sinGAN: Learning a Generative Model from a Single Natural Image
论文地址:
https://arxiv.org/abs/1905.01164
代码地址:
https://github.com/tamarott/SinGAN
sinGAN ppt及ppt文案:
https://download.csdn.net/download/qq_41967539/11983573
论文翻译:
http://www.dataguru.cn/article-15165-1.html
以下是参考上面的网页,加上个人理解对这篇paper的解读:
SinGAN: Learning a Generative Model from a Single Natural Image
简述:
本文选自ICCV 2019,也是这次会议的BEST PAPER,我将按照文章的顺序进行讲解。
目前,Uc-GAN在特定单一的数据集上(比如人脸等)已经取得了很大的成功,但在多类别,高度多样化的数据集(如image net)仍是一项重大的挑战。
问题or相关工作:
下面介绍本文与其他GAN网络的3个不同点:
第一个是单幅图像:最初提出的单幅自然图像训练模型internal GAN,其生成的样本仅取决于输入图像(从图像到图像),并不能随机绘制样本,而本文框架是生成式的(从噪音到图像),因此适合多种图像任务。
第二个是纹理问题:目前UC-GAN仅对有纹理的图像进行研究,当图像无纹理时,不会产生有意义的样本,而本文不限于纹理,可以处理一般的自然图像。如下图,sinGAN与单调纹理生成模型的结果对比。当运用在自然图像时,sinGAN包含了复杂纹理和非重复的全剧结构,而另一个完全没有全局的结构。
第三个是图像的多尺度信息:目前所有的GAN几乎都是在特定的数据集训练的,并需要另外的输入信号调整生成,本文不关注同一类图像间的共同特征,而是考虑单幅自然图像的多尺度重叠影响块。
模型:
下面是sinGAN的网络框架,其中生成器{G0 . . . GN},训练图像金字塔{x0, . . . , xN},和噪声{Z0 . . . ZN}其中xN是单一输入图像的下采样版本,采样因子是rn(r > 1),每个生成器GN负责生成对应xN的图像xn˜。这个多尺度框架是卷积神经网络提取特征的逆过程,在目标检测使用多尺度框架时,先提取全局特征,feature map最大,感受野最小,后提取语义信息,但本文的多尺度是刚好相反的,最粗的一层是feature map最小,提取的语音信息,忽略全局信息。在sinGAN中,生成和判别都是从粗到细进行的,在每一个尺寸上,随着金字塔的上升,感受野尺寸减少(黄色区域),GN的输入是随机噪声ZN和来自上一尺度的生成图像xn˜并上采样到当前分辨率(除了最低尺度)。
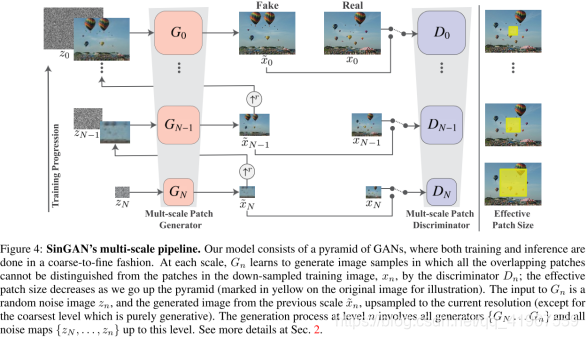
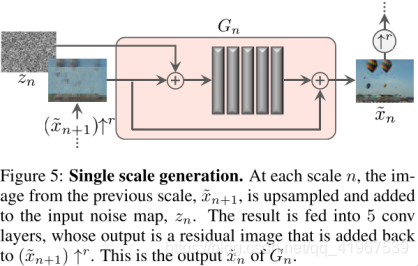
下面这个图是生成器结构,这句话在文章公式3的上面,意思是这5层卷积层生成(xn˜+1) ↑r中缺少的细节,具体框架由3×3卷积层-BN层-LeakyReLU组成的5层全卷积网络组成,最粗的尺度选用32个卷积核(也就是输出的通道数为32个),然后每4个尺度增加两倍,因为生成器是全卷积的,所以在测试时,通过改变噪音z的维度或分布可以以任意尺寸和横纵比生成图像。
下面通过对公式的解释再解读一下这个网络。在最粗的尺寸下,是纯生成过程,即Gx将空间高斯白噪声ZN映射为一个图像样本xn˜,如公式1。
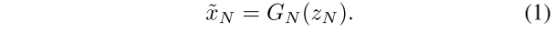
这一尺度有效感受野是图像高度的1/2,此时GN可以生成图像的整体布局和目标的全局结构,当随着金字塔的上升,更细的每个生成器为模型添加之前尺度下没有生成的细节,除空间噪声z外,每个GN还接受上一层图像的上采样版本作为输入,如公式2。
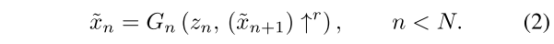
生成器的结构ψn如图5,刚才已经讲过了,可以从图中看出,先将上一层上采样后的xn+1˜和zn经过5个卷积层之后再和xn+1˜相加输出xn˜,如公式3。
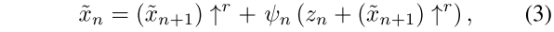
LOSS:每个GAN训练好,就会被固定,第n个GAN的训练损失包括了对抗损失Ladv和重建损失Lrec:
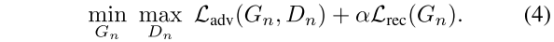
对抗损失,在每个生成器G都对应一个马尔科夫判别器Dn,来判断真假,我在这大概说一下为什么选择马尔科夫判别器?在文中2. Method中讲到了,这个判别器具有较小的感受野和性能的限制,阻止他们记忆单一图像,这样每个Dn仅负责捕捉他们对应的Xn的不同尺度。同时这里的对抗损失选用WGAN-GP loss,用来增加训练稳定性,最终判别分数是patch D判别图谱的平均值,并说明了Dn的网络结构与图5中ψn的结构相同。另一个LOSS是重建损失,为了确保模型存在可以生成原始图像的特定噪声图谱集合,作者对z进行了规定z的一个集合,{zrec N , zrec N−1 . . . , zrec 0 } = {z∗, 0, . . . , 0},其中最初的那一层规定z为z*,z是一些规定的噪声图谱,除了最粗的那一层,其他的z对重建损失的影响为0,对于n<N,也就是除了金字塔最低端之外的其他重建损失,见公式5,
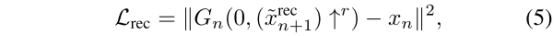
对于最底层损失,去掉了前一层的影响,公式中的变量只有z:
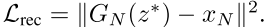
成果:
实验部分作者分别采取了定性与定量两方面来评估模型的好坏。
定量:
整体效果
图像有着新的真实结构和目标构造,也保存了训练图像的内容信息,取得了不错的效果,模型成功地保存了全局目标结构,比如下图中的热气球和金字塔。同样,还有精细的纹理信息,因为网络有限的感受野,使得网络生成了一些图像块的新连接,这些连接根本不存在于原图中,但进一步的观察发现,很多图片的反射和阴影都生成的很真实。

高分辨率图像
右上角243×1024是生成的图像。

在测试中的尺度影响
作者分别测试了训练过程和测试过程中尺度的影响,得出这样的结论。测试时,从粗糙层开始,n=N,斑马全局结构发生了巨大的变化,可以看到斑马有很多条腿。当从精细层开始,能保持住全局的结构信息,只改变了部分精细的图片特征,比如斑马的斑纹。

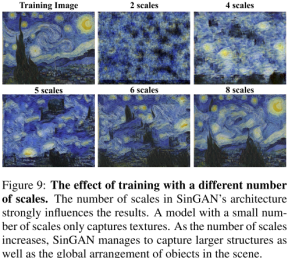
在训练中尺度的影响
训练时,在小尺度下(意味着本身就从一个很细化的patch开始训练),粗糙层的有效感受野很小,有助于捕获精细的纹理信息,随着尺度增加,结构信息和全局的布置都保存的很好。
定性:
1.Amazon Mechanical Turk (AMT) perceptual study
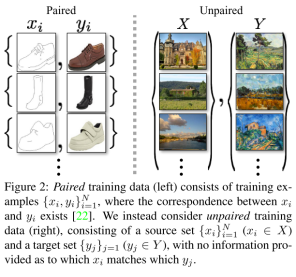
Cycle-GAN中解释的paired和unpaired的区别:
下图中,成对(paired)训练数据(左)由训练前元{xi, yi}N i=1组成,其中xi与yi之间存在对应。我们考虑的是未配对(unpaired)的训练数据(右),它由一个源集{xi}N i=1 (xi∈X)和一个目标集{yj}j=1 (yj∈Y)组成,没有提供关于哪个xi匹配哪个yj的信息。
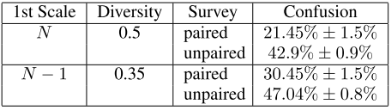
人类分辨的混合率越高,图像越真实。可以看出来sinGAN可以生成很真实的样本,判别率很高。
在不成对的图像对上,分不清楚的结果占比明显较大,也有进一步说明,困惑率与生成多样性图像有关;当图像的结构发生巨大的变化时,真实图像和生成的图像很难辨识。
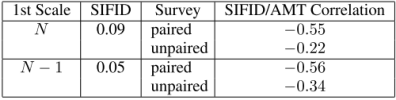
2.Single Image Fr´echet Inception Distance
table 2的结果显示,随着尺度的增加(由下往上),SIFID是变小的,说明越往上,越逼真;同样作者记录了SIFID与AMT两者的相关性,发现两者有着强的负相关性,FIFID分数越小,困惑越大,这表明两者都是为了得到最好的结果而共同协作的。
Application:

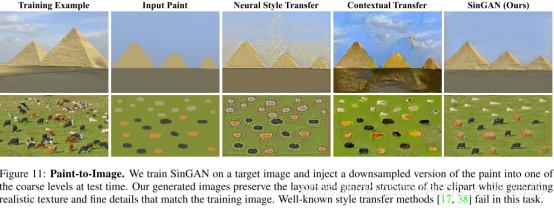
Paint-to-Image(油漆到现实):
将一副剪贴画转化成一副类似真实图片的图像,怎么做的呢?如下图展示的那样,将剪贴画下采样,作为某个粗糙层(N-1,N-2)的输入。因为图像SinGAN保留画的全局结构,然后只要纹理和高频信息与原图一致,就能产生具有真实特征的图像。对比于其他几种图像风格转移的方法,就图像的质量而言,得到的结果是最好的。
Editing(编辑图中某一位置):
通过对原图像部分区域的图像进行复制和粘贴的方式,对图像进行修改。和Harmonization的方法类似,通过这种方式,重新生成的纹理和无缝嵌入粘贴的部分,取得的结果要比Photoshop’s Content-Aware-Move上的结果更好。

Harmonization(协调一个新对象生成新图像):
如何将一个粘贴过来的图像与背景图混合,还能得到不错的结果?先训练一张背景图,然后在测试时,注入粘贴的部分,得到最终的部分。为什么这样有用呢?因为模型把裁剪的注入目标的纹理和背景图的纹理进行匹配,在不同的尺度下,模型会在保留目标的结构和转移背景图的纹理之间取得一个好的平衡。

Super-Resolution(改变超分辨率):
通过因子s为输入的图像增加分辨率。怎么做的呢?先训练低分辨率图像,其中加入了一个重构损失,给了一个=100的权重,并且加入了金字塔尺度因子r。因为一些小结构倾向于在整个图的多个尺度反复出现,所以在测试时,作者通过因子r为低分辨率上采样,然后和噪声一起作为输入送到最后一个生成器中。之后反复重复上述步骤k次,最终得到高分辨率的图像。如下图所示,由SinGAN模型得到结果在图像质量上,在internal methods方法中,取得了最好的结果。同样在external methods取得最好的结果。有趣的是,在一系列的方法比较中,SRGAN这种external method虽然在NIQE(perceptual quality)的分数微微高于SinGAN,但是看上去不如SinGAN取得的效果。

Single Image Animation(单一图像动画化):
通过一张简单的图像,输出一段动画。怎么做到的呢?单一的一张图片,包含很多重复部分,在相同动态目标下的这一段时间内,揭示了不同的快照,就好像一群飞行的鸟的图像,就能揭示这只鸟的所有飞翔姿态。使用SinGAN模型,可以经历图形中所有目标表象的流形,可以通过一张简单的图像得到动态图像。作者发现,对于很多类型的图片,想要得到真实效果,要在z-space(噪声所在的空间)随机游走,以开始作为第一帧运用到所有的尺度上。
Conclusion:
模型可以学到很好的纹理信息,得到更加真实、难以区分的图像。但这个模型也不是十分完美的,它应用的场景主要针对内部学习,受限于语义。比如,当给出一张狗的图像,你得不到完全没有见过的新狗,只能得到更清晰的狗,或者其他样子的相同的狗,反正和目标图像的不同之处不是很突出。
