图像美学质量评价技术发展趋势目前图像美学质量评价的应用才刚刚走出实验室,还处于起步阶段,但已经有一些较为成功的案例。https://www.sohu.com/a/237649791_650021张政:京东在智能广告的实践和探索——集成AI理解、AI生成、AI分发的内容生态 - 知乎分享嘉宾:张政 京东 算法工程师 编辑整理:AMS 周金星 出品平台:DataFunTalk 导读:内容生态建设是近几年互联网快速发展的关键动因,也是AI化的重点方向之一。本文主要分享在京东广告业务下内容理解体系的建设情…
![]() https://zhuanlan.zhihu.com/p/522426867 图像美学质量评价是图像质量评价的一个分支,图像质量评价是质量评价的分支,一般质量评价有图像和视频两个维度。评价一张图片,主要从两方面,一个是图像质量评估,如像素、清晰度、有无噪声等,一个是图像审美,也就是美学,如构图、颜色、内容主体等。图像美学偏向于主观感受,而图像质量评估则偏向于客观感受 (比如噪声、饱和度等客观因素)。图像审美由于太过主观,所以评价指标一般是跟数据集中已有的评分进行比较,而后者则有一些客观的评价标准 (如 PSNR,SSIM), 目前对于图像质量评估的数据集、度量标准及研究比较广泛。
https://zhuanlan.zhihu.com/p/522426867 图像美学质量评价是图像质量评价的一个分支,图像质量评价是质量评价的分支,一般质量评价有图像和视频两个维度。评价一张图片,主要从两方面,一个是图像质量评估,如像素、清晰度、有无噪声等,一个是图像审美,也就是美学,如构图、颜色、内容主体等。图像美学偏向于主观感受,而图像质量评估则偏向于客观感受 (比如噪声、饱和度等客观因素)。图像审美由于太过主观,所以评价指标一般是跟数据集中已有的评分进行比较,而后者则有一些客观的评价标准 (如 PSNR,SSIM), 目前对于图像质量评估的数据集、度量标准及研究比较广泛。
美学评估主要就是两大思路,一个分类,将图片分成好坏直接二分类,此外就是根据主题来,每个主题下的图片的美学的角度不一致,本文就是一个以主题为主的美学评估,一个是回归,直接回归出一个分数评分数值,还有就是得到一个分类,然后求分布的均值和方差来刻画图片,这块主要就是NIMA,用emd loss。本文的思路是从主题中抽隐藏的信息,然后主干是用mobilenetv2提特征,在加上一个attention提取rgb的颜色空间特征。
1.introduction
基于像素的元素不能包含任何抽象或者主题信息,审美分数与主题相关,现有方法视图建立图像审美映射。1.现有的数据标签没有考虑不同的主题有不同的评分标准,所有的图像都混合在一起并没有区别进行评分,这会在标签上引入相当大的噪声和误差。2.直接从低级像素学习,并使用嘈杂的gt作为监督信息,很难有效感知审美信息,不足以理解审美,导致注意力分散。
2. related work

美学评估领域的一些数据集,TAD66K是一个面向主题的数据集,包括66k图像,涵盖了47个主题,所有的图像均根据主题手工挑选,每张图片至少有1200个有效标准,并且是按照一批50张来标准。 这里面比较常见的是AVA数据集,是一个有0-10打分的标签。

这里面HGCN是根据layout动态感知的美学评估,用了GCN,其余比较常见的就是NIMA,我们在自己的场景中测试开源的NIMA,效果还是很不错的,基本能够完成基础的评估和排序,是可以做一个维度来分析的。
3.proposed model
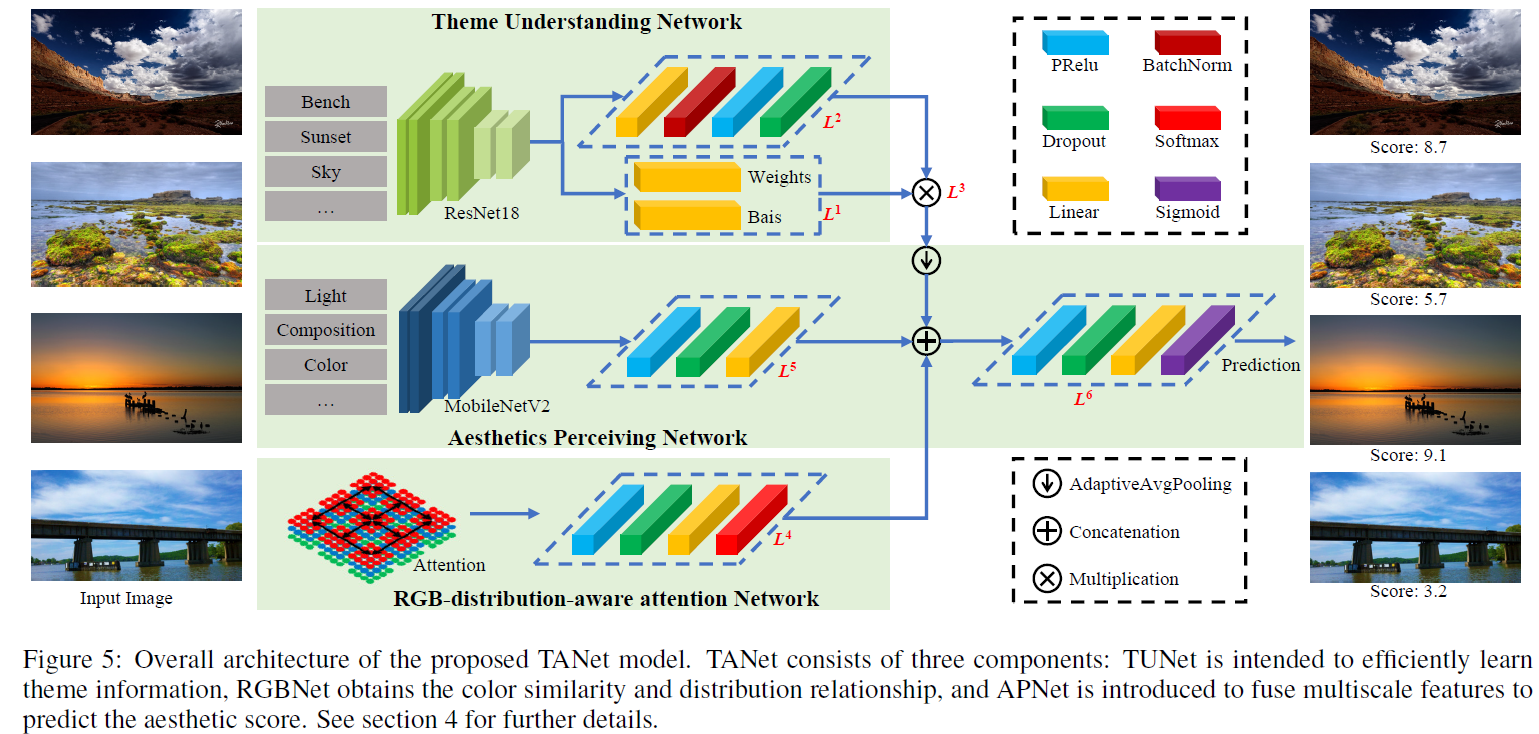
网络还是做的比较复杂的,有三条支路,一条支路是在400+主题,10million图片上预训练的,top5的acc是85.03%,resnet18,mobilenetv2作为特征提取的主干网络,还有个rgb-distribution-aware attention网络,作者的意思说这个支路是为了捕获颜色分布的。
代码如下:
class TANet(nn.Module):
def __init__(self):
super(TANet, self).__init__()
self.res365_last = resnet365_backbone()
self.hypernet = L1()
# L3
self.tygertnet = TargetNet()
self.avg = nn.AdaptiveAvgPool2d((10, 1))
self.avg_RGB = nn.AdaptiveAvgPool2d((12, 12))
self.mobileNet = L5()
self.softmax = nn.Softmax(dim=1)
# L4
self.head_rgb = nn.Sequential(
nn.ReLU(),
nn.Dropout(p=0.75),
nn.Linear(20736, 10),
nn.Softmax(dim=1)
)
# L6
self.head = nn.Sequential(
nn.ReLU(),
nn.Dropout(p=0.75),
nn.Linear(30, 1),
nn.Sigmoid()
)
def forward(self, x):
x_temp = self.avg_RGB(x)
x_temp = Attention(x_temp)
x_temp = x_temp.view(x_temp.size(0), -1)
x_temp = self.head_rgb(x_temp)
res365_last_out = self.res365_last(x)
res365_last_out_weights = self.hypernet(res365_last_out) # 其实就是转成了输出是1,把365转成了1
res365_last_out_weights_mul_out = self.tygertnet(res365_last_out, res365_last_out_weights)
x2 = res365_last_out_weights_mul_out.unsqueeze(dim=2)
x2 = self.avg(x2)
x2 = x2.squeeze(dim=2)
x1 = self.mobileNet(x)
x = torch.cat([x1, x2, x_temp], 1)
x = self.head(x)
return x
s:srcc,L:lcc,emd loss,M:mse loss,R:srcc/acc ratio.可见TANet的指标都还是挺高的,不过TAnet里面有用到预训练的模型,因此这样的对应也不是很公平,也可能是预训练的模型提升了它的效果。

上面这个图是表示注意力机制在RGB空间感知的颜色相似度和分布度量,可以看到左图的两个横条是有相似的地方和不相似的地方,蓝色区域如果相似那么右侧的attention就表现的相对一致。
4.performance comparsion
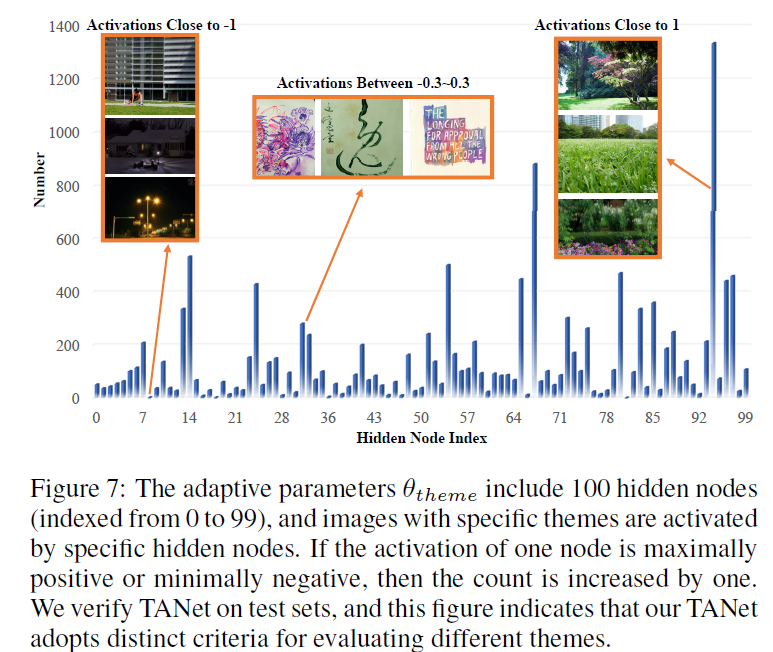
为了辨别模型是否自适应调整了主题融合的权重,提取了预训练的模型的权重的100个隐藏节点,我们在TAD66K的测试集上验证训练好的TANet模型,计算每个图像在最大正向或最小负向激活时的索引,TAnet倾向于将较低的负权重分配给具有较低美感的图像,因为这些图像具有混乱的主题和太暗。访问节点比较高的,色彩和谐,主题鲜明的反应更为积极。此外,一些隐藏节点仅响应特定主题。
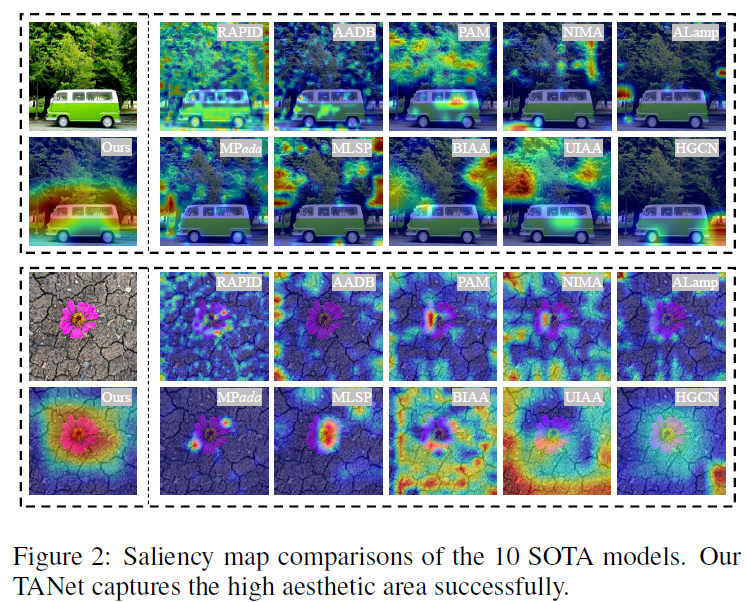
这个图其实能说明TANET用了预训练的模型效果是好的。
