markdown
motivation
理解从图片识别平面的网络,理解论文:
PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image 用于后续的工作。
论文序列
3) PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image
目标
单目相机的rgb图->rgb的图片中的平面


最近调研从图像中提取语义上的平面信息。比如冰箱或者墙面等等。
之前从研究的论文中,我们知道神经网络可以提取图片中的深度信息,平面信息从类似的角度也可以提取出来的。之前的方法获取平面都是神经网络直接回归三维平面的参数 a x + b y + c z ax+by+cz ax+by+cz的三个参数。但是这个方法的有一个缺陷就是必须给一个最大的平面的数量。这篇论文作用是平面的数量不在限制。 **它用的是MAKS-RCNN的变种直接对图片进行区域实例的方法,用于获取平面。**在此基础上进行网络分割,在进行平面的normal预测和depth 预测。用这两个信息融合获取三维平面。
为什么能通过rgb图像推测出3D平面信息?
本文的变化主要是用了区域检测框架,区域检测已经能够做到理解场景的局域了,利用检测出的区域,对于平面的区域直接获取。获取多个平面的mask。这个方法用的是MASK-RCNN的变种,这个实例区域检测的方法。它是不受区域检测的数量限制的。因为这个区域检测一般为比较粗造或者直接是box,所以分割方法直接对区域边界进行分割。所以分割的输入需要获取单幅图片的平面normal和depth,这些都是三维的,这是refine的步骤。跟原来的区域检测的平面进行融合。就能获取三维的平面。这个贡献点在于第一用区域检测来检测任意数量的平面。
网络的整体架构

前面的网络Plane detection network的主要的架构,BBOX,MASK用区域检测的算法,Normal都是用区域成熟的方法,可以直接回归normal,但是对于法向量的表达借用了Mask-RCNN的anchor的表示方式如下:
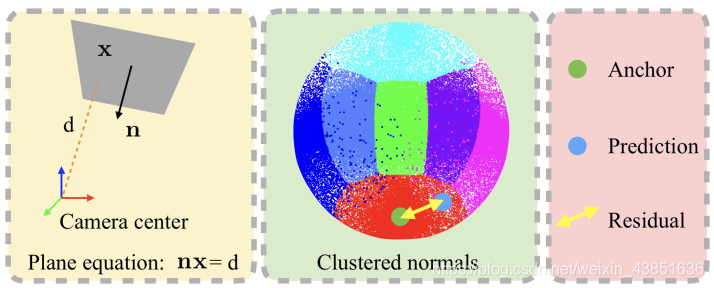
这是计算平面的normal。它的做法是选择一个Anchor的normal,直接回归3D的向量。这是一个normal表达方式。有7个方向区域组成。它用的是统计概念。对1000个图像平面的发向量进行统计和聚类,获取7个法向量的cluster。这样做会提高准确率,我没有明白为啥可以提高准确率?需要查看论文:Mask r-cnn。这是区域检测的非常重要的论文需要查看一下。
其中所说的变种就是对于网络的改进,称为Segment refined Network,就是将各个网络提取的mask没有直接conv然后concanate,而是将其它的plane mask通过卷积为特征,再将这个特征和其它(不包括自己)所有的特征均值concanate。这样就拥有了其它平面mask的特征。这样可以聚集非local的特征,这样效果更好。所以能看到下面的结构。
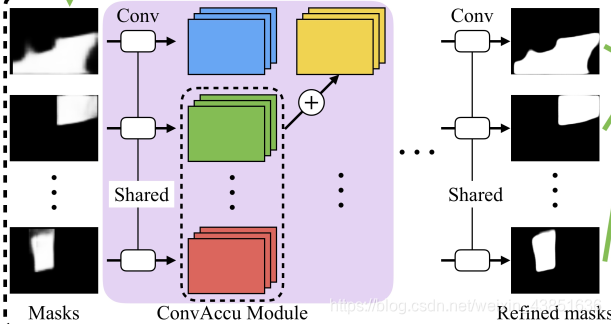
每个平面的mask都卷积。
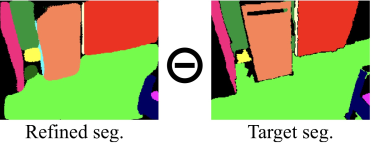
最后一个模块其实也是很简单,就是wraping loss 模块,这个模块就是别的视角来监督。就是将临近的视角wrap到自己的视角,然后直接相减
Loss 函数的设计

除了直接和ground truth进行相减。 如图:
还有和邻近视角的相减,如下:

其中 D n D^n Dn表示邻近视角的depth,其中 ( u w , v w ) (u^w, v^w) (uw,vw)都是warping后的结果,表示 ( u w , v w ) (u^w, v^w) (uw,vw)和 ( u n , v n ) (u^n, v^n) (un,vn)对应,这样就获取了对应的当前视角的depth,为 D w D^w Dw,将它们相差。
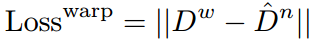
感想
这篇论文是多个模块的融合较多,主要是对各个模块的融合的改进。之前论文中的一些缺陷改进了:
1)表示的平面数量不再限制了。
2)能检测小平面(它的refine那一块中,及时融合了多个mask的信息)
3)利用了邻近的视角图片
缺陷:
1)融合了各个网络,形成的一个系统,同时对于网络改进较为简单。对于融合邻近的视角只是将它作为监督的loss。
可以对网络的各个平面都是通过区域检测,没有加入角点的检测,或则线段的检测,作为约束。可能这样融合对于曲线不够友好。
特征的融合都没有用crf的形式。
利用其它视角的图片比较简单,只是作为简单的loss函数融合,对于各个特征的融合特征太简单了。