Title:SinGAN: Learning a Generative Model from a Single Natural Image
Code :PyTorch
From:ICCV2019
Note data:2019/11/19
Abstract:提出一个可以从单张自然图像学习的非条件性生成式模型SinGAN。
目录
Abstract
论文提出一种基于生成对抗模型的SinGAN;
网络结构:基于多个全卷积GAN组成的金字塔形式,每个全卷积GAN都负责学习图像中某个小块的数据分布;
创新:提出的SinGAN模型不仅可以学习图像中纹理,而且是非条件性模型,直接从噪声图像中学习,且可以应用到多种计算机视觉任务;
动机:解决计算机视觉中网络泛化能力不足,只解决单一任务等问题提出的一种无条件GAN模型。
本文将GANs的使用带入了一个新的领域——从单一的自然图像中进行无条件生成学习。
具体来说,利用单个自然图像中patch(小块、补丁)的内部统计信息去学习一个强大的生成模型。我们新的单一图像生成模型SinGAN允许我们处理包含复杂结构和纹理的一般自然图像,而不需要依赖于来自同一类别的图像的数据库。这是通过一个由全卷积的轻量级GANs组成的金字塔来实现的,每个GANs负责捕获不同规模的patch分布。一旦经过训练,SinGAN可以生成各种高质量的图像样本(任意维度),这些样本在语义上与训练图像相似,但包含新的对象配置和结构。

1 Introduction
生成对抗网络(GAN)在可视化数据的高维分布建模方面取得的巨大成功,在特定领域(超分,绘画,重定向)表现出优异的结果。但是,在捕获多种不同的类别组成的数据集的分布仍然是一种挑战。这篇论文将GANs的应用推向另一高度---从单一的自然图像中进行无条件生成学习。
模型利用单个图像中的patch的内部统计信息获得足够的信息来学习一个强大的生成模型。生成的模型允许处理包含复杂结构和纹理的一般自然图像,不依赖现在依靠数据集的堆积得到的最优结果。网络模型是一个由全卷积的轻量型GANs组成的金字塔结构,每个GANs负责捕获不同规模的patch分布。一旦经过训练,SinGAN就可以生成各种高质量的图像样本,这些样本在语义上与训练图像相似,但包含新的对象配置和结构。
论文展示了如何在一个简单的统一学习框架中使用SinGAN来解决各种图像处理任务,包括从单个图像到图像的绘制、编辑、协调、超分辨率和动画。在这些情况下,模型产生了高质量的结果,保持了训练图像的内部patch统计。所有的任务都是在相同的生成网络中完成的,没有任何额外的信息或原始训练图像之外的进一步训练。
2 Related Work
目前大多数的模型都是为特定任务而设计,只能特定的场景下有效。之前尝试的一些基于内部GAN的模型效果并不理想。这篇SinGAN,采用纯生成式,引入噪声映射到图像样本中,因而适用于多种计算机视觉任务。无条件的单图像GAN仅仅在纹理生成的环境中被研究过。当对非纹理图像进行训练时,这些模型不会生成均值样本。SinGAN强大之处在于其不局限于纹理,可以处理一般的自然图像。同时稍加修改就可以泛化到其他任务中,如 绘制,编辑, 融合, 超分辨, 动画化。
该模型另一强大之处在于,不依赖数据集,仅仅在一张图像上进行训练,没有任何限制。通过对单张图像下采样,得到多尺度图像,可以增加网络对不同尺度的感知和增大感受野。

3 Method
我们的目标是学习一个无条件生成模型,它可以捕获单个训练图像内部统计信息。这个任务在概念上与传统的GAN设定类似,只是这里的训练样本是单个图像的patch,而不是来自数据库的整个图像样本。
我们选择不局限于纹理生成,要能够处理更一般的自然图像。这需要在许多不同的尺度上获取复杂图像结构的统计信息。例如,我们希望捕获全局属性,例如图像中大型对象的排列和形状(例如顶部的天空,底部的地面),以及精细的细节和纹理信息。为了实现这一目标,我们生成框架下图所示,由层次性的patch -GANs (马尔科夫判别器)组成,每个patch -GANs负责捕捉不同尺度的patch分布。GANs的接受域小,容量有限,无法记住单个图像。而类似的多尺度体系结构已经在传统的GAN设定环境中得到了探索,SinGAN是第一个从单一的图像探索它的内部学习。

SinGAN的多尺度管道。模型由许多GANs组成一个金字塔,其中训练和推理都是以一种由粗到精的方式完成的。在每个尺度上,
学习生成图像样本,其中所有的重叠patch用判别器
无法从下采样训练图像
中的patch中识别出;当我们沿着金字塔向上移动时,有效的patch大小会减小(在原始图像上用黄色标记以作说明)。
,和生成的图像从之前的规模
, 向上采样到当前分辨率(除了纯生成的最粗级别)。第n级的生成过程涉及所有生成器{
,…,
3.1 多尺度结构
模型的构成是有几个生成器组成的金字塔结构。针对x的图像金字塔训练
,其中
是一个x的因子为
的下采样版本,r>1。每一个生成器
负责生成真实的图像样本,即对应图像中的patch分布
。这是通过对抗训练实现的,在训练中
尽可能的欺骗判别器
,它试图将生成的样本中的patch与
中的patch区分开。
图像样本的生成从最粗的尺度开始,依次通过所有生成器,直到最细的尺度,在每个尺度注入噪声。所有的生成器和判别器都有相同的接感受野,因此在生成过程中捕获的结构尺寸都在减小。在粗尺度上,这一代是纯生成,即映射空间高斯白噪声
到
.
这一层的有效接受域通常为图像高度的一半,因此生成图像的总体布局和对象的全局结构。每个更精细尺度上的生成器
(n < N)都添加了以前的尺度没有生成的细节。因此,除了空间噪声
外,每个生成器
还接受较粗尺度图像的上采样版本,即
所有的生成器都具有相似的架构,如下图所示。具体来说,噪音是添加到图像
被送入一个卷积序列层。这确保了GAN不会忽略噪声,就像随机条件规划中经常发生的那样。卷积层的作用是生成的遗漏的细节
(残差学习)。

单尺度的生成。在每个尺度n,图像从以前的规模
,上采样并添加到输入噪声映射
。这是
即执行操作 :
, 其中
是一个有着5个Conv(3×3)-BatchNorm-LeakyReLU卷积块。我们在最粗糙的尺度上从每个块32个内核开始,然后每4个尺度增加2倍。因为生成器是全卷积的,所以我们可以在测试时生成任意大小和宽高比的图像(通过改变噪声图的尺寸)。
3.2 训练
我们按顺序训练我们的多尺度体系结构,从最粗糙的尺度到最精细的尺度。一旦每个GAN被训练,它就会被固定下来。我们对第n个GAN的训练损失包括一个对抗性公式和一个重构公式:
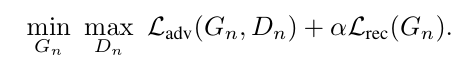
对抗的loss 惩罚patch之间的距离分布的
和patch的分布生成样本
。重构损失
保证了一组特定的噪声映射的存在,这些噪声映射可以产生
,这是图像处理的一个重要特征(第4节)。
对抗损失
每个生成器都与一个马尔可夫链判别器
耦合,该判别器将其输入的每个重叠的patch分类为真或假。使用WGAN-GP 损失来增加训练的稳定性,其中最终的判别分数是patch判别映射的平均值。相对于纹理的单图像GANs,在这里,我们定义整个图像的损失,而不是随机剪裁(批量大小为1),这允许网络学习边界条件(见补充资料),这是我们设定的一个重要特性。
的架构和包含
在内的网络
相同,所以它的patch大小(网络的接受域)是11×11。
重构的损失
我们要确保存在一组特定的输入噪声映射,生成原始图像x。我们具体选择
其中Z*是一些固定的噪声映射(绘制一次,在训练时保持固定)。当使用这些噪声图时,用表示在第n个尺度上生成的图像。对于n < N时,

对于n = N,我们使用
重建图像在训练中还有另一个角色,就是确定噪声
的标准差
在每一个尺度。具体地说,我们把
成比例的根均方误差(RMSE)——渐变
和
,它给出了在这个范围内需要添加的细节数量的指示。
4 Results
4.1 实验细节
论文对SinGAn进行了定性和定量的测试,包括城市和自然风景,以及艺术和纹理图像。使用(BSD)、Places和Web作为测试数据集。论文在在最粗糙的刻度处设置最小尺寸为25px,并选择刻度的数量N s.t,比例因子 r 尽可能接近 4/3。对于所有的结果,(除非另有说明),我们将训练图像调整为最大尺寸250px。
4.2 测试中的尺度数量的影响
多尺度体系结构允许通过选择在测试时开始生成的尺度来控制样本之间的变化量。为了从尺度n开始,我们修正了噪声映射到这个比例为,只对
做随机描绘。其效果如图所示。

从不同的尺度生成(在推理时)。我们展示了从给定的n级开始分层生成的效果。对于我们的完整生成方案(n = N),最粗糙级的输入是随机噪声。为了生成更小比例的n,我们插入向下采样的原始图像Xn作为该比例的输入。这使得我们可以控制生成结构的规模,例如,我们可以保持斑马的形状和姿势,只有从n = n−1开始生成才能改变其条纹纹理。
可以看出,在最粗糙的尺度上开始生成(n = N),全局结构有可能会发生较大变化。在某些情况下,一个大的突出的物体,如斑马图像的例子中,这可能导致生成不真实的样本。然而,从更细的尺度开始生成,就可以保持全局结构不变,而只改变更细的图像特征(例如斑马的条纹)。参见补充资料获得更多的例子。
4.3 训练中尺度数量的影响
下图显示了使用较少的尺度尺度数量的训练效果。用少量的尺度,在最粗糙的水平上有效的接受域更小,只允许捕获精细的纹理。随着尺度数量的增加,出现了更大的支撑结构,全局对象的排列得到了更好的保留。

使用不同数量的规模进行训练的效果。SinGAN架构中的规模数量对结果有很大的影响。只有少量比例的模型才能捕获纹理。随着规模数量的增加,SinGAN成功地捕捉到了更大的结构以及场景中物体的整体布局。
4.4 定量评价
为了量化生成图像的真实性以及它们如何捕获训练图像的内部统计数据,论文使用了两个指标:
- Amazon Mechanical Turk (AMT,亚马逊众包)“真实/虚假”用户研究;
- Frechet Inception距离的新单图像版本。
AMT感知研究(感性评价有点扯)
对两种类型的生成过程重复了这两个过程:从最粗糙的(N)尺度开始生成,从N -1尺度开始生成。为了量化生成图像的多样性,对于每个训练示例,我们计算每个像素超过100个生成图像的强度值的标准差(std),在所有像素上取平均值,然后根据训练图像的强度值的std进行标准化。真实的图片是从“places”数据库中随机选取的,来自山脉、丘陵、沙漠和天空的子类别。在这四个测试中,我们有50个不同的参与者。在所有测试中,前10个测试都是包含反馈的教程。结果见表。
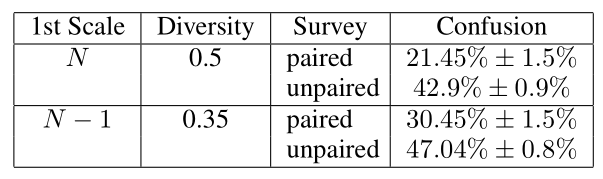
“真/假”AMT测试。报告了两个生成过程的混淆率:从最粗糙尺度N开始(生成具有大量多样性的样本),从第二个最粗糙尺度N - 1开始(保留原始图像的全局结构)。在每种情况下,我们都进行了配对研究(真-vs。-假图像对显示),和一个未配对的(无论是假或真图像显示)。方差由bootstrap估计。
在未配对的情况下,混淆的比例总是更大,因此没有可比性。此外,很明显,混淆率随着生成图像的多样性而降低。然而,即使改变了大型结构,我们生成的图像也很难与真实图像区分开来(50%的分数意味着完全混淆了真实图像和虚假图像)。完整的测试图像包含在补充资料中。
单幅图像Fréchet Inception Distance
量化SinGAN在多大程度上捕获了x的内部统计信息。GAN评价的一个常用指标是Frechet Inception Distance (FID),它测量生成图像的深度特征分布与真实图像的分布之间的偏差。然而,在我们的设置中,我们只有一个真实的图像,并且对它的内部patch统计非常感兴趣。因此提出了单图像FID (SIFID)度量。而不是使用激活向量
在Inception网络的最后一个池化层(每个图像一个向量)之后,我们在第二个池化层(图中每个位置一个向量)之前使用卷积层输出的深层特征的内部分布。我们的SIFID是真实图像和生成的样本中这些特征的统计数据之间的FID。
单图像FID(SIFID)。我们将FID指标应用于单个图像,并报告50幅图像的平均分,对于完整的生成(第一行),以及从第二个最粗糙尺度(第二行)开始。与AMT结果的相关性表明,SIFID与人类的排名高度一致。
从表中可以看出,规模N - 1生成的SIFID平均值低于规模N 生成的SIFID平均值,这与用户研究结果一致。我们还报告了SIFID分数和假图像的混淆率之间的相关性。请注意,这两者之间存在显著的(反)相关性,这意味着一个小的SIFID通常可以很好地指示出较大的混淆率。成对测试的相关性更强,因为SIFID是成对的措施(它作用于对,
)。
4 Applications
这部分探讨了SinGAN在许多图像处理任务中的应用。在训练后使用我们的模型,不进行架构更改或进一步调优,并对所有应用采用相同的方法。该思想是利用这样一个事实,即在推理时,SinGAN只能生成与训练图像具有相同patch分布的图像。因此,可以通过在n < N的某个尺度将图像(可能是向下采样的版本)注入到生成金字塔中,并通过生成器将其前馈传输,从而使其patch分布与训练图像的patch分布匹配,从而进行操作。不同的注入规模导致不同的效果。
5 Conclusion
本文介绍了一个新的非条件生成方案SinGAN,它是从一个单一的自然图像中学习来的。展示了它不仅限于纹理的学习能力,并为自然复杂的图像生成多样的真实样本。与外部训练的生成方法相比,内部学习在语义多样性方面存在固有的局限性。例如,如果训练图像包含一条狗,我们的模型将不会生成不同犬种的样本。不过实验证明,SinGAN可以为广泛的图像处理任务提供一个非常强大的工具。
