摘要
本文介绍构建bug benchmark suite BugBench的过程.
- 选择有代表性bug benchmark的标准
- 选择收集有bug的应用
- 初步研究这些应用和bug的特征
- 在benchmark上评价已有的bug检测工具
1 介绍
1.1 动机
研究者需要一个统一的研究方法展示检测工具的好坏.
构建benchmark增强了社区内的合作, 帮助社区对于面临的问题形参共识.
1.2 我们的工作
开源本文收集的bug应用到研究者社区.
- bug benchmark的挑选标准和评价指标
BugBench: c/c++ bug benchmark suit- 在benchmark和bug特征上进行初步研究
- 初步评价已有工具
2 已有工作的经验
2.1 其他领域的Benchmark
- SPEC: Standard Performance Evaluation Cooperative.
- 候选项目在各自的领域有广泛的使用
- 候选项目在不同架构平台上测试可移植性
- TPC: Transaction Processing Council. 用于比较数据库管理系统. 与SPEC类似, TPC要求项目有代表性, 多样性和可移植性.
2.2 软工和Bug检测领域的已有Benchmark
- CppETS: 用于逆向工程. 提供一系列cpp程序, 每个关联一个问题文件. 每个检测工具需要回答问题, 然后计算得分. 这个得分代表了检测工具的性能.
- Siemens benchmark: 用于bug检测.
- PEST: 用于软件测试.
越好的测试工具能够检测更多的bug版本. 尽管这些benchmark suites提供了很大的bug池, 但是许多bugs只是语义相关的bugs. 与内存相关和多线程相关的bugs几乎不存在. 此外, 这些benchmark应用的项目非常小, 有些甚至少于100行代码.
最近, IBM Haifa提出构建一个多线程程序的benchmark. 但是效果不好, 因为他们依赖于学生故意生成有bug的程序, 而不是使用真实的bug.
3 Benchmark构建指南
3.1 软件bug的分类
-
内存相关bug
- buffer overflow: 非法获取超过buffer范围
- stack smashing: 非法重写函数返回地址
- Memory leak: 动态分配的内存没有引用它的指针, 但是这块空间没有被释放
- uninitialized read: 在初始化之前读取内存数据
- double free: 一块内存释放了两次
-
并发bug
- data race bugs: 并发线程之间对于共享数据的冲突访问
- atomicity-related bugs: 一个线程上的一系列操作被另一个线程的冲突操作中断
- deadlock: 多个进程争夺多个资源
-
语义bug
检测这些信息往往需要语义信息
3.2 bug检测工具的分类
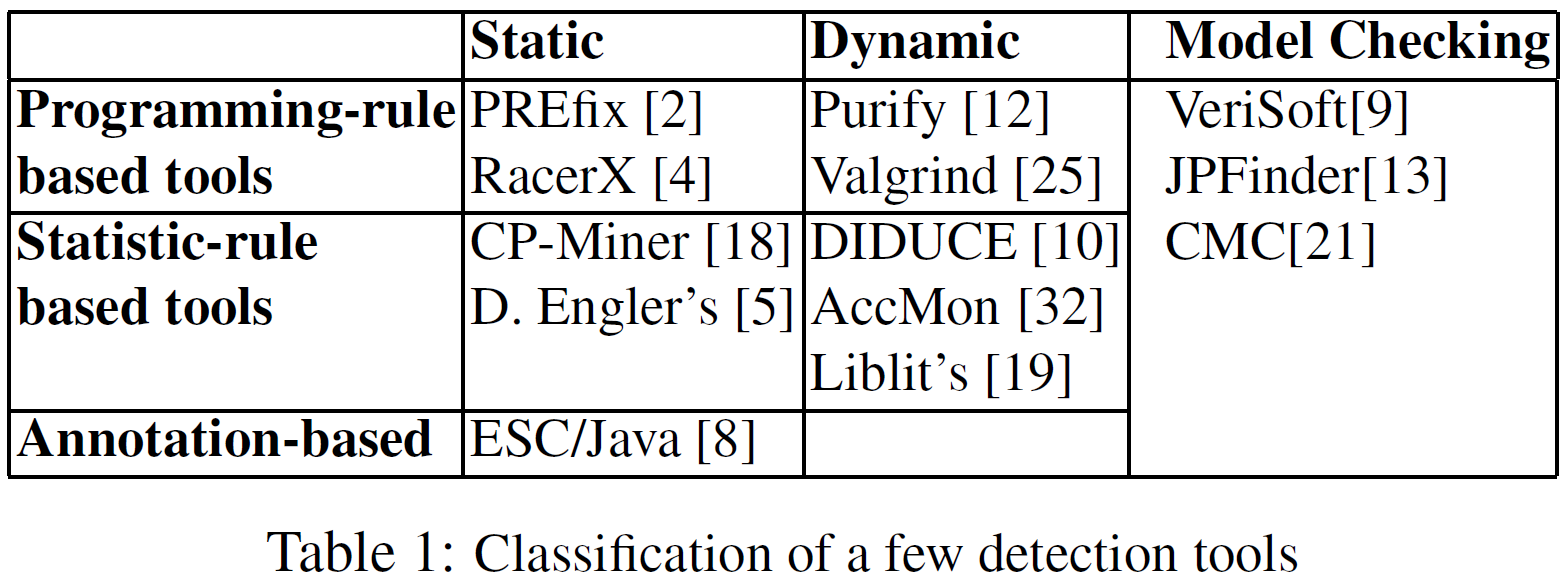
- Programming-rule based tools: 使用编程时必须遵循的规则, 如: 数组指针不能越界
- statistic-rule based tools: 从成功运行的程序中学习统计正确的规则
- annotation-based: 使用annotations进行语法检查
3.3 Benchmark选择标准
- 有代表性: 能够代表真实的bug应用.
- 多样性: bug类型多, bug的复杂性, 动态运行特征
- 可移植性
- 可获取性/可访问性
- 公平: 不偏向于某个具体的检测工具
3.4 评价指标
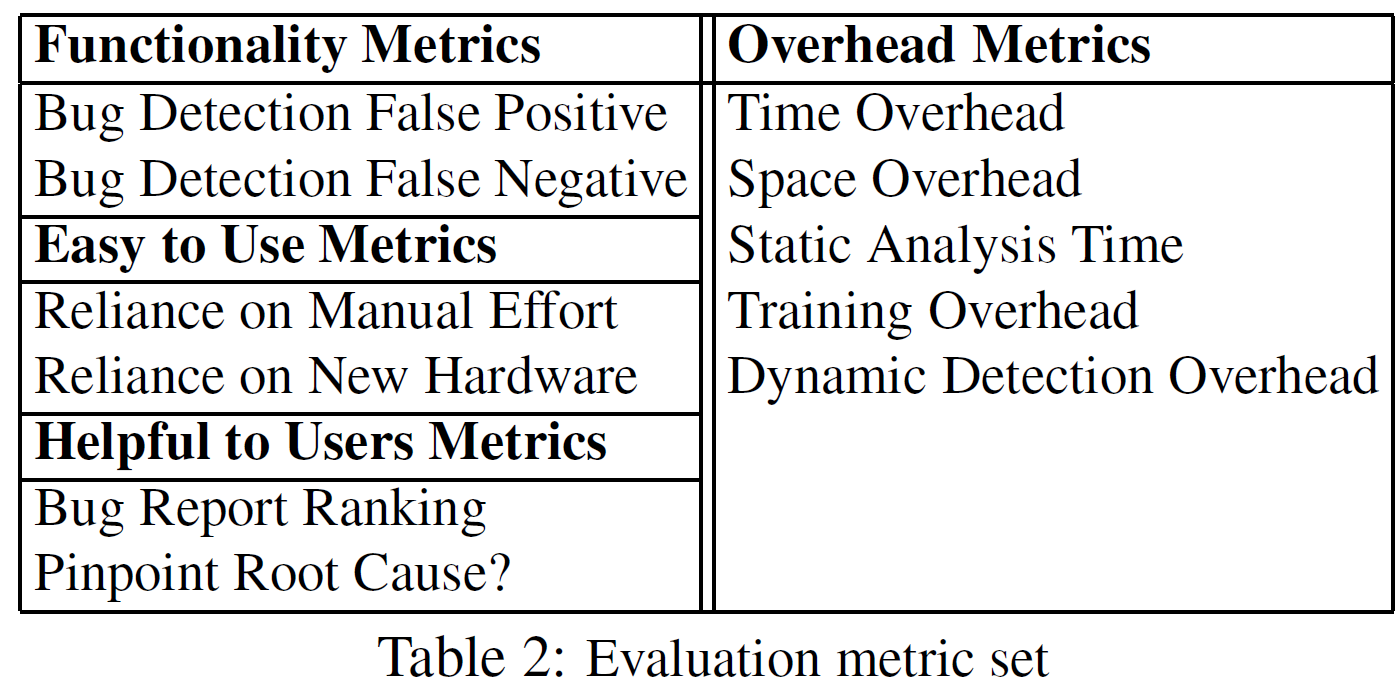
大多数度量评价数量, 如pinpoint root cause, 就是通过从bug root cause到检测到bug位置的距离来量化.
不同类型的工具使用不同的指标. 如静态工具只考虑static analysis time, 动态工具考虑training overhead和dynamic detection overhead.
4 Benchmark
4.1 Benchmark Suite
收集17个存在bug的项目, 13个包含内存相关bug, 4个包含并发bug, 2个包含语义bug.
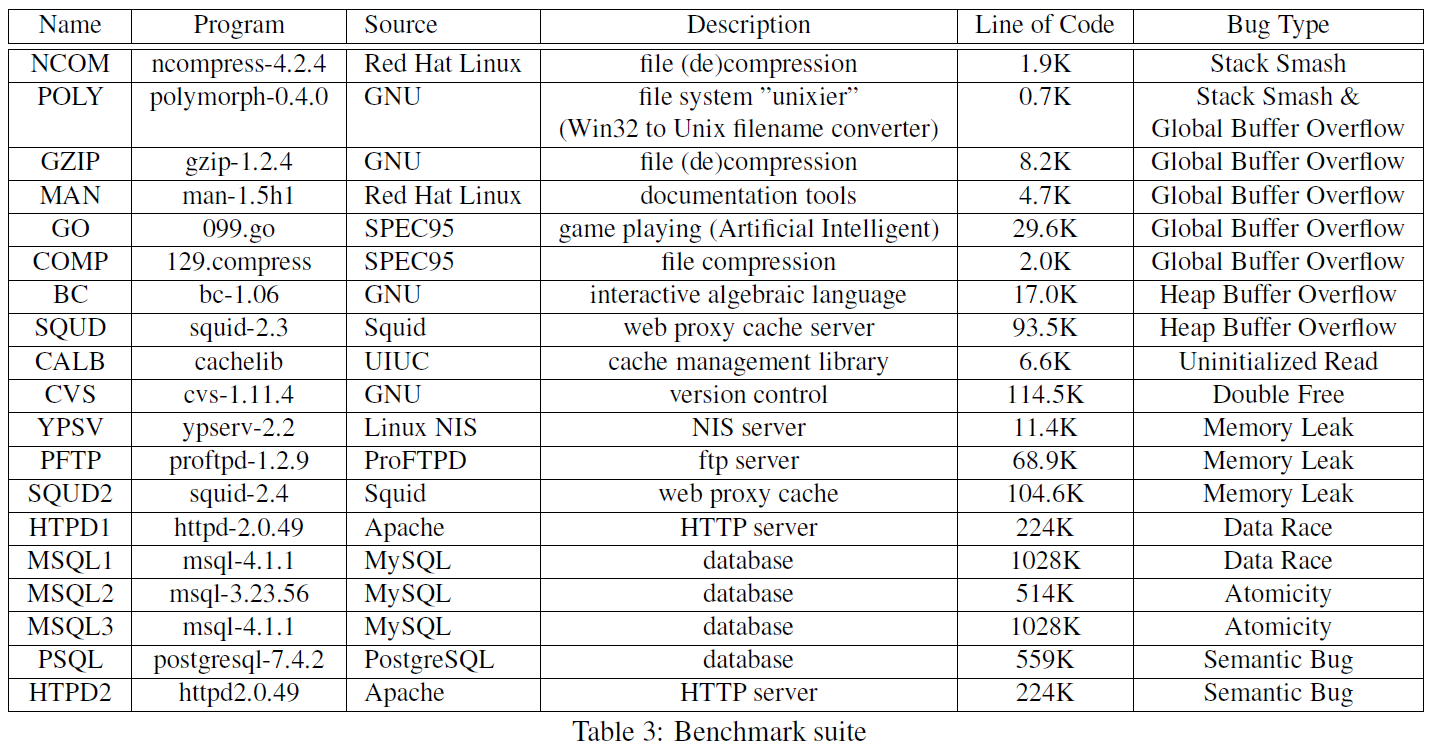
4.2 初步特征分析
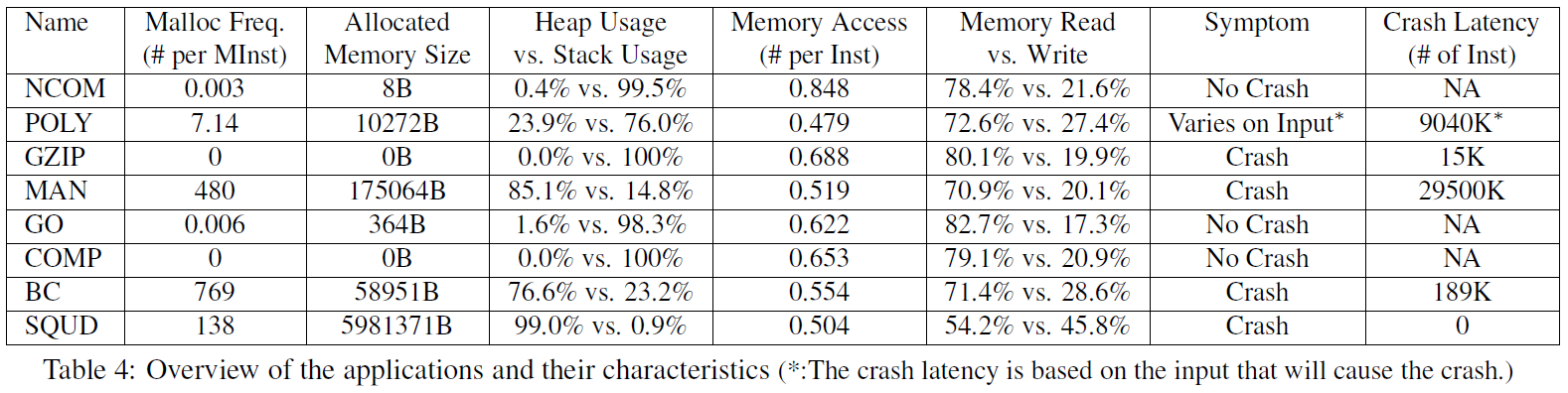
每百万个插桩, 内存分配的频率为[0 ,769], 分配大小从[0, 6.0M]. 一般来说内存分配次数越多, 工具承受的负载越大. 每个插桩的内存访问数为[0.479, 0.848], 堆使用率0%~99%.
为了评价bug复杂度, 这里使用临床症状和crash latency评价. Crash latency是指造成bug的根本原因到应用由于bug传播最终crash的位置的距离. 如果Crash latency很短, bug就很好找到; 但是如果bug在一长串的error传播之后才报出, 检测bug的根本原因就变得困难.
5 初步评价
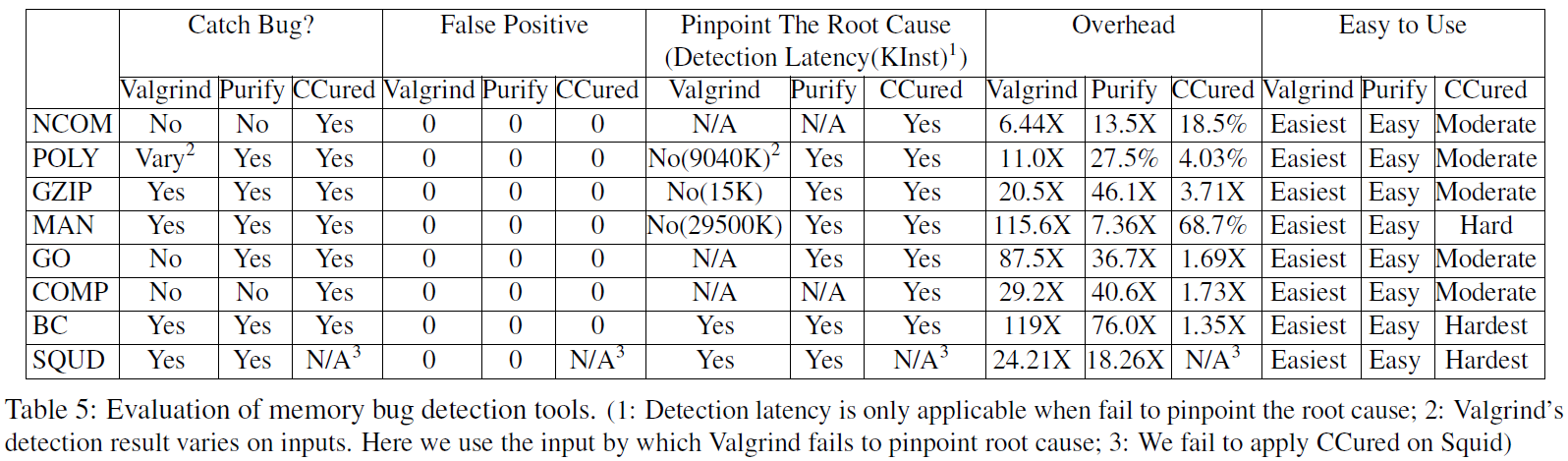
使用Benchmark评价3个bug检测工具:Valgrind, Purify, CCured. 这三个工具都是用来检测内存相关的bug. 所以这里选择了8个内存相关的应用.
CCured负载最小, 因为它在运行前进行了静态分析, 而且发现了所有bug. 尽管它的表现最好, 但是代价是高度依赖于人工预处理代码, 在使用CCured检测BC前用了3到4天学习BC代码和CCured规则去满足CCured语言的要求.
Valgrind和Purify没有找到NCOM和COMP的bug. Valgrind在POLY, GZIP和MAN上存在很大的detect latency.
6 当前状态和未来工作
Benchmark包括应用及其对应的文档和输入集合.
目前正在设计工具从bug数据库(如 Bugzilla)自动提取bug, 这样做不但可以获取很多真实bug, 而且可以获取更深的insight.
接下来的工作会在BugBench上评价更多地bug检测工具. 同时也会考虑添加辅助工具, 比如程序标注的静态工具, 并发bug检测工具的调度和记录-重放工具.