正如你在上一个视频中所看到的,大型语言模型(LLMs)是复杂的,而像Rouge和BLEU分数这样的简单评估指标只能告诉你关于模型能力的一些信息。
为了更全面地衡量和比较LLMs,你可以利用预先存在的数据集和相关基准,这些基准是由LLM研究人员专门为此目的而建立的。
选择正确的评估数据集至关重要,这样你才能准确评估LLM的性能并了解其真正的能力。
你会发现,选择隔离特定模型技能的数据集非常有用,例如推理或常识知识,以及关注潜在风险的数据集,如虚假信息或版权侵权。
一个重要的问题是,模型在训练期间是否见过你的评估数据。通过在模型之前没有见过的数据上评估其性能,你将获得更准确和有用的模型能力感知。
基准测试,例如GLUE、SuperGLUE或HELM,涵盖了广泛的任务和场景。

他们通过设计或收集测试LLM特定方面的数据集来实现这一目标。
GLUE,General Language Understanding Evaluation即通用语言理解评估,于2018年推出。GLUE是一组自然语言任务,如情感分析和问题回答。GLUE的创建是为了鼓励开发能够在多个任务之间进行泛化的模型,并且你可以使用该基准来衡量和比较模型的性能。
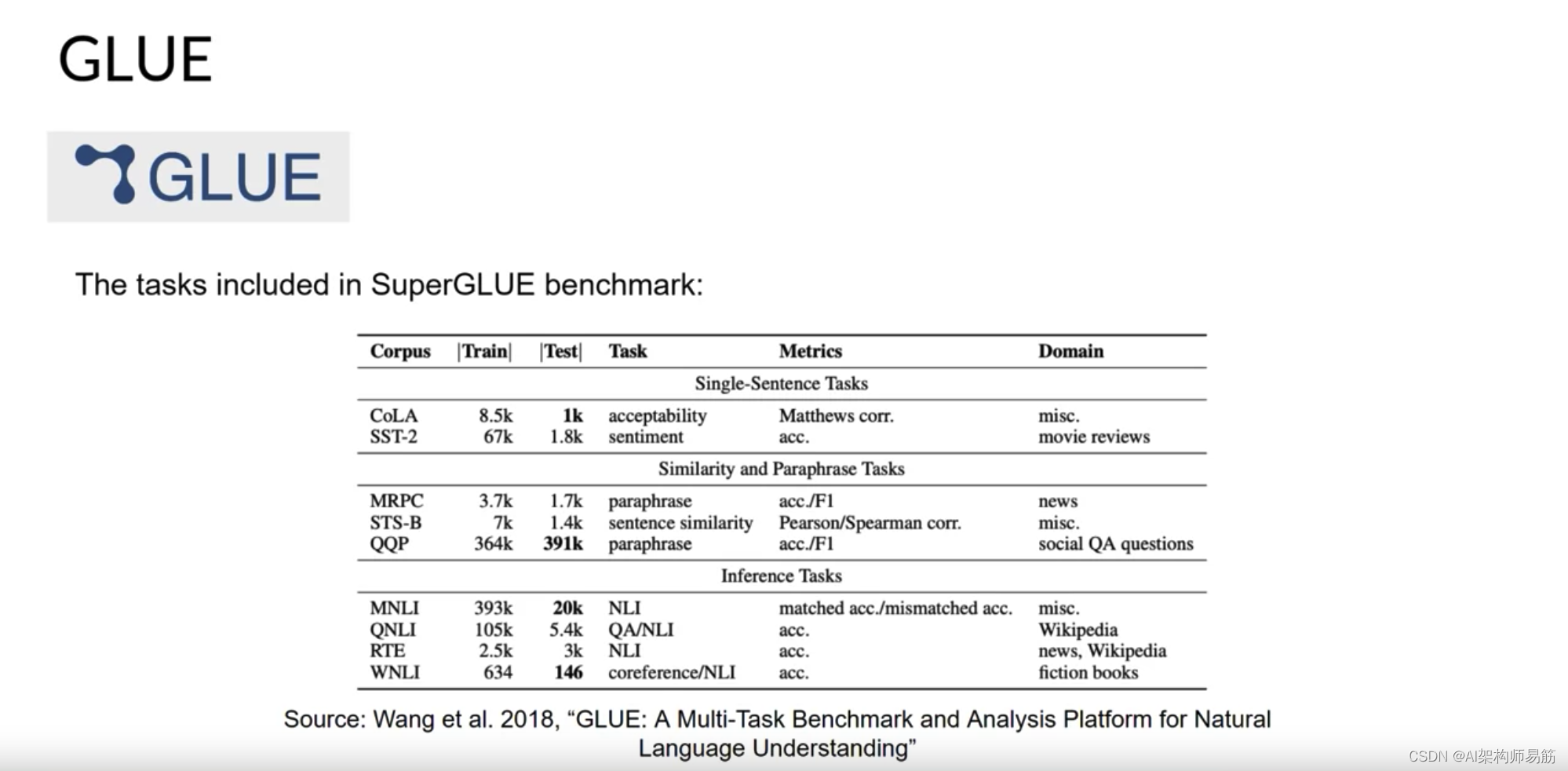
作为GLUE的继任者,SuperGLUE于2019年推出,以解决其前身的局限性。它包含一系列任务,其中一些不包括在GLUE中,而另一些是相同任务的更具挑战性的版本。SuperGLUE包括多句推理和阅读理解等任务。
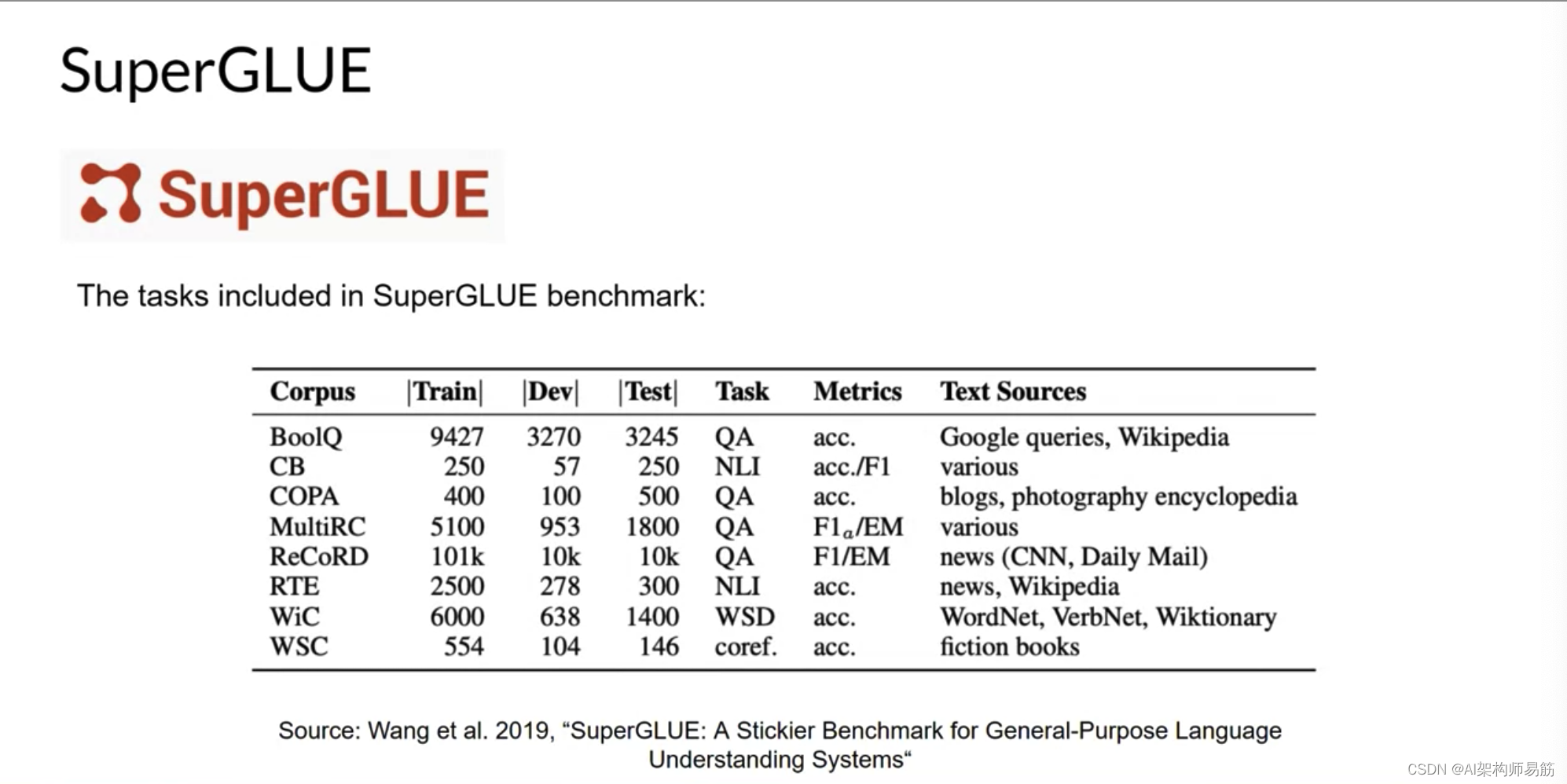
GLUE和SuperGLUE基准测试都有排行榜,可用于比较和对比评估的模型。结果页面是追踪LLM进展的另一个重要资源。随着模型越来越大,它们在SuperGLUE等基准测试上的表现开始与特定任务上的人类能力相匹配。

也就是说,模型能够在基准测试上的测试中表现得与人类一样好,但主观上我们可以看出,它们在一般任务上的表现还不如人类。

实际上,LLMs的新兴属性与旨在测量它们的基准测试之间存在一种竞争关系。
以下是一些最近的基准测试,这些基准测试正在推动LLMs的进一步发展。
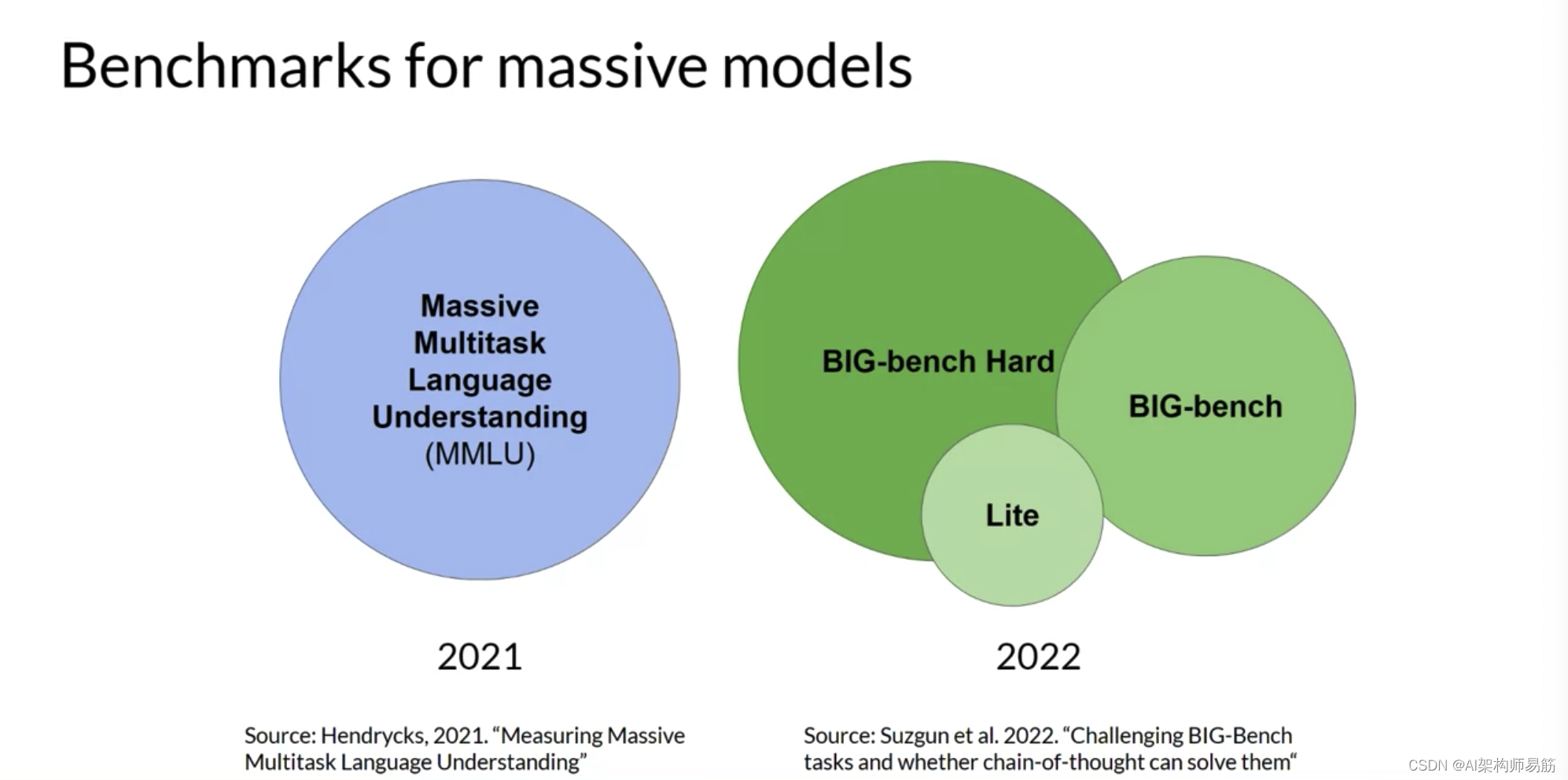
Massive Multitask Language Understanding(MMLU)专为现代LLMs设计。要表现出色,模型必须具备广泛的世界知识和问题解决能力。模型在初等数学、美国历史、计算机科学、法律等方面进行测试。换句话说,这些任务远远超出了基本语言理解的范围。

BIG-bench目前包含204个任务,涵盖语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等领域。BIG-bench有三个不同的大小,部分原因是为了保持可实现的成本,因为运行这些大型基准测试可能会产生大量的推理成本。
你应该了解的最后一个基准是Holistic Evaluation of Language Models(HELM)。HELM框架旨在提高模型的透明度,并为特定任务的良好表现提供指导。HELM采取多指标方法,在16个核心场景中测量七个指标,确保模型和指标之间的权衡得以清楚暴露。
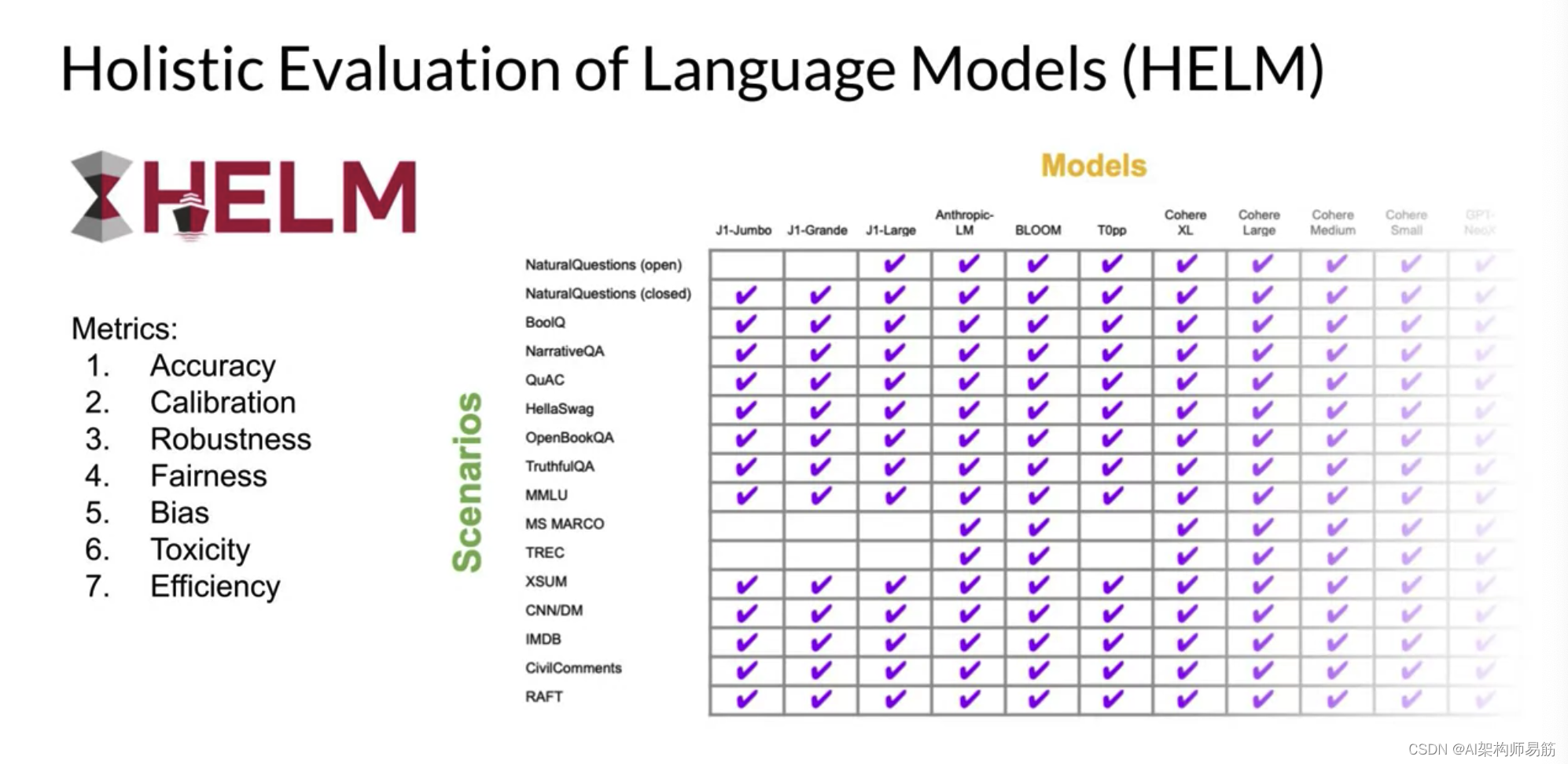
HELM的一个重要特点是,它在基本准确度度量之外还评估了其他指标,如精度和F1分数。该基准还包括公平性、偏见和有害性等度量标准,

这些度量标准在LLMs变得更加具备类似人类语言生成的能力并且因此可能表现出潜在有害行为的情况下,正在变得越来越重要。HELM是一个活跃的基准,旨在不断随着新场景、指标和模型的添加而发展。你可以查看结果页面,浏览已评估的LLMs,并查看与你项目需求相关的分数。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/1OMma/benchmarks