一个torch基础问题,闲来无事想写写。
无论是否使用with torch.no_grad()还是.requires_grad == False,一般来说是不会影响算法本身的,但是会影响代码性能。
with torch.no_grad()
在这个下面进行运算得到的tensor没有grad_fn,也就是它不带梯度(因为没有上一级的函数),因此loss无法从这些tensor向上传递,产生这些tensor的网络的参数将不会更新。下面这种情况一般使用with torch.no_grad():

这里我们只是使用了net2的输出来计算loss,而不想让loss去更新net2的网络参数,于是使用with torch.no_grad(),这样loss就被阻断了在loss.backward过程中,而net1却正常计算网络参数梯度。如果没有使用with torch.no_grad(),也无妨,只是对net2的参数费时地计算了梯度,但是在optimizer.step的时候只有net1的参数step了。另外这也解释了为何更新前要optimizer.zero_grad,如果你像上面说的那样没有no_grad,net2的网络参数有梯度,在之后有backward了一次loss,将导致梯度叠加,也许这不是我们想要的结果(当然也有这样叠加梯度的,往往需要retain_graph==True)。
.requires_grad == False
下面这个例子可以使用:
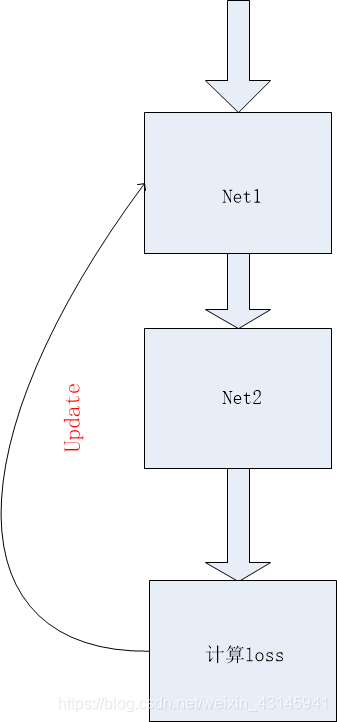
这里我们只想通过loss更新net1,net2不想更新,还能通过with torch.no_grad()实现吗?答案是否定的,一旦使用就阻断了loss流动,那怎么办?如下:
for p in net2.parameters():
p.requires_grad = False
这样不在去计算net2的网络权重w的梯度,而只是使用它的值去计算net1的梯度,提高了代码性能。