在编程中遇到了with torch.no_grad()用法,想整明白,过程中有一些意料之外的东西,故此记录一下。
首先说明一下环境,以下的测试均在:python3.6, pytorch1.2.0 环境下给出:
官网的截图如下:
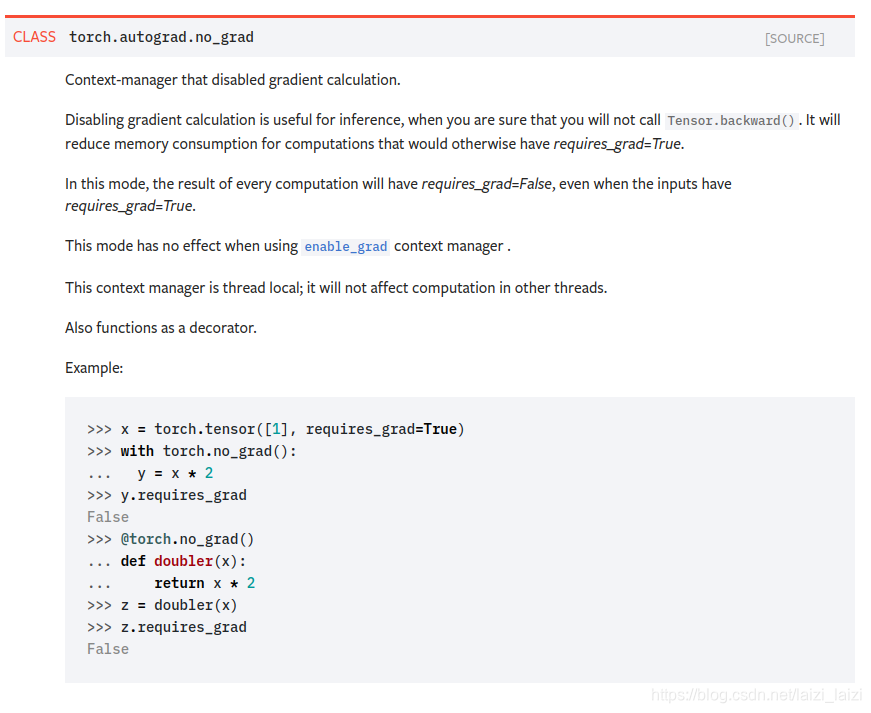
主要有几个重要的点:
- torch.no_grad上一个上下文管理器,在你确定不需要调用
Tensor.backward()时可以用torch.no_grad来屏蔽梯度计算 - 在被torch.no_grad管控下计算得到的tensor,它的requires_grad就是False
下面就通过几个计算图由浅入深的模拟一下我的思路过程:
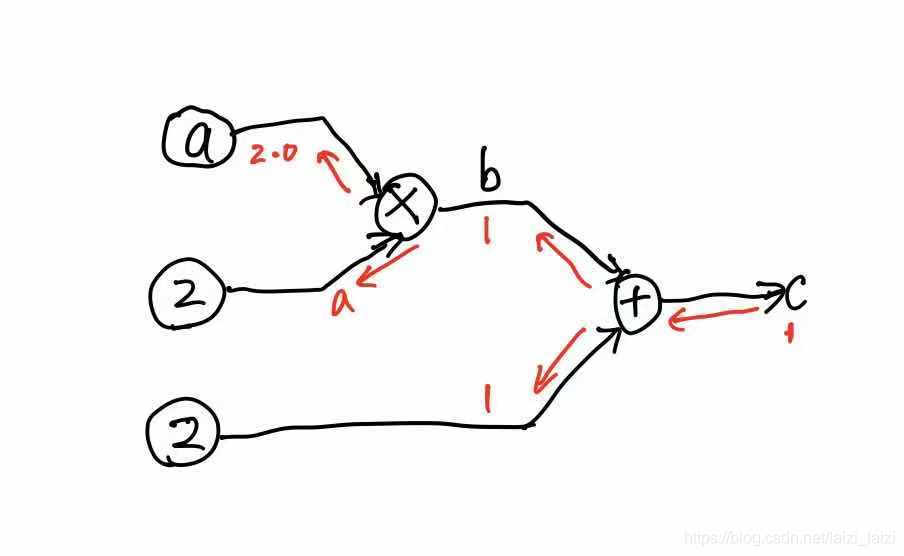
1.首先是最简单的,也是符合预期的
import torch
a = torch.tensor([1.1], requires_grad=True)
b = a * 2
print(b)
c = b + 2
print(c)
c.backward()
print(a.grad)
###answer
tensor([2.2000], grad_fn=<MulBackward0>)
tensor([4.2000], grad_fn=<AddBackward0>)
tensor([2.])
可以看到tensor b和c都被记录了grad_fn,说明他们requires_grad都是True的,并且c 反向传播后,a的梯度就是2.0【注意不是2,一般梯度tensor的类型都是torch.float32,不是整型的】
稍微改动一下,看一下with torch.no_grad()发挥的功能:
import torch
a = torch.tensor([1.1], requires_grad=True)
b = a * 2
print(b)
with torch.no_grad():
c = b + 2
print(c)
print(c.requires_grad)
c.backward()
print(a.grad)
### answer
tensor([2.2000], grad_fn=<MulBackward0>)
tensor([4.2000])
False
可以看到在with torch.no_grad()包裹下, tensor c已经不再有grad_fn,即梯度不被跟踪,且requires_grad是False。这时用c.backward()就会报错:RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
2. 至此官网的内容差不多了,但是自己又想如果tensor c参与运算,那之后的tensor反向传播时,传到c这里会发生什么
所以就有了下面的计算图和下面的代码:
import torch
a = torch.tensor([1.1], requires_grad=True)
b = a * 2
print(b)
with torch.no_grad():
c = b + 2
print(c)
print(c.requires_grad)
d = torch.tensor([10.0], requires_grad=True)
e = c * d
print(e)
print(e.requires_grad)
e.backward()
print(a.grad)
### answer
tensor([2.2000], grad_fn=<MulBackward0>)
tensor([4.2000])
False
tensor([42.], grad_fn=<MulBackward0>)
True
None
可以看到神奇的事发生了,requires_grad为False的c和requires_grad为True的d运算后得到的tensor e它的requires_grad为True,那我就让e进行backward,看看a会有什么梯度,结果发现是None,这就”出错了“,所以官网说只在不需要backward时才用with torch.no_grad(),否则某些tensor的梯度就会出现预期之外的情况
分析一下:因为c这里梯度不再追踪了,相当于上游梯度传到这里就被阻隔了,所以a也不知道该有什么梯度,就抛出None.

3. 让a有另外的一条路径
既然从c来的梯度被阻隔了,那我让a参与另外的运算,多出一条路径,这时a的梯度会是怎样的?于是就有了下面的计算图和代码:
import torch
a = torch.tensor([1.1], requires_grad=True)
b = a * 2
print(b)
with torch.no_grad():
c = b + 2
print(c)
print(c.requires_grad)
d = torch.tensor([10.0], requires_grad=True)
e = c * d
print(e)
print(e.requires_grad)
f = a + e
print(f)
f.backward()
print(a.grad)
### answer
tensor([2.2000], grad_fn=<MulBackward0>)
tensor([4.2000])
False
tensor([42.], grad_fn=<MulBackward0>)
True
tensor([43.1000], grad_fn=<AddBackward0>)
tensor([1.])
可以看到f的梯度从另一条路径传到了a,但显然已经不是我们想要的梯度了。

总结
这里总结一下注意点:
- 1.只要是requires_grad=True的量,他必须是浮点数,不能为整数,grad也是,否则会有这样的报错:
RuntimeError: Only Tensors of floating point dtype can require gradients - 2.在使用with torch.no_grad()时,虽然可以少计算一些tensor的梯度而减少计算负担,但是如果有backward的时候,很可能会有错误的地方,要么很确定没有backward就可以用,要么在显卡允许的情况下就不用with torch.no_grad(),以免出现不必要的错误
- 3.经实验,in place操作即使被包在with torch.no_grad()下,它也还是有grad_fn的,可见下面的例子:
import torch
a = torch.tensor([1.1], requires_grad=True)
b = a * 2
with torch.no_grad():
b.mul_(2)
print(b)
b.backward()
print(a.grad)
### answer
tensor([4.4000], grad_fn=<MulBackward0>)
tensor([2.])