目标检测的评价指标
1. 混淆矩阵(Confusion Matrix)
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。如下:
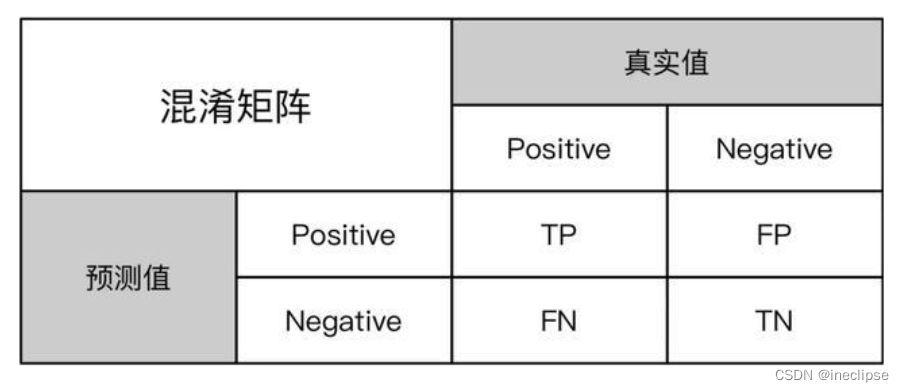
1.TP(True Positive):真实为真样本,预测为真样本。
2.TN(True Negative):真实为负样本,预测为负样本。
3.FP(False Positive):真实为负样本,预测为真样本。
2.FN(False Negative):真实为真样本,预测为负样本。
2. 查准度和召回率(Precision and Recall)
Accuracy是准确度。准确度越高,分类器越好。
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy={
{TP+TN}\over{TP+TN+FP+FN}} Accuracy=TP+TN+FP+FNTP+TN
Precision是指预测正确的部分占预测结果的部分。找的对的比例
P r e c i s i o n = T P T P + F P Precision ={ {TP}\over{TP+FP}} Precision=TP+FPTP
Recall是指预测正确的部分占真实结果的部分。找的全的比例
R e c a l l = T P T P + F N {Recall ={ {TP}\over{TP+FN}}} Recall=TP+FNTP
举个例子,一个不透明的盒子里有5个红球,3个黄球。
现在要取出所有红球,我取出了5个球,里面有三个红球,两个黄球。
Precision = 3/5 5个球里有3个是正确的。
Recall = 3/8 8个红球有3个被取出来了。
3. IoU (Intersection over Union)
IoU是两个区域重叠的部分除以两个区域的集合部分得出的结果,通过设定的阈值,与这个IoU计算结果比较。
I o U = T P T P + F P + F N IoU={
{TP}\over{TP+FP+FN}} IoU=TP+FP+FNTP
4. F1 Srore
F1分数是分类问题的一个衡量指标。F1分数认为召回率和精度同等重要, 一些多分类问题常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。计算公式如下:
F 1 = 2 P ∗ R P + R F1 =2{
{P*R}\over{P+R}} F1=2P+RP∗R
此外还有F2分数和F0.5分数。F2分数认为召回率的重要程度是精度的2倍,而F0.5分数认为召回率的重要程度是精度的一半。更一般地,我们可以定义Fβ(precision和recall权重可调的F1 score):
F β = ( 1 + β ∗ β ) P ∗ R β ∗ β ∗ P + R Fβ =(1+β*β){
{P*R}\over{β*β*P+R}} Fβ=(1+β∗β)β∗β∗P+RP∗R
5. PR曲线(PR curve)
PR曲线,就是precision和recall的曲线,precision为纵坐标,recall为横坐标。
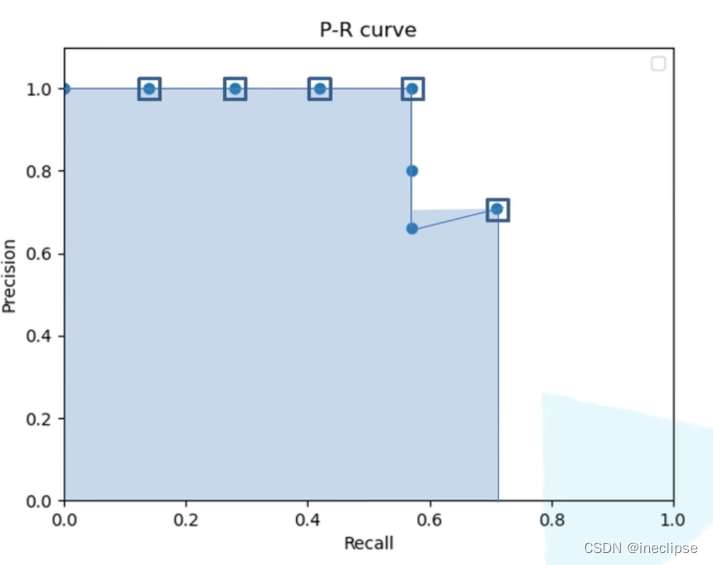
评估能力:
那么PR曲线如何评估模型的性能呢?从图上理解,如果模型的精度越高,召回率越高,那么模型的性能越好。也就是说PR曲线下面的面积越大,模型的性能越好。绘制的时候也是设定不同的分类阈值来获得对应的坐标,从而画出曲线。
PR曲线反映了分类器对正例的识别准确程度和对正例的覆盖能力之间的权衡。
缺点:
PR曲线的缺点是会受到正负样本比例的影响。比如当负样本增加10倍后,在recall不变的情况下,必然召回了更多的负样本,所以精度就会大幅下降,所以PR曲线对正负样本分布比较敏感。对于不同正负样本比例的测试集,PR曲线的变化就会非常大。
6. AP和mAP
AP即Average Precision,称为平均准确率,是对不同召回率点上的准确率进行平均,在PR曲线图上表现为PR曲线下面的面积。AP的值越大,则说明模型的平均准确率越高。
mAP是英文mean average precision的缩写,意思是平均精度均值。在目标检测中,一个模型通常会检测很多种物体,那么每一类都能绘制一个PR曲线,进而计算出一个AP值。那么多个类别的AP值的平均就是mAP.
7. FPS(Frame Per Second)
FPS,即每秒帧率。除了检测准确度,目标检测算法的另一个重要评估指标是速度,只有速度快,才能够实现实时检测。FPS用来评估目标检测的速度。即每秒内可以处理的图片数量。当然要对比FPS,你需要在同一硬件上进行。另外也可以使用处理一张图片所需时间来评估检测速度,时间越短,速度越快。
8. anchor box
anchor box其实就是从训练集的所有ground truth box中统计(使用k-means)出来的在训练集中最经常出现的几个box形状和尺寸。比如,在某个训练集中最常出现的box形状有扁长的、瘦高的和宽高比例差不多的正方形这三种形状。我们可以预先将这些统计上的先验经验加入到模型中,这样模型在学习的时候,有助于模型快速收敛了。以前面提到的训练数据集中的ground truth box最常出现的三个形状为例,当模型在训练的时候我们可以告诉它,你要在grid cell 1附件找出的对象的形状要么是扁长的、要么是瘦高的、要么是长高比例差不多的正方形。anchor box其实就是对预测的对象范围进行约束,并加入了尺寸先验经验,从而实现多尺度学习的目的。
- 量化anchor box
要在模型中使用这些形状,我们需要量化这些形状。YOLO的做法是想办法找出分别代表这些形状的宽和高,YOLO作者的办法是使用k-means算法在训练集中所有样本的ground truth box中聚类出具有代表性形状的宽和高,作者将这种方法称作维度聚类(dimension cluster)。到底找出几个anchor box算是最佳的具有代表性的形状?YOLO作者方法是做实验,聚类出多个数量不同anchor box组,分别应用到模型中,最终找出最优的在模型的复杂度和高召回率(high recall)之间折中的那组anchor box。作者在COCO数据集中使用了9个anchor box。 - 怎么在实际的模型中加入anchor box的先验经验呢?
最终负责预测grid cell中对象的box的最小单元是bounding box,那我们可以让一个grid cell输出(预测)多个bounding box,然后每个bounding box负责预测不同的形状。比如前面例子中的3个不同形状的anchor box,我们的一个grid cell会输出3个参数相同的bounding box,第一个bounding box负责预测的形状与anchor box 1类似的box,其他两个bounding box依次类推。作者在YOLOv3中取消了v2之前每个grid cell只负责预测一个对象的限制,也就是说grid cell中的三个bounding box都可以预测对象,当然他们应该对应不同的ground truth。那么如何在训练中确定哪个bounding box负责某个ground truth呢?方法是求出每个grid cell中每个anchor box与ground truth box的IOU(交并比),IOU最大的anchor box对应的bounding box就负责预测该ground truth,也就是对应的对象。 - 怎么告诉模型第一个bounding box负责预测的形状与anchor box 1类似,第二个bounding box负责预测的形状与anchor box 2类似?
YOLO的做法是不让bounding box直接预测实际box的宽和高(w,h),而是将预测的宽和高分别与anchor box的宽和高绑定,这样不管一开始bounding box输出的(w,h)是怎样的,经过转化后都是与anchor box的宽和高相关,这样经过很多次惩罚训练后,每个bounding box就知道自己该负责怎样形状的box预测了。
9. 置信度(Confidence)
置信度是每个bounding box输出的其中一个重要参数,在yolo v3中对它的作用定义有两重:
1.代表当前box是否有对象的概率Pr(Object)。注意,是对象,不是某个类别的对象,也就是说它用来说明当前box内只是个背景(backgroud),还是有某个物体(对象);
2.表示当前的box有对象时,它自己预测的box与物体真实的box可能的 I o U p r e d t r u t h IoU^{truth}_ {pred} IoUpredtruth的值。注意,这里所说的物体真实的box实际是不存在的,这只是模型表达自己框出了物体的自信程度。以上所述,也就不难理解作者为什么将其称之为置信度了,因为不管哪重含义,都表示一种自信程度:框出的box内确实有物体的自信程度和框出的box将整个物体的所有特征都包括进来的自信程度。经过以上的解释,其实我们也就可以用数学形式表示置信度的定义了:
C i j C^j_i Cij=Pr(object) * I o U p r e d t r u t h IoU^{truth}_{pred} IoUpredtruth
其中, C i j C^j_i Cij表示第i个grid cell的第j个bounding box的置信度。
训练中, C i j C^j_i Cij表示真实值, C i j C^j_i Cij的取值是由grid cell的bounding box有没有负责预测某个对象决定的。如果负责,那么 C i j C^j_i Cij =1,否则, C i j C^j_i Cij=0。
下面我们来说明如何确定某个grid cell的bounding box是否负责预测该grid cell中的对象:前面在说明anchor box的时候提到每个bounding box负责预测的形状是依据与其对应的anchor box(bounding box prior)相关的,那这个anchor box与该对象的ground truth box的IOU在所有的anchor box(与一个grid cell中所有bounding box对应,COCO数据集中是9个)与ground truth box的IOU中最大,那它就负责预测这个对象,因为这个形状、尺寸最符合当前这个对象,这时 C i j C^j_i Cij=1,其他情况下 C i j C^j_i Cij=0。注意,所有anchor box与某个ground truth box的IOU最大的那个anchor box对应的bounding box负责预测该对象,与该bounding box预测的box没有关系。
10. 对象条件类别概率(conditional class probabilities)
对象条件类别概率是一组概率的数组,数组的长度为当前模型检测的类别种类数量,它的意义是当bounding box认为当前box中有对象时,检测的所有类别中每种类别的概率。分类模型中最后输出之前使用softmax求出每个类别的概率,也就是说各个类别之间是互斥的,而YOLOv3算法的每个类别概率是单独用逻辑回归函数(sigmoid函数)计算得出了,所以每个类别不必是互斥的,也就是说一个对象可以被预测出多个类别。