摘要
本文将介绍generic object detection的一些检测基准数据集(也称detection benchmarks)。
概念补充:
benchmark:其中文名叫基准。我认为benchmark是用于某行业中比较不同科研成果的一个标准,可以让某项科研成果具体带来的性能提升更为普遍的理解。在目标检测领域,benchmark就包括了数据集和评价指标,科研人员将科研成果在基准数据集上测试,然后按一个通用的指标来衡量这项工作,从而得知工作是否进步或是有什么进步。
baseline:有时论文中我们会看见baseline一词,通常指代其他论文提出的方法。所以我的理解是在以benchmark data做的实验中,测试A B C D四个模型,然后以结果最差的一个模型,假设是C,作为baseline,看看其他模型相对C提高了多少。
一、通用目标检测的基准
1.1基准数据集
-
Pascal VOC2007 是一个目标检测中一个中等规模的数据集,共有20个类别。其数据分为三部分:训练、验证和测试,每部分分别包含 2501, 2510 和 5011张图片。
-
Pascal VOC2012是一个用于对象检测的中型数据集,与Pascal VOC2007拥有相同的20个类别。其数据分为三部分:训练、验证和测试,每部分分别包含5717、5823和10991张图像。VOC2012测试集没有标注信息(annotation)。VOC数据集的详细介绍可以看我的另一篇文章。目标检测数据集PASCAL VOC笔记
-
MSCOCO 是具有80个类别的大规模数据集。其数据分为三部分:训练、验证和测试,每部分分别包含 118287, 5000 和 40670张图片。其测试数据集没有标注信息。
-
Pascal Open Images 包含1.9M图像,1500万个对象,600个类别。其中500个频率最大的种类用做目标检测基准,这500个种类中超过70%的有1000个以上的样本数量。
-
LVIS是一个新收集的基准,包含164000张图像和1000多个类别。
-
ImageNet 也是一个拥有200个类别的重要数据集。然而景观其规模很大,但是目标的尺度范围和VOC数据集相似,所以通常不用做目标检测的基准数据集。但是目标检测模型的backbone却仍在大量采用使用ImageNet预训练好的模型。
以上数据集样本示例:

1.2 评估指标:
目标检测算法使用检测准确度和推断时间作为评估指标。
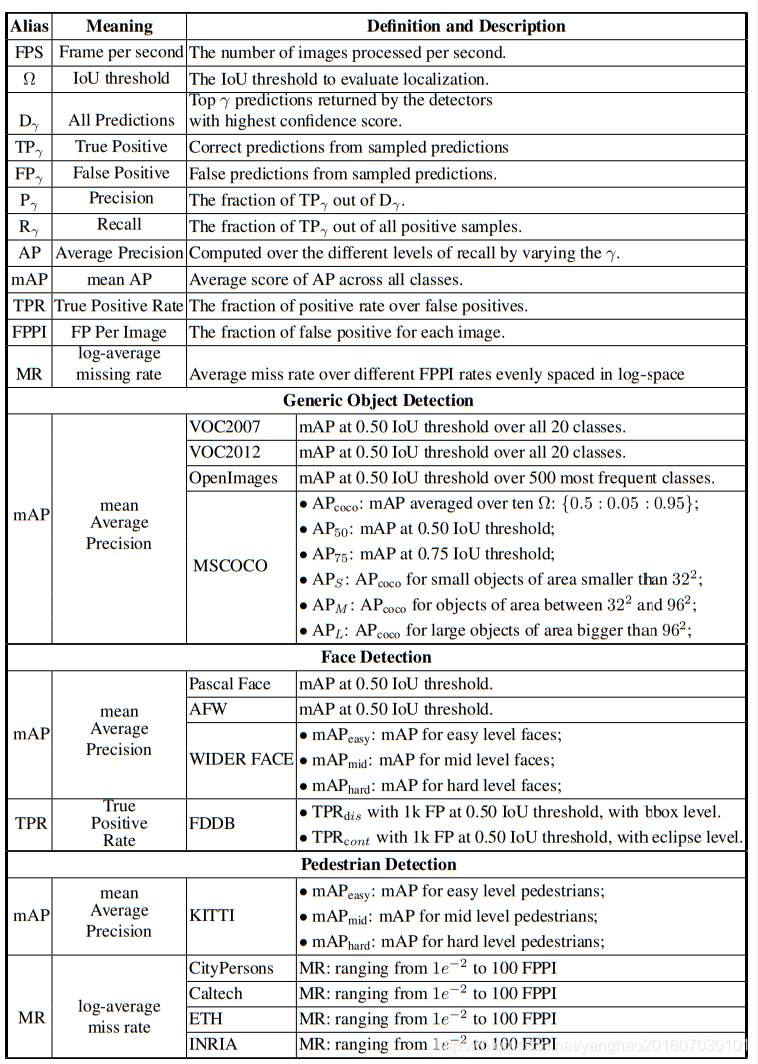
对于检测准确度,使用mean Average Precision(mAP)作为这些基准数据集上的评估指标。对于VOC2012、VOC2007和ImageNet, mAP的IoU阈值设置为0.5,而MSCOCO则采用了更为综合的评估指标,共有6种评估得分,对应其在不同IoU阈值和不同目标尺度上的评价指标。具体可以参考下表.
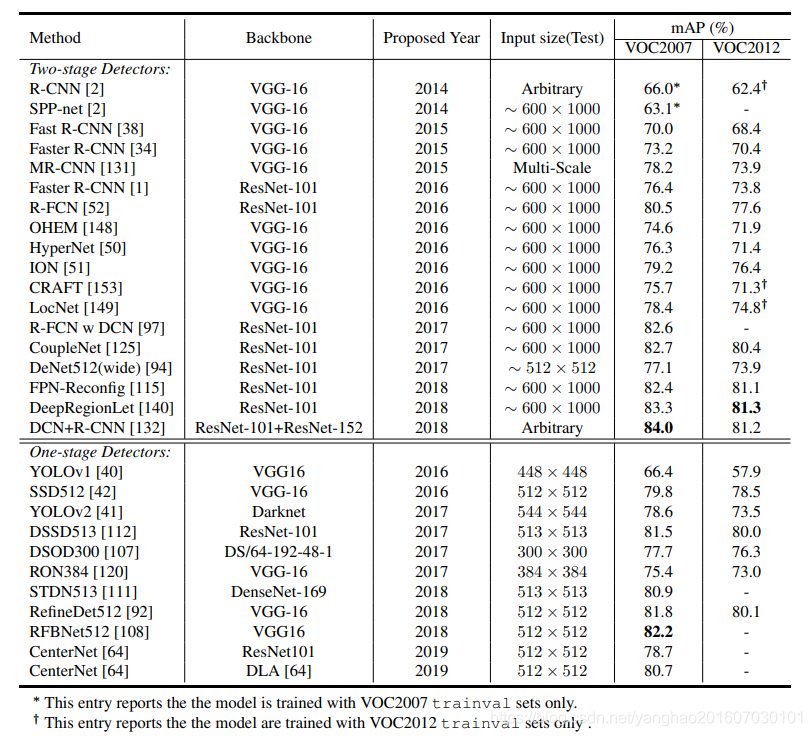
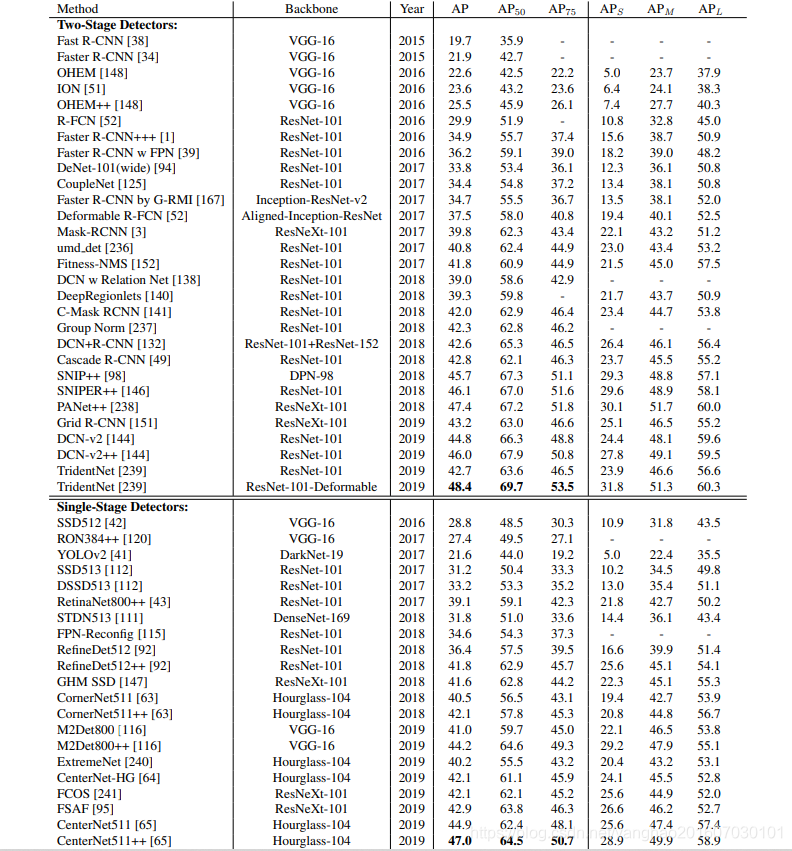
Pascal VOC2007、VOC2007和MSCOCO是评价检测算法最常用的三个数据集。
Pascal VOC2012和VOC2007的每幅图像有2 - 3个目标的中尺度数据集,VOC数据集中目标的大小范围不大。对于MSCOCO来说,每幅图像都有近10个目标,而且大多数目标都是大尺度范围的小目标,这给检测算法带来了很大的挑战。在表3和表2中,我们给出了VOC2007、VOC2012和MSCOCO在最近几年的基准。