1. 概述
在概率论与统计学中,贝叶斯定理 (Bayes’ theorem) 表达了一个事件发生的概率,而确定这一概率的方法是基于与该事件相关的条件先验知识 (prior knowledge)。而利用相应先验知识进行概率推断的过程为贝叶斯推断 (Bayesian inference)
2. 贝叶斯定理
2.1 贝叶斯公式:
P ( h ∣ D ) = P ( D ∣ h ) P ( h ) P(h|D)=\frac{P(D|h)}{P(h)} P(h∣D)=P(h)P(D∣h),
D是{“咳嗽”,“味觉消失”,“发烧”},h是“得了新冠”。
- P(h): 得了新冠的先验概率
- P(D): 出现症状{“咳嗽”,“味觉消失”,“发烧”}的先验概率
- P(h|D): 得了新冠的后验概率 ,即在出现症状这个事件发生之后,对“得了新冠”事件概率的重新评估。
- P(D|h): 似然度 likelihood,实际经常取log,因为概率相乘会非常小。
先验概率:是指现有数据根据以往的经验和分析得到的概率
后验概率:事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小
2.2 极大后验假设(Maximum A posteriori)
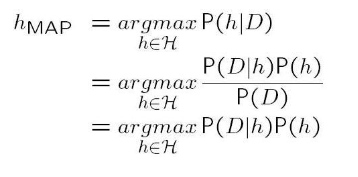
可以看到第二个等式到第三个等式时,忽略了分母上的先验概率P(D):

2.3 极大似然假设(Maximum Likelihood)
h M L = arg max h ∈ H P ( D ∣ h ) h_{ML} = \argmax_{h \in H} P(D|h) hML=h∈HargmaxP(D∣h)
其中,h为标签,D为样本特征。
可见,在极大似然假设中,也忽略了先验概率P(h). 当P(h)未知或者等概率的时候可以这样做。
*2.3.1 maximum likelihood 和 Least square error 等价
设有n个样本 { x 1 , x 2 , . . . x n } \{x_1, x_2,... x_n\} {
x1,x2,...xn},它们的真实标签值为 { d 1 , d 2 , . . d n } \{d_1,d_2,..d_n\} {
d1,d2,..dn}. 使用函数 h ( x ) h(x) h(x)来拟合,它是一个无噪音的目标函数。
假设噪音 e i e_i ei是独立的随机变量,符合正态分布 N ( 0 , σ 2 ) N(0,\sigma^2) N(0,σ2), 那么有:
d i = h ( x i ) + e i d_i = h(x_i)+e_i di=h(xi)+ei

d i d_i di也服从正态分布 N ( f ( x i ) , σ 2 ) N(f(x_i),\sigma^2) N(f(xi),σ2)
那么,第 i 个样本的标签为 d i d_i di的概率 P ( d i ∣ x i ) = 1 2 π σ 2 e − ( d i − h ( x i ) ) 2 2 σ 2 P(d_i |x_i) = \frac{1}{\sqrt{2\pi \sigma^2}}e^{-\frac{(d_i-h(x_i))^2}{2\sigma^2} } P(di∣xi)=2πσ21e−2σ2(di−h(xi))2
所有样本标签为 { d 1 , d 2 , . . d n } \{d_1,d_2,..d_n\} {
d1,d2,..dn}的概率为:
∏ i P ( d i ∣ x i ) = ∏ i 1 2 π σ 2 e − ( d i − h ( x i ) ) 2 2 σ 2 \prod_i P(d_i|x_i) =\prod_i \frac{1}{\sqrt{2\pi \sigma^2}}e^{-\frac{(d_i-h(x_i))^2}{2\sigma^2} } i∏P(di∣xi)=i∏2πσ21e−2σ2(di−h(xi))2
取对数,得到:
∑ i [ l n ( 1 2 π σ 2 ) − ( d i − h ( x i ) ) 2 2 σ 2 ] \sum_i [ln(\frac{1}{\sqrt{2\pi \sigma^2}})-\frac{(d_i-h(x_i))^2}{2\sigma^2}] i∑[ln(2πσ21)−2σ2(di−h(xi))2]
最大似然法就是要取一个合适的函数h(x)来最大化这个概率,即:
h M L = arg max h ∈ H ∑ i [ l n ( 1 2 π σ 2 ) − ( d i − h ( x i ) ) 2 2 σ 2 ] = arg min h ∈ H ∑ i = 1 m ( d i − h ( x i ) ) 2 h_{ML} = \argmax_{h \in H}\sum_i [ln(\frac{1}{\sqrt{2\pi \sigma^2}})-\frac{(d_i-h(x_i))^2}{2\sigma^2}] \\ = \argmin_{h \in H} \sum_{i=1}^m (d_i - h(x_i))^2 hML=h∈Hargmaxi∑[ln(2πσ21)−2σ2(di−h(xi))2]=h∈Hargmini=1∑m(di−h(xi))2
所以,极大似然和最小均方误差等价的充要条件是:误差满足正态分布。
3. 朴素贝叶斯分类器
h M A P = arg max h i ∈ H P ( D ∣ h i ) P ( h i ) h_{MAP} = \argmax_{h_i \in H} P(D|h_i)P(h_i) hMAP=hi∈HargmaxP(D∣hi)P(hi)
在这个例子中, h i h_i hi为{得了新冠,没得新冠}, D为有无症状{“咳嗽”,“味觉消失”,“发烧”}.
朴素贝叶斯假设:
P ( D ∣ h i ) = P ( d 1 , d 2 , . . . d n ∣ h i ) = ∏ j P ( d j ∣ h i ) P(D|h_i) = P(d_1,d_2,...d_n|h_i) = \prod_j P(d_j|h_i) P(D∣hi)=P(d1,d2,...dn∣hi)=∏jP(dj∣hi)
就是对条件概率分布做了独立性的假设,假设自变量之间的独立。
朴素贝叶斯分类器:
h N B = arg max h i ∈ H P ( h i ) ∏ j P ( d j ∣ h i ) = arg max h i ∈ H { l o g P ( h i ) + ∑ i l o g P ( d j ∣ h i ) } h_{NB} = \argmax_{h_i \in H} P(h_i) \prod_j P(d_j|h_i)\\ ~~ = \argmax_{h_i \in H} \{logP(h_i)+\sum_i logP(d_j|h_i)\} hNB=hi∈HargmaxP(hi)j∏P(dj∣hi) =hi∈Hargmax{
logP(hi)+i∑logP(dj∣hi)}
取log是为了防止连乘导致的数据太小,产生误差。取log之后变成了加法,解决了这个问题。
4. Sklearn实现
在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
MultinamialNB这个函数,只有3个参数:alpha(拉普拉斯平滑),fit_prior(表示是否要考虑先验概率),和class_prior:可选参数
MultinomialNB一个重要的功能是有partial_fit方法,这个方法的一般用在如果训练集数据量非常大,一次不能全部载入内存的时候。这时我们可以把训练集分成若干等分,重复调用partial_fit来一步步的学习训练集,非常方便。
5. 面试题
单词纠错
经常在网上搜索东西的朋友知道,当你不小心输入一个不存在的单词时,搜索引擎会提示你是不是要输入某一个正确的单词,比如当你在Google中输入“computet”时,系统会猜测你的意图:是不是要搜索“computer”,如下图所示:

Q: Google的拼写检查基于贝叶斯方法。请说说的你的理解,具体Google是怎么利用贝叶斯方法,实现"拼写检查"的功能。
A: 用户输入一个单词时,可能拼写正确,也可能拼写错误。如果把拼写正确的情况记做c(代表correct),拼写错误的情况记做w(代表wrong),那么"拼写检查"要做的事情就是:在发生w的情况下,试图推断出c。换言之:已知w,然后在若干个备选方案中,找出可能性最大的那个c,也就是求 P ( c ∣ w ) P(c|w) P(c∣w)的最大值。
而根据贝叶斯定理,有:
P ( c ∣ w ) = P ( w ∣ c ) P ( c ) P ( w ) P(c|w) = \frac{P(w|c)P(c)}{P(w)} P(c∣w)=P(w)P(w∣c)P(c)
由于对于所有备选的c来说,对应的都是同一个w,所以它们的P(w)是相同的,因此我们只要最大化 P ( w ∣ c ) P ( c ) P(w|c)P(c) P(w∣c)P(c)即可。其中:
- P ( c ) P(c) P(c)表示某个正确的词的出现"概率",它可以用"频率"代替。如果我们有一个足够大的文本库,那么这个文本库中每个单词的出现频率,就相当于它的发生概率。某个词的出现频率越高, P ( c ) P(c) P(c)就越大。比如在你输入一个错误的词“computet”时,系统更倾向于去猜测你可能想输入的词是“computer”,而不是“computeo”,因为“computer”更常见。
- P ( w ∣ c ) P(w|c) P(w∣c)表示在试图拼写c的情况下,出现拼写错误w的概率。为了简化问题,假定两个单词在字形上越接近,就有越可能拼错,P(w|c)就越大。举例来说,相差一个字母的拼法,就比相差两个字母的拼法,发生概率更高。值得一提的是,一般把这种问题称为“编辑距离”。
所以,我们比较所有拼写相近的词在文本库中的出现频率,再从中挑出出现频率最高的一个,即是用户最想输入的那个词。