从单个RGB图像中学习3D手姿态估计
摘要:之前大部分的论文都是基于深度图像的。在本文中,我们提出了一种从常规RGB图像估计3D手姿势的方法。由于缺少深度信息,这项任务有很多的含糊之处。为此,我们提出了一个深度网络,在此之前学习网络隐式3D关节。与图像中检测到的关键点一起,该网络很好地估计了3D姿态。我们引入基于合成手模型的大规模3D手势数据集来训练所涉及的网络。在包括手语识别在内的各种测试集上进行的实验证明了在单色图像上进行3D手势估计的可行性。
关键词:深度网络;3D姿态;3D手势数据集
1.引言
手是人类的主要操作工具。因此,在空间中它的位置,方向和关节对于许多潜在的应用至关重要,例如机器人中的对象切换,演示学习,手语识别和手势识别,以及将手作为人机交互的输入设备。
单个图像的整个手的3D手势估计很困难,因为有很多含糊不清的关节点和严重的自我遮挡。因此,使用特定的传感设备,如数据手套或标记,这将应用限制在有限的情况下。此外,多台摄像机的使用严重限制了应用范围。而且,深度相机并不像普通彩色相机那样容易使用,它们只能在室内环境工作。
本文中,在不需要任何特殊设备的情况下,我们提出了一种从单色图像学习完整的3D手姿态估计的方法。为解决模糊问题,我们利用深层网络的能力从数据中学习合理的先验。 我们的整体方法由三个深度网络组成,这三个深度网络覆盖了通向3D姿势的重要的子任务;参见图1.第一个网络提供了一个手部分割来定位图像中的手。基于其输出,第二个网络在2D图像中定位手的关键点。第三个网络从二维关键点导出手的3D姿势,这是本文的主要贡献。特别是,我们引入规范的姿势表示来使此学习任务可行。
与人体三维姿态估计相比,另一个困难是数据的有限可用性。尽管人体姿态估计可以利用多个动作捕捉数据库,但几乎没有任何这种手动数据。为了训练一个网络,需要一个具有地面真实3D关键点的大型数据集。由于没有足够可变性的数据集,我们创建了一个包含各种数据增强选项的综合数据集。
由此产生的手势估计系统在现有的小规模数据集上定性和定量地产生非常有希望的结果。我们还演示了使用3D手势进行手语识别的任务。数据集和我们训练有素的网络可在线获取。
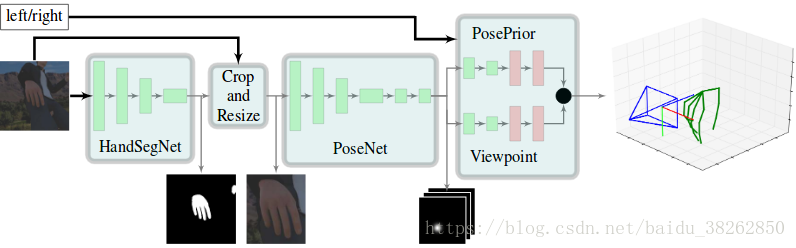
图1 我们的方法由三个构建块组成。首先,图像通过分割网络(HandSegNet)手部被定位出来。根据手模,输入图像被剪切出手部部分并作为PoseNet的输入。PoseNet输出各关键点的评分图。随后,PosePrior网络估计最有可能在评分图上制定的3D结构。此图用于说明总体结构,并不反映各个构建块的详细结构。
2.手姿势表示
给定一个单手的彩色图像,推断它的三维姿态。我们定义一组坐标去描述三维空间中J个关键点的位置,即在我们的例子中,J∈[1,21]。
从单一的二维观察推断三维坐标的问题已经解决。除了其他模糊之外,这里还有一个手的scale问题,即使是分割出手的部分再进行resize,手的大小也会对预测结果产生影响,所以我们利用食指的第一根手骨的长度对手节点位置进行正则化
(1)
还有一个问题是绝对坐标系的使用会给预测带来困难,所以本文采用了相对坐标系,以手掌节点的位置作为坐标原点对各个节点坐标进行平移
(2)
是手掌节点的坐标,我们设置=0。
3.3D手部姿势的评估
我们把单一的图像通过整个网络结构评估出手部的3D归一化坐标。按着图1显示的整个结构流程,下面的章节,我们描述各个组成部分的详细内容。
3.1用于手部分割的HandSegNet
对于手部分割,我们应用了一个基于Wei等人检测器并由其初始化的网络体系结构。他们将二维人体检测问题视为估计人体中心位置的分数图。最可能的位置被用作固定大小的切割图片的中心。由于手部尺寸在整个图像上急剧变化,并且很大程度上取决于清晰度,我们宁愿把手部定位视作分割问题。我们的HandSegNet是Wei等人的网络的一个较小的在我们的手部姿态数据集进行训练的版本。HandSegNet提供的手模允许我们裁剪和归一化输入图像的大小,这简化了PoseNet的学习任务。HandSegNet的大致结构如图2所示。
图2HandSegNet网络的网络架构。除输入和输出的手模外,表格的每一行都给出了网络的数据张量和产生它的操作。
图3除了输入,每一行表示网络的数据张量和产生它的操作。网络的输出是来自层17,24和31的预测分数图c。即输出三个张量
3.2用于得到关节点得分图的PoseNet
我们将2D关键点的定位视为二维评分图的估计。我们训练一个网络来预测J个评分图,其中每个得分图都包含某个关节点出现在某空间位置的可能性的信息。
类似于Wei等人的Pose网络,该网络使用一个编码器–解码器架构。给定由编码器产生的图像特征的表示,初始分数图被预测并且在分辨率中被连续地细化。我们用Wei等人结构的模型作为初始化权重,通过训练得到手部关节点检测的模型。PoseNet的大致结构如图3所示。
3.3用于3D手势预测的PosePrior
这部分应该是本文的核心。在得到了21个节点的分布热图后,如何推出3D位置信息是需要考虑的问题。当然,手部区域是多视角的,所以有必要先对手部区域的视角进行一下限制,从而使预测过程对视角有一定的不变性。论文中采用了坐标变换,利用两部分对视角的坐标变换进行估计,从而使得某一个特点的节点的z坐标为0。然后对左右手坐标进行了区分。所以这部分网络同时有了两个任务,一个是预测节点位置信息,一个是估计视角角度,这两个任务用了类似的网络框架。参见图4。他们首先使用ReLU非线性处理一系列6个卷积中的J个评分图。关于图像是左手还是右手的信息与特征表示连接在一起,并由两个完全连接的层进一步处理。两个网络结构都是以具有线性激活的完全连接层结束的,并且分别产生产生对视点R和典型坐标的估计。最后把两个预测结果进行融合得到最后的坐标。图PosePrior的大致结构如图5所示。
图4PosePrior的网络架构。两个几乎对称的流分别估计出规范坐标和相对于该坐标系的视点。两个预测的融合产生对相对标准化坐标的估计。
(3)
(4)
图5PosePrior网络的单个流的网络架构。除输入和输出,表格的每一行都给出了网络的数据张量和产生它的操作空间维度的减少是由于卷积中的跨步。P是估计参数的数量,并且对于视点估计P= 3,对于坐标估计流P= 63。
3.4网络训练
在训练过程中,三个网络部件应用不同的损失函数。HandSegNet使用标准softmax交叉熵损失,PoseNet使用损失。PosePrior网络使用到两个损失项。一个是基于预测结果和真实位置坐标的损失的平方,一个是对规范变换矩阵计算得到的损失的平方。
(5)
(6)
PosePrior网络的总损失函数是和的未加权总和。我们使用Tensorflow训练本文的结构。
3.5数据集
本文用到HandPose TrackingBenchmark数据集,它提供了每个样本的21个关节点的2D和3D标签。该数据集在6种不同背景和不同照明条件下显示一个人的左手。我们将数据集分成3000个图像(S-val)的评估集和15000个图像(S-train)的训练集。
4.实验
我们对整体方法的各部件做了实验:
(1)HandSegNet的实验过程如图6所示,
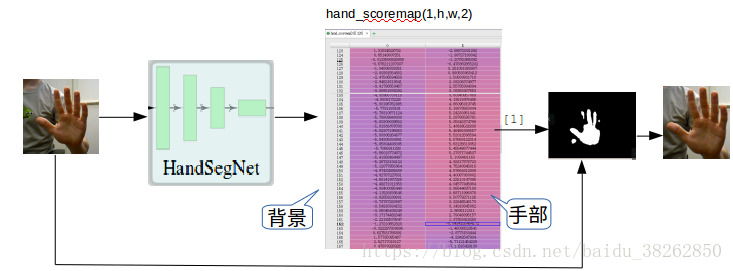
图6输入通过HandSegNet网络结构得到关于背景和手部上每个像素点的得分,再通过求最大值,二值化运算得到图上的手模。原图和手摸结合得到手部剪切图。
(2)PoseNet的实验过程如图7所示,
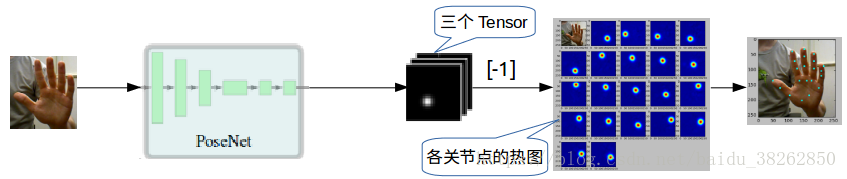
图7手部剪切图片输入PoseNet得到三个张量,每个张量都包含21个关节点的得分图。这三个张量可以理解为后一个张量是由前一个经过某些运算得到的关于关节点出现的位置更加精确的表示。选用精炼位置信息的最后一个张量,得分图上各个红色的点的位置便是剪切图片上手部关节点的坐标。图8分别显示了三个张量对应的手部关节点信息。
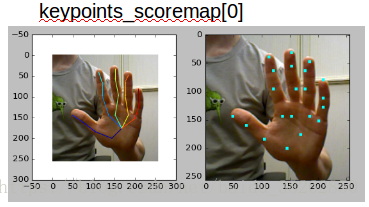
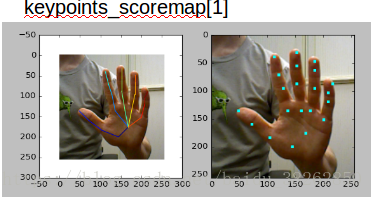
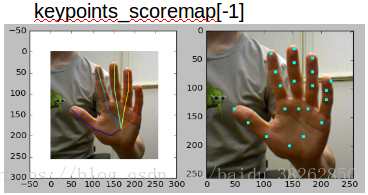
图8从上到下,由三张图的左半部分可以很明显的第三个张量的关节点的定位比其他两个张量的定位更精准。
(3)PosePrior的实验结果如图9所示,

图9 网络输入是彩色图像,信息是左手或右手。网络估计手部分割掩模,定位2D中的关键点并输出最可能的3D姿势。
5总结
本文从单个图像中估计出图像中的3D手势。实验已经证明,已经学习了3D姿势先验条件的网络可以从现实世界的图像上的2D关节点预测出合理的3D手势。虽然本文网络的性能与使用深度图的方法相比具有竞争力,但仍有很大的改进空间。性能似乎受限于缺少具有真实世界图像和多样姿势统计数据的带注释的大规模数据集。
6.参考文献
[1]ChristianZimmermann, Thomas Brox. Learning to Estimate 3D Hand Pose fromSingle RGB Images[J]. 2017:4913-4921.
[2]Shih-EnWei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. Convolutionalpose machines. In Proc. of the IEEE Conf. on Computer Vision andPattern Recognition (CVPR),pages 4724–4732,