 0 ∈ d × H × W z_{0} \in d \times H \times W z0∈d×H×W。编码器需要一个序列作为输入,因此这里将 z 0 z_{0} z0的空间维度压缩为一维,从而得到 d × H W d×HW d×HW的特征映射。每个编码器层都有一个标准的结构,由一个多头自注意模块(multi-head self-attention)和一个前馈网络(feed forward network ,FFN)组成。由于transformer体系结构是置换不变的,用固定位置编码对其进行补充,并将其添加到每个注意层的输入中。
ps:输入图像被分批处理在一起,充分应用0-padding以确保它们都具有相同的尺寸 ( H 0 , W 0 ) (H_{0}, W_{0}) (H0,W0)作为批处理中最大的图像。
3.2.3 Transformer decoder
解码器遵循transformer的标准结构,使用多头自注意力机制和编码器-解码器变换N个尺寸为d的嵌入。与原始transformer的不同之处在于,DETR模型在每个解码器层并行解码N个对象,而Vaswani等人使用Autoregressive模型,每次预测一个元素的输出序列。由于解码器也是置换不变的,因此输入嵌入必须不同才能产生不同的结果。这些输入嵌入是我们称之为object queries的学习位置编码,与编码器类似,我们将它们添加到每个注意层的输入中。
所以N个object queries在解码器中会被转换成N个output embedding。然后通过前馈网络将它们独立解码为框坐标和类标签,从而得出最终的预测。使用自注意力机制作用于这些embedding上,模型利用它们之间的成对关系对所有对象进行全局推理,使得可以使用整副图像作为上下文。
3.2.4 Feed-forward networks
最后的预测是由一个带有ReLU激活函数和隐藏维数的3层感知器和一个线性投影层来计算的。FFN预测输入图像的归一化中心坐标、框的高度和宽度,线性层使用softmax函数预测类标签。由于我们预测一个固定大小的N个包围盒集合,其中N通常比图像中感兴趣的物体的实际数量大得多,所以使用额外的特殊类标签∅来表示槽内未检测到物体。这个类在标准对象检测方法中扮演着类似于背景类的角色。
3.2.5 Auxiliary decoding losses
辅助损耗在帮助模型输出正确的类的对象数量的时候比较有帮助。在每一层解码器后加入预测FFN层和匈牙利损耗。所有预测FFN共享它们的参数,然后使用一个额外的共享层范数对来自不同解码器层的预测FFN输入进行归一化。
3.3 Overall process
这里回顾一些整个DETR的总体流程:
- 首先使用CNN对图像进行一个特征提取,得到一个预测特征图
- 对预测特征图的channel进行降维,然后 d × H W d×HW d×HW的特征映射,与Vit模型类似,将其变成N个维度为d的序列信息(所以变成一堆 d × H W N d \times \frac{HW}{N} d×NHW)的embedding块
- 将N个embedding添加上位置编码,丢入到Encoder中,得到处理后的N个embedding块
- 再将这些输出丢到Decoder中,然后一次性直接输入N个object queries学习位置编码。由于不是自回归机制,所以Decoder会根据这N个object queries输出N个output embedding
- 对于每一个output embedding,分别使用一个前馈神经模块进行类预测与边界框预测
- 这里的output embedding不是每一个都能预测出一个边界框,会出现为∅的情况,此时就便是为没有目标对象,将全部的output embedding的预测框展现出来,就完成了全部对象的目标检测
ps:预测过程遇上所示,而对于训练过程来说,也是类似,不是复杂了一点。通过二分匹配计算损失来不断训练。而在3.1节已经介绍过了,训练的主要难点之一是根据ground truth对预测对象(类别、位置、大小)进行评分。作者提出的损失产生了预测对象和ground truth之间的最佳二分匹配,然后优化特定对象(边界框)的损失。
简单来说,就是对于每个FFN的输出,为每一个对象找到一组最匹配的σ(难点,二分匹配解决),那么真实对象 y i y_{i} yi就与 y ^ σ ( i ) \hat{y}_{σ}(i) y^σ(i)进行唯一匹配了。而匹配之后,再计算出全部匹配后的分类损失与边界框回归损失(这里的边界框回归损失是 l 1 l1 l1损失与 I o u Iou Iou损失的权重和)。
ps:这里在16个V100 GPU上训练300个epoch的基线模型需要3天,每个GPU 4张图像(总批大小为64),没得玩…
4. Result
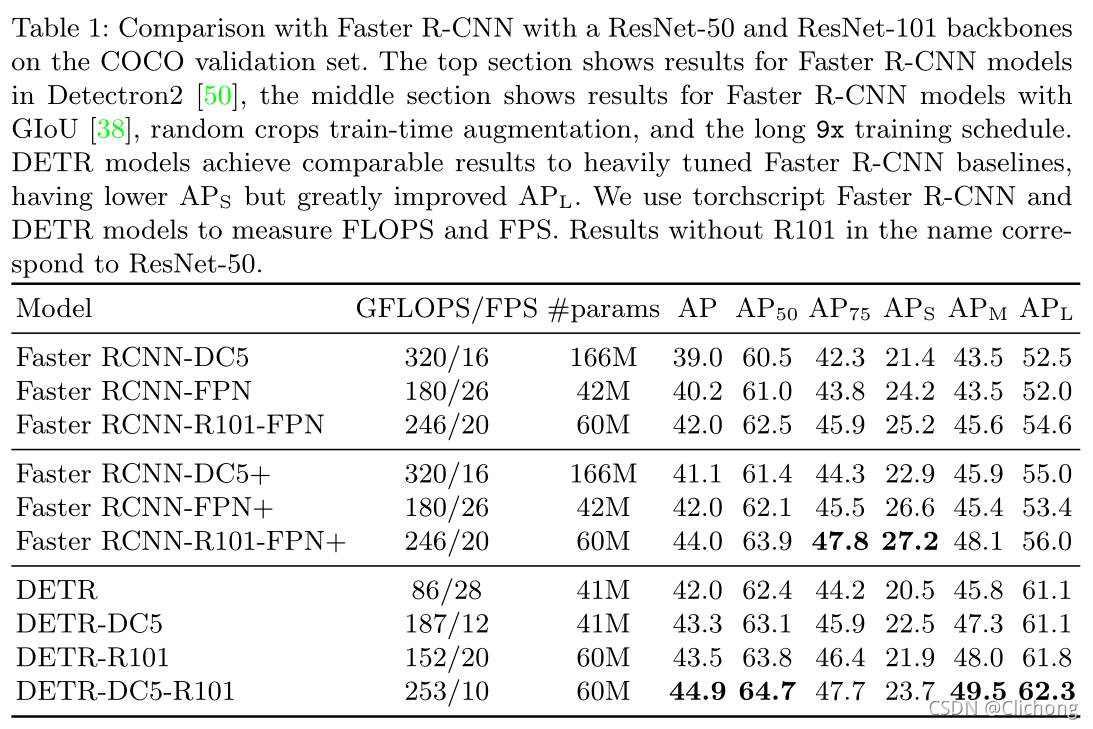
- 与Faster-RCNN的对比:
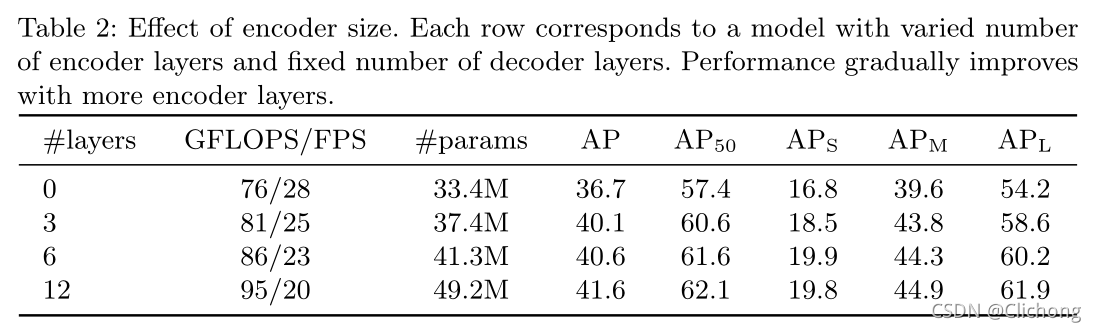
- Encoder层数的影响:
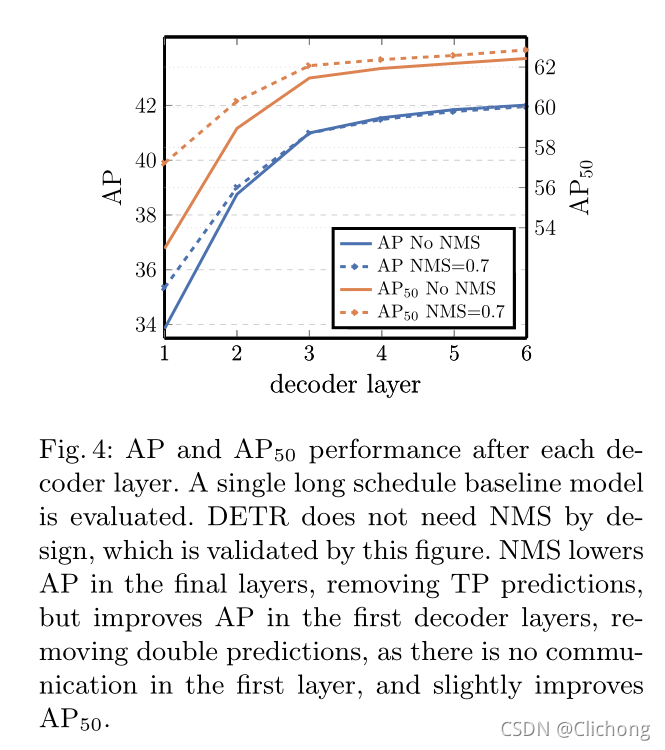
- Decoder层数的影响:
- l 1 l1 l1与 G I o U GIoU GIoU叠加进行边界框回归损失的作用:
总结:
提出了一种新的基于transformers和二分匹配损耗的直接集预测目标检测系统DETR。与Faster R-CNN相比,它在大物体上的表现要好得多,这可能要归功于自注意机制对全局信息的处理。这种探测器的新设计也带来了新的挑战,特别是在小物体的训练、优化和性能方面。
论文的关键是将特征输入Transformer后依旧要保持目标的位置信息以及最后通过合适的方法将预测结果同标注信息匹配。