英文论文:Document AI: Benchmarks, Models and Applications
中文论文:文档智能:数据集、模型和应用
Workshop PPT:Click Here
作者:微软亚洲研究院
日期:2021.09
微软文档智能论文检索:link
这篇论文把文档智能涉及的产生背景、细分领域、经典算法、主流数据集和模型做了很好地介绍,非常值得一读。有中文版和英文版,省去查阅术语的烦恼。英文版有些许改动。本文重点关注第五章节,将其中提及的数据集和深度学习模型的论文做了查阅和整理,方便后续阅读。
思维导图

文章目录
摘要
Document AI, or Document Intelligence, is a relatively new research topic that refers to the techniques for automatically reading, understanding, and analyzing business documents. It is an important research direction for natural language processing and computer vision. In recent years, the popularity of deep learning technology has greatly advanced the development of Document AI, such as document layout analysis, visual information extraction, document visual question answering, document image classification, etc. This paper briefly reviews some of the representative models, tasks, and benchmark datasets. Furthermore, we also introduce early-stage heuristic rule-based document analysis, statistical machine learning algorithms, and deep learning approaches especially pre-training methods. Finally, we look into future directions for Document AI research.
文档智能是指通过计算机进行自动阅读、理解以及分析商业文档的过程,是自然语言处理和计算机视觉交叉领域的一个重要研究方向。近年来,深度学习技术的普及极大地推动了文档智能领域的发展,以文档版面分析、文档信息抽取、文档视觉问答以及文档图像分类等为代表的文档智能任务都有显著的性能提升。本文对于早期基于启发式规则的文档分析技术、基于统计机器学习的算法、以及近年来基于深度学习和预训练的方法进行简要介绍,并展望了文档智能技术的未来发展方向。
1. 文档智能
文档智能(Document AI, or Document Intelligence)是近年来一项蓬勃发展的研究课题和实际的工业界需求,主要是指对于网页、数字文档或扫描文档所包含的文本以及丰富的排版格式等信息,通过人工智能技术进行理解、分类、提取以及信息归纳的过程。由于布局和格式的多样性、低质量的扫描文档图像以及模板结构的复杂性,文档智能是一项非常具有挑战性的任务并获得相关领域的广泛关注。随着数字化进程的加快,文档、图像等载体的结构化分析和内容提取成为关乎企业数字化转型成败的关键一环,自动、精准、快速的信息处理对于生产力的提升至关重要。
图1所表示的是在当前深度学习框架下文档智能技术的基本框架,其中不同类型的文档通过内容提取工具(HTML/XML抽取、PDF解析器、光学字符识别OCR等)将文本内容、位置布局信息和视觉图像信息组织起来,利用大规模预训练的深度神经网络进行分析,最终完成各项下游应用任务,包括文档版面分析、文档信息抽取、文档视觉问答以及文档图像分类等。深度学习技术的出现,特别是以卷积神经网络、图神经网络以及Transformer为代表预训练技术的出现,彻底改变了传统机器学习需要大量人工标注数据的前提,更多地依赖大量无标注数据进行自监督学习,进而通过“预训练-参数调优”模式来解决文档智能相关的应用任务,取得了显著性突破。
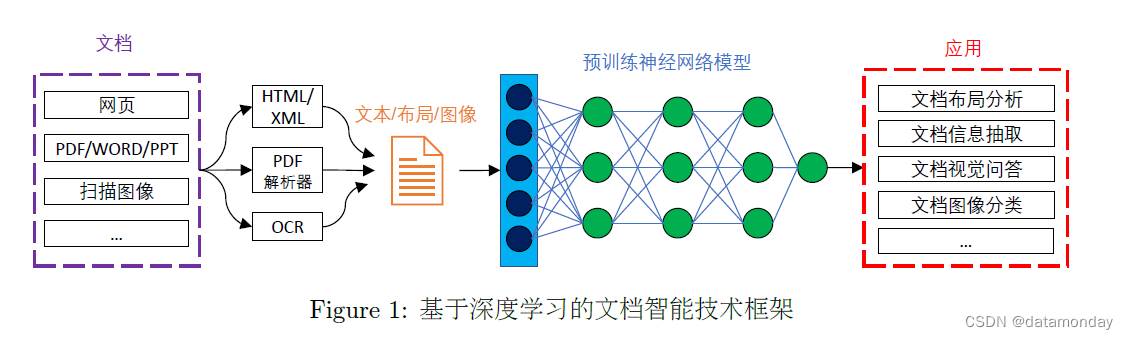
2.主流文档智能技术模型框架、任务及数据集
2.1 基于卷积神经网络架构的文档版面分析模型
文档版面分析(document layout analysis) 本质上可以看作一种文档图像的物体检测任务,文档中的标题、段落、表格、插图等基本单元就是需要检测和识别的物体。
- Yang et al. (2017a) 将文档版面分析看作是一个像素级分割任务(pixel-level segmentation task),并尝试利用卷积神经网络进行像素分类取得很好的效果。
- Schreiber et al. (2017) 首次利用 Faster R-CNN 模型应用于文档版面分析中的表格识别任务,如图2所示,在 ICDAR 2013(Gobelet al., 2013) 表格识别数据集取得了SOTA的结果。
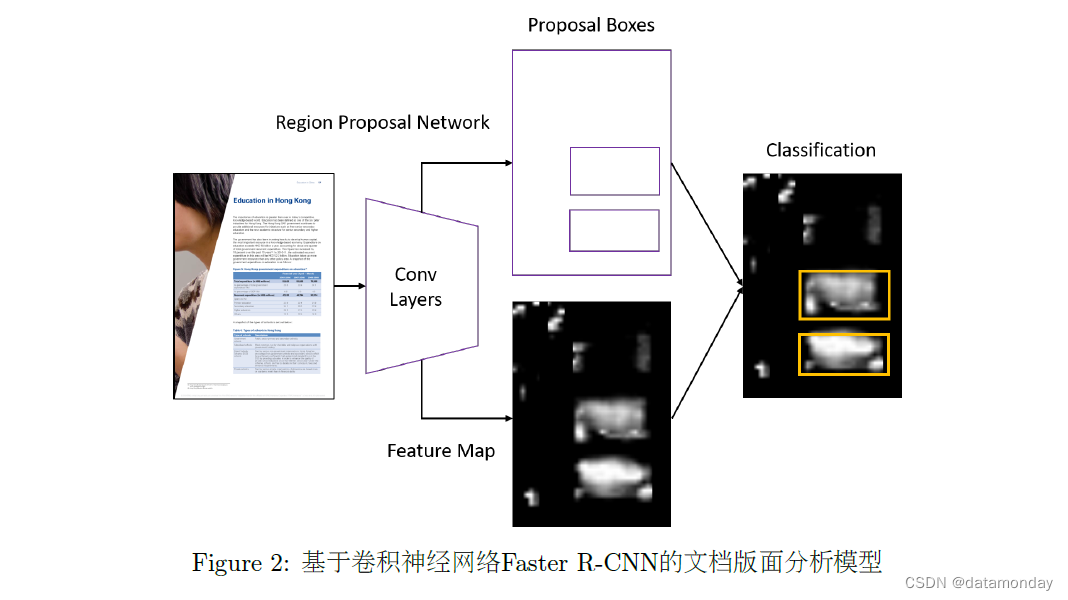
文档版面分析虽然是一个经典的文档智能任务,但是多年来一直受限于较小的数据集规模,仅仅套用经典计算机视觉预训练模型依然是不够的。随着大规模弱监督文档版面分析数据集 PubLayNet (Zhong et al., 2019b),PubTabNet (Zhong et al., 2019a),TableBank (Li et al.,2020a) 和 DocBank (Li et al., 2020b) 数据集的出现,研究人员可以对不同的计算机视觉模型和算法进行更为深入的比较和分析,进一步推动了文档版面分析技术的发展。
2.2 基于图神经网络架构的文档信息抽取模型
信息抽取(Information Extraction) 是从非结构化文本中提取结构化信息的过程,其作为一个经典和基础的自然语言处理问题已经得到广泛研究。传统的信息抽取聚焦于从纯文本中提取实体与关系信息,却较少有对视觉富文本的研究。视觉富文本数据是指语义结构不仅由本文内容决定,也与排版、表格结构、字体等视觉元素有关的文本数据。视觉富文本数据在生活中随处可见,例如收据、证件、保险单等。
Liu et al. (2019a) 提出利用图卷积神经网络对视觉富文本数据进行建模,如图3所示。每张图片经过OCR系统后会得到一组文本块,每个文本块包含其在图片中的坐标信息与文本内容。这项工作将这一组文本块构成全连接有向图,即每个文本块构成一个节点,每个节点都与其他所有节点有连接。节点的初始特征由文本块的文本内容通过Bi-LSTM编码得到。边的初始特征为邻居文本块与当前文本块的相对坐标与长宽信息,该特征使用当前文本块的高度进行归一化,具有仿射不变性。与其他图卷积模型仅在节点上进行卷积不同,这项工作更加关注在信息抽取中“个体-关系-个体“的三元信息更加重要,所以在”节点-边-节点“的三元特征组上进行卷积。除此之外,还引入了自注意力机制,让网络在全连接有向图构成的所有有向三元组中挑选更加值得注意的信息,并加权聚合特征。初始的节点特征与边特征经过多层卷积后得到节点与边的高层表征。
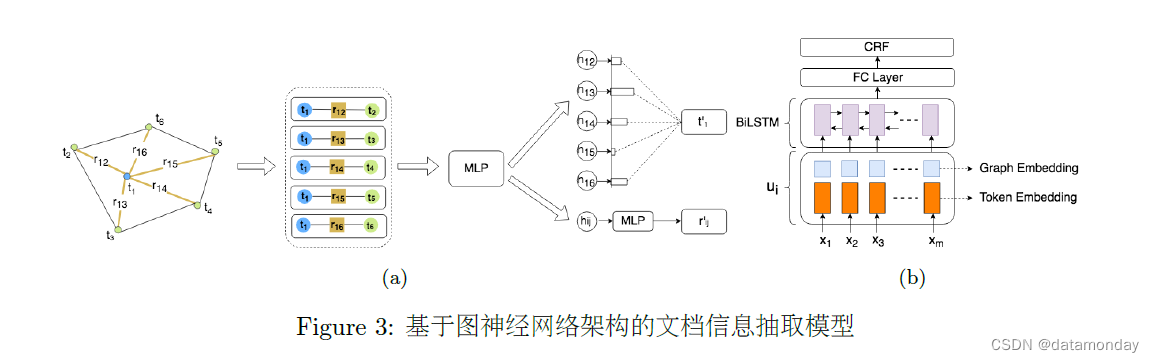
这项工作在两份真实商业数据上测试了所提出方法的效果,分别为增值税发票(VATI,固定版式,3000张)和国际采购收据(IPR,非固定版式,1500张)。使用了两个Baseline,Baseline I为对每个文本块的文本内容独立做BiLSTM+CRF解码,Baseline II为将所有文本块的文本内容进行“从左到右、从上到下”的顺序拼接后,对拼接文本整体做BiLSTM+CRF解码。实验表明,基于图卷积的模型在Baseline的基础上都有明显提升,其中在仅依靠文本信息就可以抽取的字段(如日期)上与Baseline持平,而在需要依靠视觉信息做判断的字段(如价格、税额)上有较大提升。此外,实验显示,视觉信息起主要作用,增加了语义相近文本的区分度。文本信息也对视觉信息起到一定的辅助作用。自注意力机制在固定版式数据上基本没有帮助,但是在非固定版式数据上有一定提升。
2.3 基于Transformer架构的通用文档理解预训练模型
很多情况下,文档中文字的位置关系蕴含着丰富的语义信息。例如,表单通常是以键值对(key-value pair)的形式展示的。通常情况下,键值对的排布通常是左右或者上下形式,并且有特殊的类型关系。类似地,在表格文档中,表格中的文字通常是网格状排列,并且表头一般出现在第一列或第一行。通过预训练,这些与文本天然对齐的位置信息可以为下游的信息抽取任务提供更丰富的语义信息。对于富文本文档,除了文字本身的位置关系之外,文字格式所呈现的视觉信息同样可以帮助下游任务。对文本级(token-level)任务来说,文字大小,是否倾斜,是否加粗,以及字体等富文本格式能够体现相应的语义。通常来说,表单键值对的键位(key)通常会以加粗的形式给出。对于一般文档来说,文章的标题通常会放大加粗呈现,特殊概念名词会以斜体呈现等。对文档级(document-level)任务来说,整体的文档图像能提供全局的结构信息。例如个人简历的整体文档结构与科学文献的文档结构是有明显的视觉差异的。这些模态对齐的富文本格式所展现的视觉特征可以通过视觉模型抽取,结合到预训练阶段,从而有效地帮助下游任务。
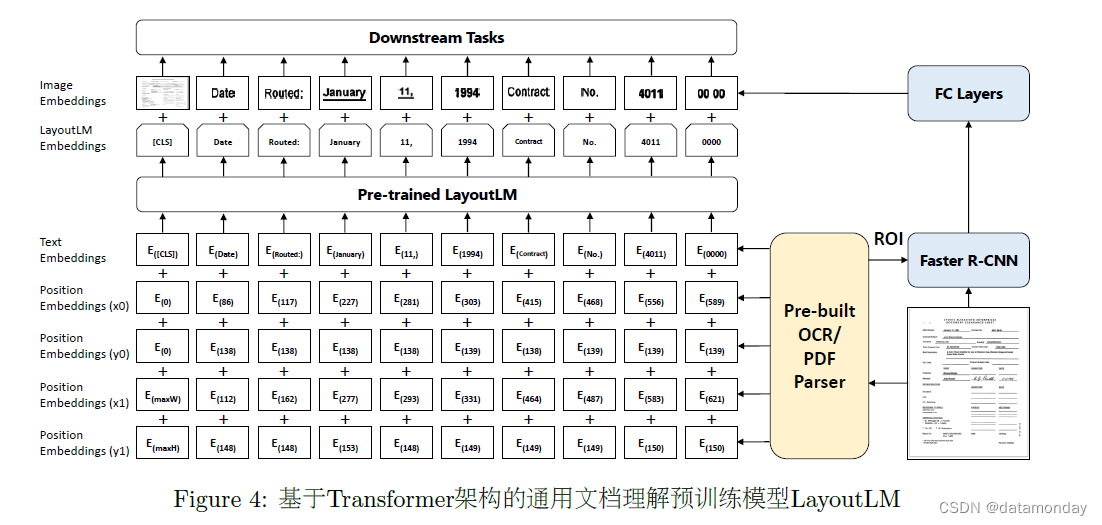
为了利用上述信息,我们提出了通用文档预训练模型 LayoutLM (Xu et al., 2020),如图4所示。在现有的预训练模型基础上添加 2-D position embedding 和 image embedding 两种新的embedding层,这样一来可以有效地结合文档结构和视觉信息。具体来讲,根据OCR获得的文本Bounding Box,我们能获取文本在文档中的具体位置。将对应坐标转化为虚拟坐标之后,我们计算该坐标对应在x、y、w、h四个embedding子层的表示,最终的2-D position embedding 为四个子层的 embedding 之和。在 image embedding 部分,我们将每个文本相应的 Bounding Box 当作 Faster R-CNN 中的候选框(Proposal),从而提取对应的局部特征。特殊地,由于[CLS]符号用于表示整个输入文本的语义,我们同样使用整张文档图像作为该位置的 image embedding,从而保持模态对齐。
在预训练阶段,我们针对 LayoutLM 的特点提出两个自监督预训练任务:
- Masked Visual-Language Model(MVLM,遮罩式视觉语言模型):大量实验已经证明坍坌坍能够在预训练阶段有效地进行自监督学习。我们在此基础上进行了修改:在遮盖(Mask)当前词之后,保留对应的 2-D position embedding 暗示,让模型预测对应的词。在这种方法下,模型根据已有的上下文和对应的视觉暗示预测被遮罩的词,从而让模型更好地学习文本位置和文本语义的模态对齐关系。
- Multi-Label Document Classification(MDC,多标签文档分类):MLM能够有效的表示词级别的信息,但是对于文档级的表示,我们需要文档级的预训练任务来引入更高层的语义信息。在预训练阶段我们使用的IIT-CDIP数据集为每个文档提供了多标签的文档类型标注,我们引入坍坄坃多标签文档分类任务。该任务使得模型可以利用这些监督信号去聚合相应的文档类别,并捕捉文档类型信息,从而获得更有效的高层语义表示。
实验结果表明,我们在预训练中引入的结构和视觉信息,能够有效地迁移到下游任务中。最终在多个下游任务中都取得了显著的准确率提升。与传统的基于卷积神经网络和图神经网络模型不同,通用文档智能预训练模型的优势在于可以支持不同类型的下游应用。
2.4 文档智能主流任务和数据集
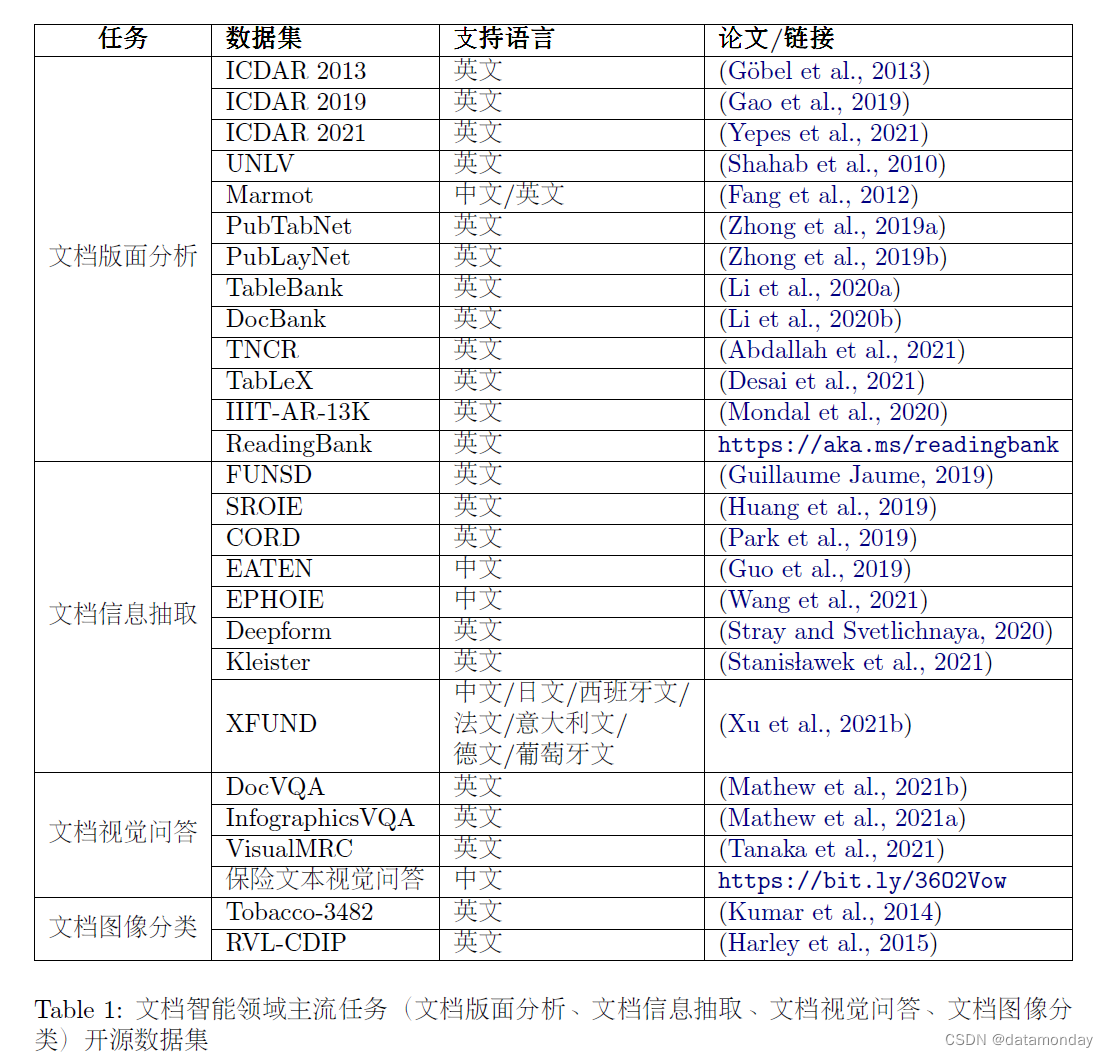
3. 基于启发式规则的文档分析技术
采用启发式规则的文档分析技术大致可分为自顶向下、自底向上和混合模式三种方式。
- 自顶向下:将文档图片作为整体逐步将其划分为不同区域。以递归方式进行切割,直至区域分割至预定义的标准,通常为块或列。
- 自底向上:以像素或组件为基本元素单位,对基本元素进行分组、合并以形成更大的同质区域。自顶向下方式在特定格式下的文档中能够更快、更高效地分析文档。而自底向上虽需要耗费更多的计算时间,但通用型更强,可覆盖更多不同布局类型的文档。
- 混合方式:将其两者相结合以尝试产生更好的效果。
3.1 Projection Profile
Projection Profile作为一种自顶向下的分析方式被广泛应用于文档分析。Projection Profile分析算法适用于结构化文本,尤其是曼哈顿布局文档。在布局复杂、文本倾斜或包含边界噪声的文档上可能无法展现出良好的性能。
3.2 Image Smearing
Image Smearing分析法指从一个位置向四周渗透,逐渐扩展至所有同质区域,以此确定页面当中的一个区域。
3.3 Connected Components
Connected Components分析法作为一种自底向上的技术,推测最小粒度元素之间的关系,用于寻找同质区域,最终将区域分类为不同属性。由于计算过程中需要估计字符间距和行内间距,因此当文档中包含大字体及宽字间距等情况时,模型并不能发挥出良好性能。
3.4 其他方法
4. 基于统计机器学习的文档分析技术
传统的文档分析过程通常分为两阶段:
- 将文档图片切割,得到多个不同候选区域。
- 对区域进行属性分类,将其判别为文本、图像等规定类。
基于机器学习的方案也通常从这两个角度入手,部分工作尝试使用机器学习算法参与文档的切割,其余则尝试在已生成的区域上构造特征使用机器学习算法对区域进行分类。此外由于统计机器学习技术带来的性能上的提升,较多基于统计机器学习的方法在表格检测任务中被尝试使用,因此 表格检测(table detection) 作为文档分析的一个重要子任务。
4.1 文档切割
4.2 区域分类
4.3 表格检测
5. 基于深度学习的文档智能技术
5.1 针对特定任务的深度学习模型
文档版面分析是指对文档版面内的图像、文本、表格信息和位置关系所进行的自动分析、识别和理解的过程。文档版面分析本质上可以看作一种文档图像的物体检测任务,文档中的标题、段落、表格、插图等基本单元就是需要检测和识别的物体。
1)文档版面分析
文档版面分析包含两个主要的子任务:
- 文档视觉结构分析:主要目的是检测文档结构并确定其同类区域的边界。
- 文档语义结构分析:为这些检测到的区域标记具体的文档类别,如标题、段落、表格等。
数据集:
| 数据集(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| PubLayNet(2019) | Publaynet: largest dataset ever for document layout analysis. | https://arxiv.org/abs/1908.07836 | 大规模的文档版面分析数据集,通过自动解析PubMed的XML文件构建了超过36万个文档图片。 |
| DocBank(2020) | DocBank:A benchmark dataset for document layout analysis. | https://aclanthology.org/2020.coling-main.82. | 通过arXiv网站的PDF文件和LaTeX文件的对应关系自动构建了一个可扩展的文档版面分析数据集,同时支持对基于文本的方法和基于图像的方法进行评测。 |
| IIIT-AR-13K(2020) | Iiit-ar-13k: a new dataset for graphical object detection in documents. | https://arxiv.org/abs/2008.02569 | 提供了13000的人工标注的文档图片用于版面分析。 |
模型
较为经典的卷积神经网络应用在文档版面分析领域的工作集中在2016-2018年,之后的研究针对目标检测算法进行了针对性的改进,以提高文档版面分析的性能。
| 模型(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| (2017) | Learning to extract semantic structure from documents using multimodal fully convolutional neural networks. | CVPR2017 | 将文档语义结构分析任务视为一个逐像素的分类问题。他们提出了一个同时考虑视觉和文本信息的多模态神经网络。 |
| (2017) | Fast cnn-based document layout analysis. | ICCVW2017 | 提出了一个用于移动和云服务的文档布局分析的轻量级模型。该模型使用图像的一维信息进行推理,并与使用二维信息的模型进行比较,在实验中取得了较高的准确性。 |
| (2017) | Convolutional neural networks for page segmentation of historical document images. | ICDAR2017 | 介绍了一种基于卷积神经网络的手写历史文件图像的页面分割方法。 |
| (2018) | dhsegment: A generic deep-learning approach for document segmentation. | ICFHR2018 | 提出了一个基于CNN的多任务逐像素预测模型。 |
| (2018) | Fully convolutional neural networks for page segmentation of historical document images. | DAS2018 | 提出了一个用于历史文件分割的高性能全卷积神经网络 |
| (2019) | A two-stage method for text line detection in historical documents. | IJDAR2019 | 提出了一种针对历史文献的两阶段文本行检测方法。 |
| (2019) | Visual detection with context for document layout analysis. | EMNLP | 将上下文信息纳入Faster R-CNN模型。该模型利用文章元素内容的局部不变性质,提高了区域检测性能。 |
2)表格检测、表格结构识别、表格理解
在文档版面分析中,表格理解是一项富有挑战性的任务。有别于标题、段落等文档元素,表格的格式通常较为多变,结构也较为复杂。因此,有大量的相关工作围绕表格进行展开,其中最为主要的两个子任务分别是表格检测和表格结构识别。
- 表格检测:确定文档中的表格的边界。
- 表格结构识别:将表格的语义结构,包括行、列、单元格的信息按照预定义的格式抽取出来。
数据集(主要来自ICDAR会议)
| 数据集(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| Marmot(2012) | Dataset, ground-truth and performance metrics for table detection evaluation. | https://ieeexplore.ieee.org/document/6195411 | |
| UNLV(2010) | An open approach towards the benchmarking of table structure recognition systems. | https://dl.acm.org/doi/10.1145/1815330.1815345 | |
| (2013) | Icdar 2013 table competition | https://ieeexplore.ieee.org/document/6628853 | |
| (2019) | Icdar 2019 competition on table detection and recognition (ctdar) | https://ieeexplore.ieee.org/document/8978120 | |
| TableBank(2020) | TableBank:Table benchmark for image-based table detection and recognition. | https://arxiv.org/abs/1903.01949 | 传统表格数据集通常较小,难以发挥现代深度神经网络的优势,TableBank利用LaTeX和Word自动构建了一个大规模的表格理解数据集。 |
| PubTabNet(2019) | Image-based table recognition: data, model, and evaluation | https://arxiv.org/abs/1911.10683 | 提出了一个大规模表格数据集并提供了表格结构及单元格内容辅助表格识别。 |
| TNCR(2021) | TNCR: Table net detection and classification dataset | https://doi.org/10.1016/j.neucom.2021.11.101 | 在提供表格标注的同时提供了表格类别的标注。 |
模型:
针对表格理解这一任务的特性,许多目标检测的方法在表格理解领域都能取得较好的效果。Faster R-CNN(2016)是常用的目标检测算法。
| 模型(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| Decnt(2018) | Decnt: Deep deformable cnn for table detection. | https://doi.org/10.1109/ACCESS.2018.2880211 | 通过将可变形卷积应用在Faster R-CNN上获得了更好的性能。 |
| CascadeTabNet(2020) | CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents | https://arxiv.org/abs/2004.12629 | 使用了Cascade R-CNN模型同时完成表格检测和表格结构识别。 |
| TableSense(2019) | TableSense: Spreadsheet Table Detection with Convolutional Neural Networks | https://arxiv.org/abs/2106.13500 | 通过增加单元格特征、添加采样算法来显著提高了表格检测能力。 |
除了上述两个主要的子任务,针对已解析后表格的理解也逐渐成为新的挑战。
模型
| 模型(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| TAPAS(2020) | Tapas: Weakly supervised table parsing via pre-training. | https://arxiv.org/abs/2004.02349 | 将预训练技术引入到表格理解任务的模型。通过引入额外的位置编码层,TAPAS可以使Transformer编码器接收结构化的表格输入。经过在大量的表格数据上进行掩码式预训练后,TAPAS在多种下游语义分析任务中显著超过了传统方法。 |
| TUTA(2020) | TUTA: Tree-based Transformers for Generally Structured Table Pre-training | https://arxiv.org/abs/2010.12537 | 引入了二维坐标树来表示结构化表格的层级信息,并针对这一结构提出了基于树结构的位置表示方式和注意力机制来显示建模层次化表格。结合不同层级的预训练任务,TUTA在多个下游数据集上取得了进一步的性能提升。 |
3)文档信息抽取
信息抽取(Information Extraction)是从非结构化文本中提取结构化信息的过程,其作为一个经典和基础的自然语言处理问题已经得到广泛研究。
文档信息抽取是指从大量非结构化富文本文档内容中抽取语义实体及其之间关系的技术。文档信息抽取任务对于文档类别的不同,抽取的目标实体也不尽相同。
数据集
| 数据集(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| CORD(2019) | CORD: A Consolidated Receipt Dataset for Post-OCR Parsing | https://github.com/clovaai/cord | 是一个票据理解数据集,并包含8个大类共54小类种实体标签。 |
| Kleister(2021) | Kleister: Key Information Extraction Datasets Involving Long Documents with Complex Layouts | https://arxiv.org/abs/2105.05796 | 是一个针对长文档实体抽取任务的文档理解数据集,包含有协议和财务报表等长文本文档。 |
| DeepForm(2020) | DeepForm: Understand Structured Documents at Scale | link | 是一个针对电视和有线电视政治广告披露表格的英文数据集。 |
| EATEN(2021) | EATEN: Entity-aware Attention for Single Shot Visual Text Extraction | https://arxiv.org/abs/1909.09380 | 是针对中文证件的信息抽取数据集,在其400张子集上进一步添加了文本框标注。 |
| EPHOIE(2021) | Towards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution | https://arxiv.org/abs/2102.06732 | 是一个针对中文文档数据的信息抽取数据集。 |
| XFUND(2022) | XFUND: A Benchmark Dataset for Multilingual Visually Rich Form Understanding | https://aclanthology.org/2022.findings-acl.253/ | 是随着LayoutXLM模型提出了针对FUNSD数据集的多语言扩展版本,包含有除英文以外的七种主流语言的富文本文档。 |
由于富文本文档的丰富视觉信息,很多研究工作将文档信息抽取任务建模为了计算机视觉任务,通过语义分割或文本框回归等任务进行信息抽取。考虑到文档信息抽取中文本信息同样具有重要作用,通常的框架是将文档图片视为像素网格,并在该特征图上添加文本特征来获得更好的特征表示。根据添加文本特征级别的不同,这一方法的基本发展顺序呈现出了从字符级别到单词级别再到上下文级别的趋势。
模型
| 模型(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| Chargrid(2018) | Chargrid: Towards Understanding 2D Documents | https://aclanthology.org/D18-1476/ | 利用一个基于卷积的编码器圭解码器网络,通过将字符进行Onehot编码来将文本信息融合到图像中。 |
| Wordgrid(2018) | Wordgrid: Extending Chargrid with Word-level Information | link | |
| VisualWordGrid(2020) | VisualWordGrid: Information Extraction From Scanned Documents Using A Multimodal Approach | https://arxiv.org/abs/2010.02358 | 通过将字符级文本信息换成单词级的word2vec特征,并融合了一定的视觉信息,提高了抽取任务的性能。 |
| BERTgrid(2019) | BERTgrid: Contextualized Embedding for 2D Document Representation and Understanding | https://arxiv.org/abs/1909.04948 | 通过使用BERT获得了上下文文本表示,进一步提升了性能。 |
| ViBERTgrid(2021) | ViBERTgrid: A Jointly Trained Multi-Modal 2D Document Representation for Key Information Extraction from Documents | https://arxiv.org/abs/2105.11672 | 在BERTgrid的基础上将坂坅坒坔的文本特征较早地在卷积阶段与图像特征进行融合,从而获得了较好的效果。 |
由于富文本文档中的信息仍以文本作为主体,很多研究工作将文档信息抽取任务作为特殊的自然语言理解任务。
| 模型(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| (2020) | Representation Learning for Information Extraction from Form-like Documents | https://aclanthology.org/2020.acl-main.580/ | 通过根据抽取目标的类别来生成目标备选,在表单任务上取得了较好的效果。 |
| TRIE(2020) | TRIE: End-to-End Text Reading and Information Extraction for Document Understanding | https://arxiv.org/abs/2005.13118 | 联合文本检测识别与信息抽取,让两个阶段的任务互相促进从而获得更好的信息抽取效果。 |
| DocStruct(2020) | DocStruct: A Multimodal Method to Extract Hierarchy Structure in Document for General Form Understanding | https://arxiv.org/abs/2010.11685 | 通过三种不同模态信息的融合来预测文本片段之间的关系,实现了对表单的层次化抽取。 |
非结构化的富文本文档由多个邻接的文本片段组成,那么自然可以使用图网络对非结构化富文本文档进行表示。文档中的文本片段建模为图中的节点,而文本片段之间的关系则可建模为边,这样整个文档就可以被表示为一个图网络。
| 模型(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| (2019) | Graph convolution for multimodal information extraction from visually rich documents | https://arxiv.org/abs/1903.11279 | 图神经网络在富文本文档中进行信息抽取的代表性工作。 |
| (2021) | Spatial dependency parsing for semi-structured document information extraction | https://arxiv.org/abs/2005.00642 | 将文档建模为了有向图,通过依存分析的方法对文档进行信息抽取。 |
| (2019) | Table Detection in Invoice Documents by Graph Neural Networks | https://ieeexplore.ieee.org/document/8978079 | 使用基于图神经网络的模型来进行发票中表格的信息抽取。 |
| (2020) | Robust layout-aware ie for visually rich documents with pre-trained language models | https://arxiv.org/abs/2005.11017 | 通过在预训练模型的输出表示上使用图卷积神经网络来建模文本布局,提高了信息抽取的性能。 |
| (2020) | One-shot Text Field Labeling using Attention and Belief Propagation for Structure Information Extraction | https://arxiv.org/abs/2009.04153 | 通过将文档表示为图结构并使用基于图的注意力机制,结合CRF在小样本学习上取得了较好的性能。 |
| PICK(2020) | PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks | https://arxiv.org/abs/2004.07464 | 通过引入一个可基于节点进行学习的图来表示文档,在发票抽取任务中取得了较好的性能。 |
4)文档图像分类
文档图像分类是指对文档图像进行归类标记的任务。
数据集
| 数据集(年份) | 来源 | 链接 | 介绍 |
|---|---|---|---|
| RVL-CDIP(2015) | Kaggle | https://www.kaggle.com/datasets/pdavpoojan/the-rvlcdip-dataset-test | The RVL-CDIP (Ryerson Vision Lab Complex Document Information Processing) dataset consists of 400,000 grayscale images in 16 classes, with 25,000 images per class. There are 320,000 training images, 40,000 validation images, and 40,000 test images. The images are sized so their largest dimension does not exceed 1000 pixels. |
| Tabacco-3482(2014) | Kaggle | https://www.kaggle.com/datasets/patrickaudriaz/tobacco3482jpg | Structural Similarity for Document Image Classification and Retrieval. |
由于文档图像分类仍然属于图像分类的范畴,所以针对自然图片的分类算法同样能较好的解决文档图像分类的问题。
| 模型(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| (2015) | Deepdocclassifier: Document classification with deep convolutional neural network | https://ieeexplore.ieee.org/document/7333933 | 介绍了一种基于深度卷积神经网络的文档图像分类方法用于文档图像分类。为了克服小数据集样本不足的问题,他们使用了经过Imagenet训练的Alexnet网络作为初始化,从而迁移到文档图像领域。 |
| (2017) | Cutting the error by half: Investigation of very deep cnn and advanced training strategies for document image classification | https://arxiv.org/abs/1704.03557 | 尝试将GoogLeNet,VGG,ResNet等在自然图片领域获得成功的模型通过迁移学习的方式在文档图片上进行训练。 |
| (2017) | Analysis of convolutional neural networks for document image classification | https://arxiv.org/abs/1708.03273 | 通过对模型参数和数据处理的调整,使CNN模型不借助从自然图片的迁移学习就能优于此前模型的性能。 |
| (2018) | Document image classification with intra-domain transfer learning and stacked generalization of deep convolutional neural networks | https://arxiv.org/abs/1801.09321 | 提出了一个基于不同区域分类的深度卷积神经网络框架用于文档图像分类。该方法通过对文档的不同区域分别进行分类,最终融合多个不同区域的分类器在文档图像分类上获得了明显的性能提升。 |
| (2019) | Deterministic routing between layout abstractions for multi-scale classification of visually rich documents | https://www.ijcai.org/proceedings/2019/0466.pdf | 通过引入了金字塔形的多尺度结构来抽取不同层级的特征。 |
| (2019) | Modular multimodal architecture for document classification | https://arxiv.org/abs/1912.04376 | 通过对文档图片进行字符识别获得文档的文本,并对图像特征和文本特征进行组合,进一步提升了分类性能。 |
5)文档视觉问答
文档视觉问答是一个针对文档图片的高层理解任务。具体来说,给定一张文档图片和一个针对性的问题,模型需要根据图片给出该问题的正确答案。具体的例子如图5所示。
不同于VQA任务,文档视觉问答中的文档文本对任务具有关键作用,所以现存的代表性方法都将文档图片进行字符识别(OCR)处理得到的文档文本作为重要的信息。在得到文档文本后,针对不同数据的特点,视觉问答任务被建模为不同的问题。
数据集
| 数据集(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| DocVQA(2021) | DocVQA: A Dataset for VQA on Document Images | https://icdar2021.org/program-2/competitions/docvqa/ | 对于DocVQA数据来说,绝大部分的问题答案都是作为文本片段存在于文档文本中的,所以主流的方法都将其建模为了机器阅读理解问题。通过为模型提供视觉特征和文档文本,模型根据问题在给定的文档文本上进行文本片段的抽取来作为问题答案。 |
| InfographicVQA(2021) | InfographicVQA | https://arxiv.org/abs/2104.12756 | |
| VisualMRC(2021) | VisualMRC: Machine Reading Comprehension on Document Images | https://arxiv.org/abs/2101.11272 | 对于VisualMRC数据集,问题的答案通常不蕴含在文档文本片段中,需要给出较长的抽象回答。因此,在这种情况下,可行的方法是使用文本生成式的方法生成问题的答案。 |
5.2 支持多种下游任务的通用预训练模型
以上针对特定任务的深度学习方法针对某一项文档理解任务上能够取得较好的性能,然而这些方法主要面临两个限制:
-
这些模型通常依赖于有限的标记数据,而忽视了挖掘大量无标注数据中的知识。对于文档理解任务尤其是其中的信息抽取任务来说,详细标注的数据是昂贵且消耗时间的。另一方面,由于富文本文档在现实生活的大量使用,存在着大量的未标注文档,而这些大量的未标注数据可以使用自监督预训练加以利用。
-
富文本文档不仅有大量的文本信息,同时也包含丰富的版面和视觉信息。已有的针对特定任务的模型由于数据量的限制,通常只能通过预训练的CV模型或NLP模型来获取对应模态的特征,而且大部分工作只利用了单一模态的信息或者是两种特征的简单组合而不是深度交互。
Transformer在迁移学习领域的成功证明了 深度上下文化(Contextualizing) 对于序列建模的重要性,因此将文本和其他模态进行深度交互融合是一个较为明显的趋势。
富文本文档主要包含三种模态信息:文本、布局以及视觉信息,并且这三种模态在富文本文档中有天然的对齐特性。因此,如何对文档进行建模并且通过训练达到跨模态对齐是一个重要的问题。
| 模型(年份) | 论文名称 | 链接 | 介绍 |
|---|---|---|---|
| LayoutLM(2020) | LayoutLM: Pre-training of Text and Layout for Document Image Understanding | https://arxiv.org/abs/1912.13318 | 对文档进行建模并且通过训练达到跨模态对齐 |
| LayoutLMv2(2021) | LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding | https://arxiv.org/abs/2012.14740 | LayoutLM在预训练过程中没有引入文档视觉信息,从而在DocVQA这类需要较强视觉感知能力的任务上效果欠佳。针对这一问题,LayoutLMv2通过将视觉特征信息融入到预训练过程中,大大提高了模型的图像理解能力。引入了空间感知自注意力机制,并将视觉特征作为输入序列的一部分。在预训练目标方面,在掩码视觉语言模型之外又提出了文本-图像对齐和文本-图像匹配任务。通过在这两方面的改进,模型对于视觉信息的感知能力大大提高。 |
| LayoutXML(2021) | LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding | https://arxiv.org/abs/2104.08836 | LayoutLM针对英文建模,对于非英语世界来说文档理解任务同样重要,LayoutXML的提出解决了这一问题。基于LayoutLMv2的模型结构,通过使用53种语言进行预训练,扩展了LayoutLM的语言支持。与此同时,相比于纯文本的跨语言模型,LayoutXML在迁移能力上有明显的优势,这证明了不仅多语言文本之间可以进行跨语言学习,多语言富文本文档之间的还可以进行文档布局的迁移学习。 |
| LAMBERT(2020) | LAMBERT: Layout-Aware (Language) Modeling for information extraction | https://arxiv.org/abs/2002.08087 | 基于LayoutLM进行改进,通过使用RoBERTa作为预训练初始化获得了更好的性能。 |
| BROS(2020) | BROS: A Pre-trained Language Model for Understanding Texts in Document | https://openreview.net/forum?id=punMXQEsPr0 | 基于LayoutLM进行改进,在引入区域掩码训练的同时在编码器阶段加入了文本空间位置信息,提高了模型对空间位置感知能力。 |
| StructuralLM | Structurallm: Structural pre-training for form understanding | https://arxiv.org/abs/2105.11210 | 通过文本块内共享相同的位置信息并在预训练阶段引入位置信息预测的方式,也让模型具有一定的位置感知能力。 |
| LAMPRET(2021) | LAMPRET: Layout-Aware Multimodal PreTraining for Document Understanding | https://arxiv.org/abs/2104.08405 | 通过为模型提供更多的模态信息如字体字号、插图等,对网页文档进行建模,并结合多种层次化的预训练任务来增强模型对文本和图片的理解能力。 |
| SelfDoc(2021) | SelfDoc: Self-Supervised Document Representation Learning | https://arxiv.org/abs/2106.03331 | 通过在输入阶段使用文档实体目标作为输入,结合模态适应的注意力机制,提升了模型的模态交互能力。 |
| DocFormer(2021) | DocFormer: End-to-End Transformer for Document Understanding | https://arxiv.org/abs/2106.11539 | 通过引入了更高清的图片输入以及图像重构的预训练任务,更加充分地利用了图像信息,从而提高了模型性能。 |
| TILT(2021) | TILT: A GDPR-Aligned Transparency Information Language and Toolkit for Practical Privacy Engineering | https://dl.acm.org/doi/10.1145/3442188.3445925 | 使用Encoder-Decoder范式,着眼于扩展模型的语言生成能力。通过将Layout编码层引入T5模型并结合文档数据预训练,使模型能够处理文档领域的生成任务。 |
| VisualMRC(2021) | VisualMRC: Machine Reading Comprehension on Document Images | https://arxiv.org/abs/2101.11272 | 在文档视觉问答任务微调阶段在T5和BART模型的基础上引入文本位置编码,来帮助模型理解并生成问题答案。 |
6. 结语
以LayoutLM为代表的大规模自监督通用文档智能预训练模型也越来越多地受到人们的关注和使用,逐步成为构建更为复杂算法的基本单元,后续研究工作也层出不穷,促使文档智能领域加速发展。
展望未来,
- 解决文档多页跨页、训练数据质量参差不齐、多任务关联性较弱以及少样本零样本学习等问题。
- 应该特别关注文字检测识别OCR技术与文档智能技术的结合,因为文档智能下游任务的输入通常来自于自动文字检测和识别算法,文字识别的准确性往往对于下游任务有很大的影响。
- 如何将文档智能技术与现有人类知识以及人工处理文档的技巧相结合,也是未来值得探索的一个研究课题。