解读Towards Unified Depth and Semantic Prediction from a Single Image(2)
今天继续分析这篇论文,
这篇论文首次把语义分割和深度估计结合起来,
We propose a unified framework to incorporate both global context from the whole image and local
prediction from regions, through which the consistency between depth and semantic information is
automatically learned through joint training.
这篇论文的方法思想已经讨论了,就得看一些实质性的东西
首先来看,这个网络的框架,
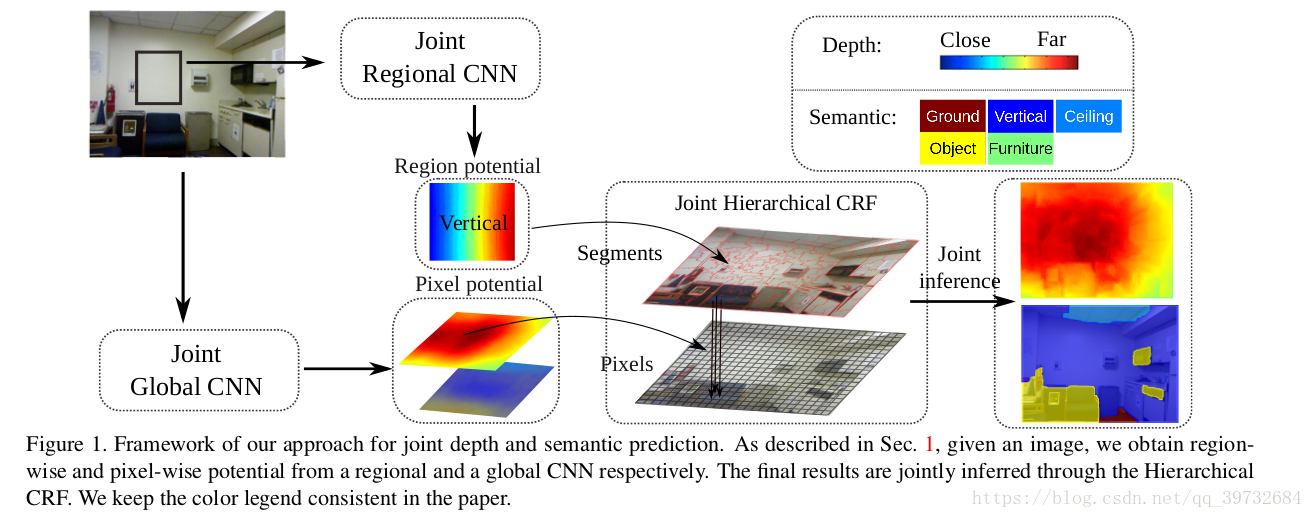
来看一下作者怎么介绍的:
1, We formulate the joint inference problem in a two-layer Hierarchical Conditional Random Field
(HCRF).
2, The unary potentials in the bottom layer are pixel-wise depth values and semantic labels,
which are predicted by a CNN trained globally from the whole image,
while the unary potentials in the upper layer are region-wise depth and semantic maps,
which come from another CNN based regressors trained on local regions.
3, The output of the global CNN, through coarse, provides very accurate global scale and
semantic guidance, while the local regressors give more details in depth and semantic
boundaries.
4, The mutual interactions between depth and semantic information are captured through
the joint training of the CNNs, and are further enforced in the joint inference of HCRF.
这四句话得花一些时间理解
而且,HCRF 究竟是一个什么东西呢,也必须科普一下,
在学习条件随机场的时候参考了三篇博文,
https://blog.csdn.net/a819825294/article/details/53893231
https://blog.csdn.net/u014688145/article/details/58055750
https://blog.csdn.net/DCX_abc/article/details/78319246
我在学习 PRML 的过程中接触到这部分内容,但是不太了解,还是要继续学习呀
