本文翻译和精简自 Stanford cs224n lec 07.
1. 梯度消失和梯度爆炸
1.1 梯度消失
1.1.1 梯度消失的产生原因
以最简单的网络结构为例,假如有三个隐藏层,每层的神经元个数都是1,且对应的非线性函数为 y i = σ ( z i ) = σ ( w i x i + b i ) y_i=\sigma (z_i) = \sigma(w_ix_i+b_i) yi=σ(zi)=σ(wixi+bi), 如下图:

引起梯度消失的“罪魁祸首”其实就是激活函数sigmoid:
σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1
这是因为当我们对Sigmoid函数求导时,得到 σ ′ ( x ) = σ ( x ) ( 1 − σ ( x ) ) \sigma'(x)=\sigma(x)(1-\sigma(x)) σ′(x)=σ(x)(1−σ(x)), 范围在0~0.25.
对于上面的图,
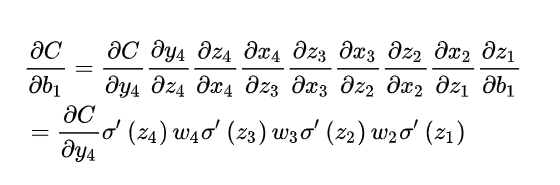
而我们初始化的网络权值通常都小于1,因此,当层数增多时,小于0的值不断相乘,最后就导致梯度消失的情况出现。同理,当权值过大时,导致,最后大于1的值不断相乘,就会产生梯度爆炸。
1.1.2 梯度消失的后果
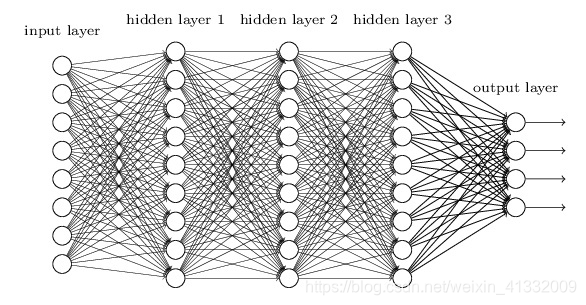
越靠近输入层时,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习。
1.1.3 梯度消失的解决方法
- 用下文提到的LSTM/GRU
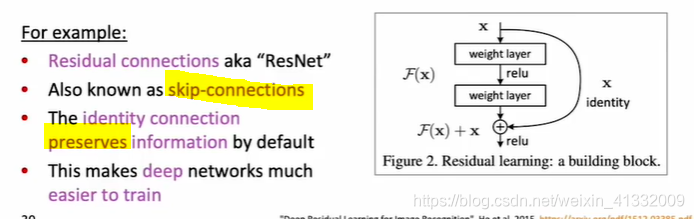
- 加上一些skip-connection, 让梯度直接流过而不经过bottleneck。例如resnet:
- 用Relu、Leaky relu等激活函数
ReLu: 让激活函数的导数为1
LeakyReLu: 包含了ReLu的几乎所有优点,同时解决了ReLu中0区间带来的影响
1.1.4 RNN梯度消失举例

这里应该填"ticket",但是如果梯度非常的小,RNN模型就不能够学习再很久之前出现的词语和现在要预测的词语的关联。也就是说,RNN模型也不能把握长期的信息。
另一个例子:
 syntactic recency 和 sequential recency:
syntactic recency 和 sequential recency:

RNN主要是把握住sequential recency,所以会产生很多问题。
1.2 梯度爆炸
回忆梯度更新的公式:
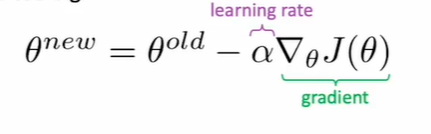
如果梯度太大了,那么步子迈的太大就会导致训练非常不稳定(训飞了),甚至最后loss变成 Inf
1.2.1 梯度爆炸的解决办法
- gradient clipping:

如果梯度大于某个阈值了,就对其进行裁剪,让它不要高于那个阈值。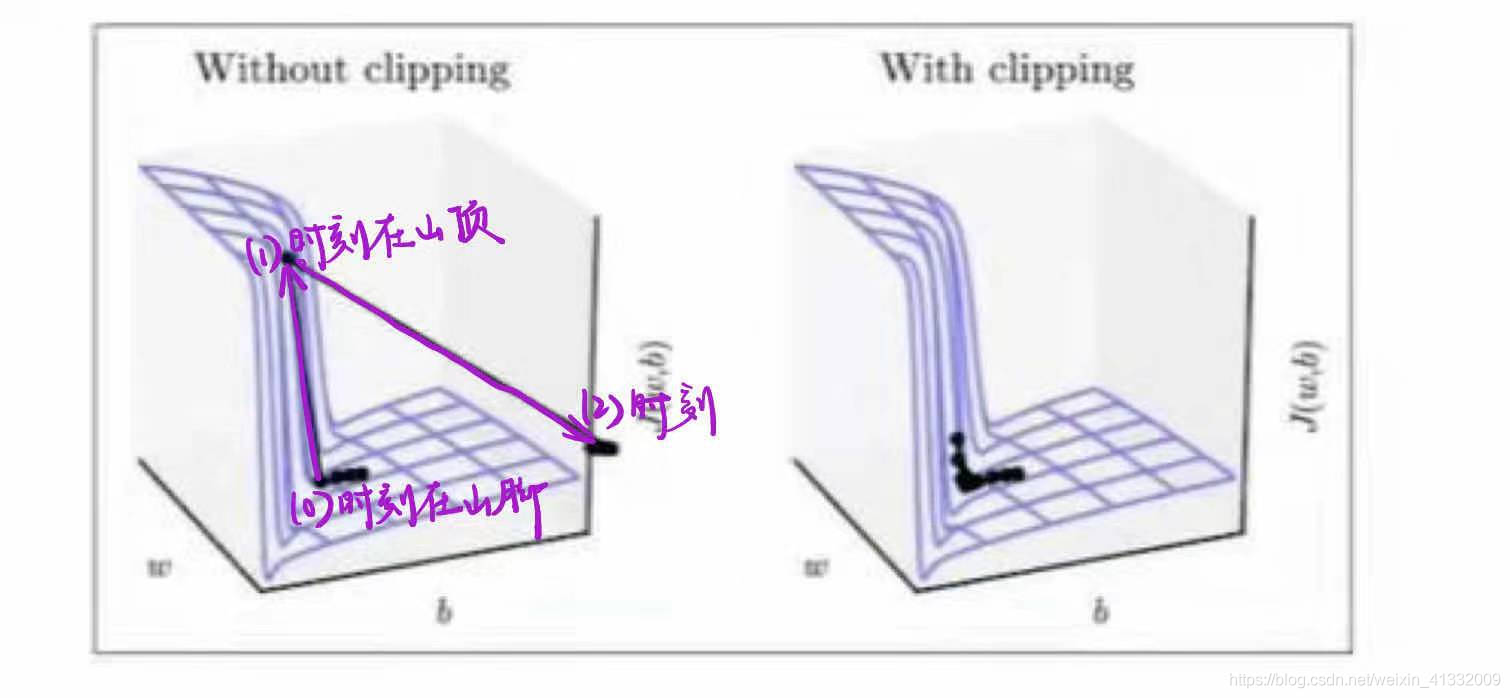

- 权重正则化。如果发生梯度爆炸,那么权值的范数就会变的非常大。通过限制正则化项的大小,也可以在一定程度上限制梯度爆炸的发生。
2. LSTM
2.1 vanilla RNN的缺点:
- 最致命的问题就是,传统RNN不能够保留很久之前的信息(由于梯度消失)
- 传统RNN的隐藏状态在不停的被重写:
h ( t ) = σ ( W h h ( t − 1 ) + W e e ( t ) + b ) h^{(t)} = \sigma(W_h h^{(t-1)}+W_e e^{(t)}+b) h(t)=σ(Whh(t−1)+Wee(t)+b)
所以,可不可以有一种RNN,能够有独立的记忆(separated memory)呢?
2.2 LSTM 基本思想
对于任一时间 t,都有三个概念:
- hidden state: n维向量
- cell state: n维向量,存储长期记忆。cell就像一个小小的计算机系统,可以读、写、擦除。
- gates: n维向量,每个元素的大小都是0~1之间(之后做element-wise product)。决定哪些信息可以穿过,哪些需要被挡住
2.3 LSTM 数学表示
gate设置:
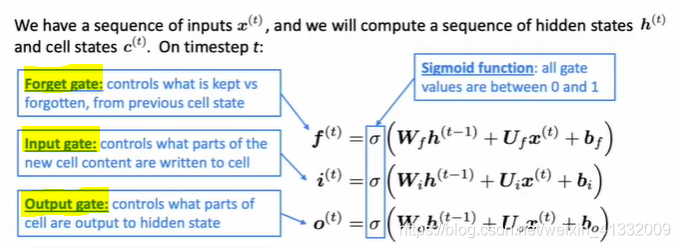
首先,计算三个gate的值。三个gate的值都是根据当前的input x ( t ) x^{(t)} x(t)和上一个hidden state的输出 h ( t − 1 ) h^{(t-1)} h(t−1)决定的。
cell 和 hidden state 的更新:
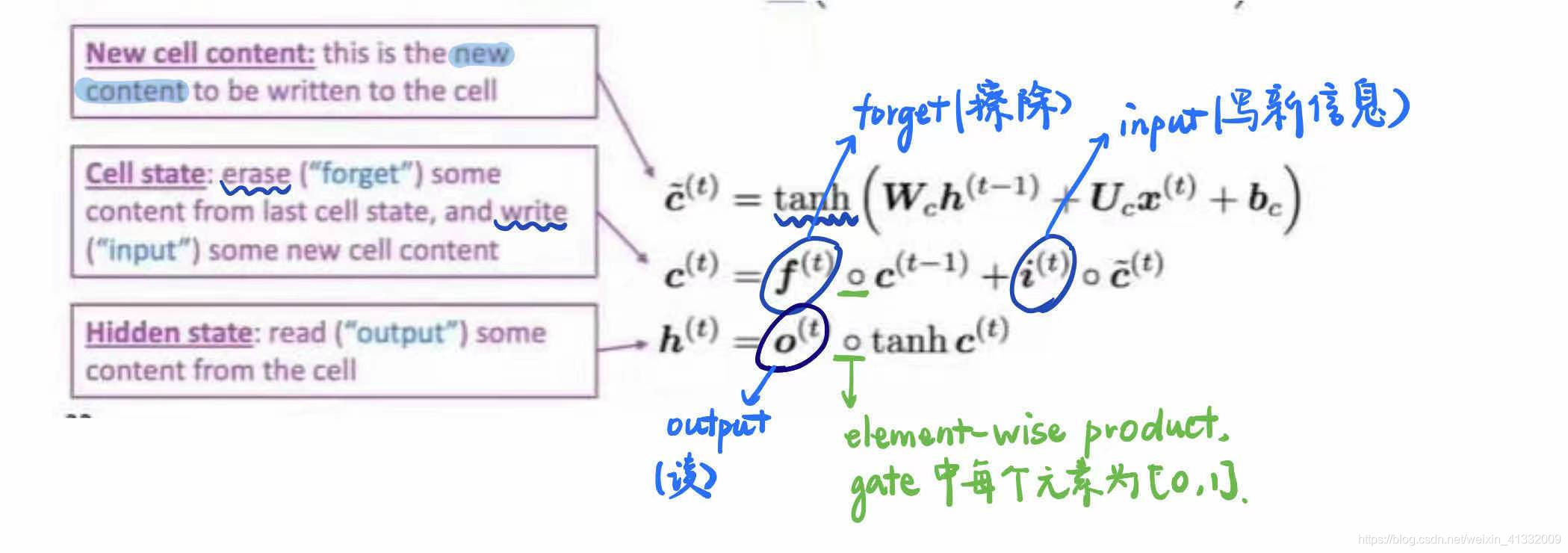
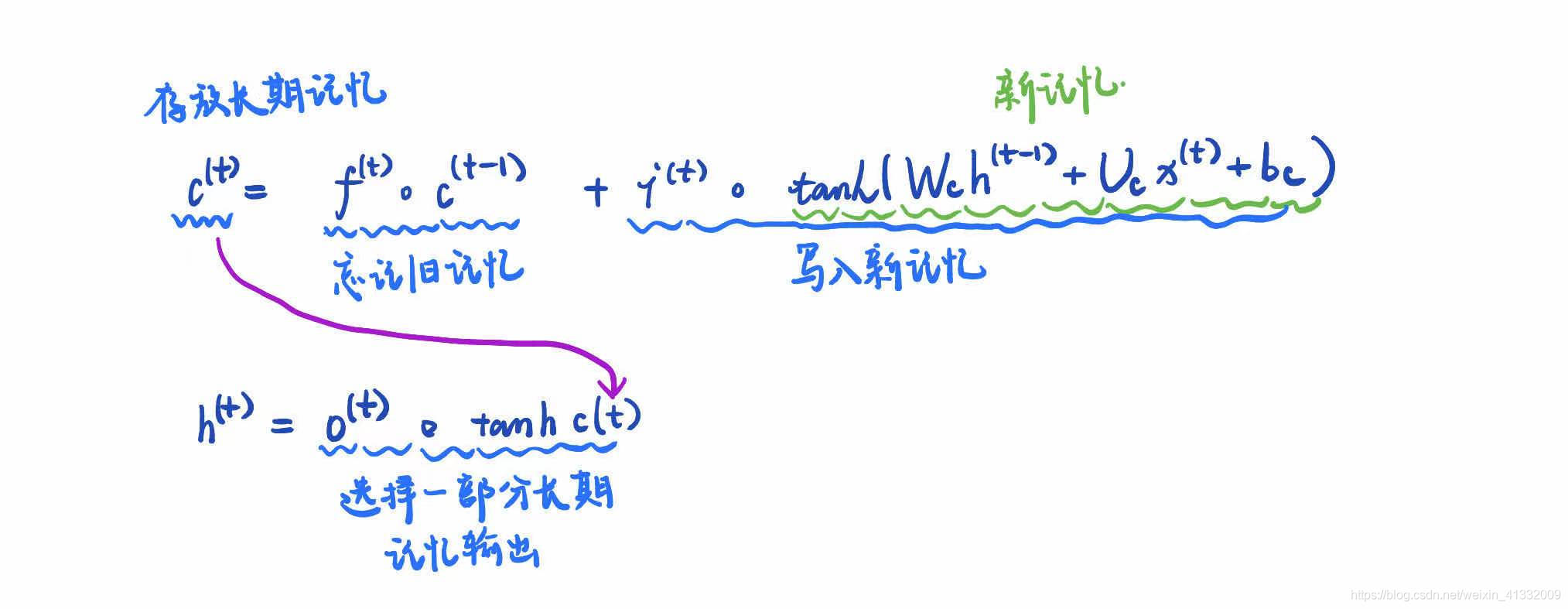
将这个式子重新写一下,可以更直观的看出cell是如何存放记忆的:
2.4 LSTM直观图示
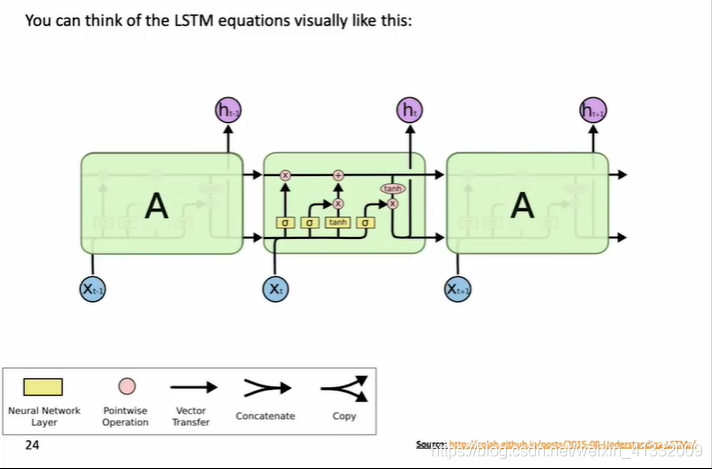
每一个绿色方块是一个timestep。和普通的RNN一样,LSTM也是每一步有输入的 x ( t ) x^{(t)} x(t),有隐藏状态 h ( t ) h^{(t)} h(t)作为输出。
2.5 为什么LSTM能够解决梯度消失
- LSTM能够让RNN一直保留原来的信息(preserve information over many timesteps)。
- 如果LSTM的遗忘门被设置成1,那么LSTM会一直记住原来每一步的旧信息。
- 相比之下,RNN很难能够学习到一个参数矩阵 W h W_h Wh能够保留hidden state的全部信息。
所以,可以说LSTM解决梯度消失的主要原因是因为它有skip-connection的结构,能够让信息直接流过。而vanilla RNN每一步backprop都要经过 W h W_h Wh这个bottleneck,导致梯度消失。
3. GRU(gated recurrent unit)
3.1 GRU结构
跟LSTM不同的是,GRU没有cell state,只有hidden state和两个gate。
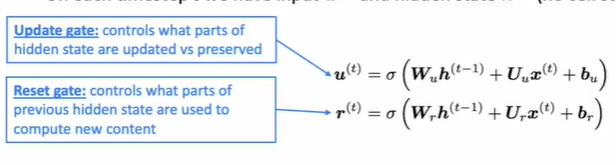
两个gate:
-
update gate: 相当于LSTM中的forget gate(擦除旧信息)和input gate(写入新信息)
-
reset gate: 判断哪一部分的hidden state是有用的,哪些是无用的。
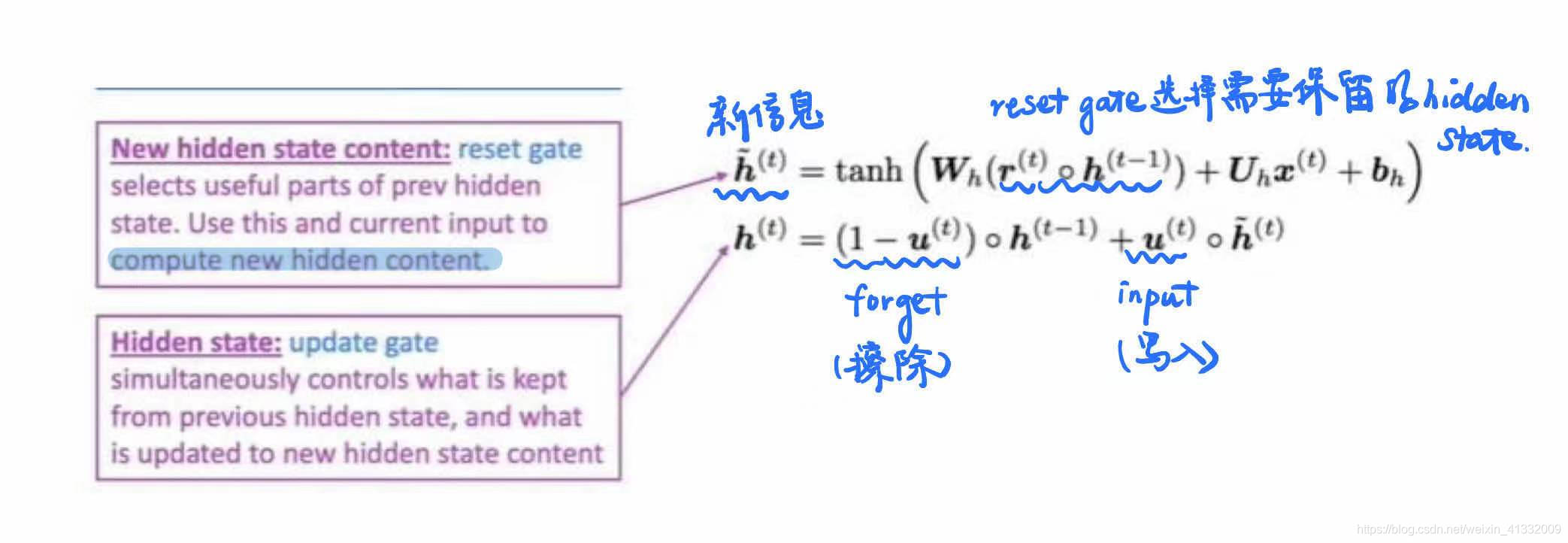
3.2 为什么GRU能解决梯度消失?
就像LSTM一样,GRU也能够保持长期记忆(想象一下把update gate设置成0,则以前的信息全部被保留了)
3.3 LSTM vs GRU
- LSTM和GRU并没有明显的准确率上的区别
- GRU比起LSTM来,参数更少,运算更快,仅此而已。
- 所以,在实际应用中,我们用LSTM做default方法,如果追求更高的性能,就换成GRU
4. Bidirectional RNN
4.1 单向RNN的局限性
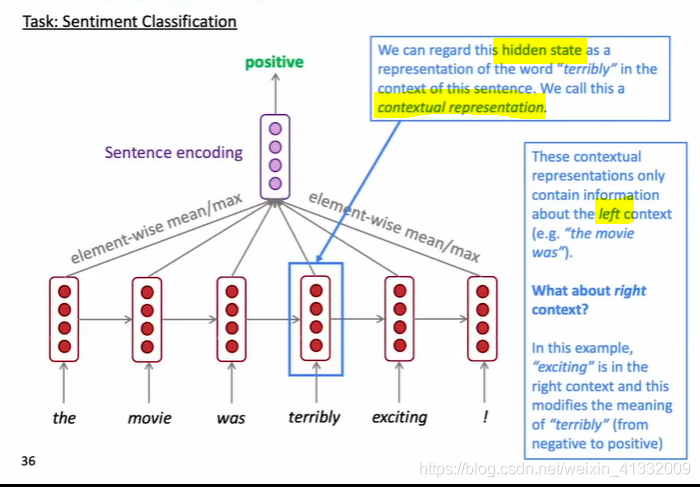
4.2 双向RNN
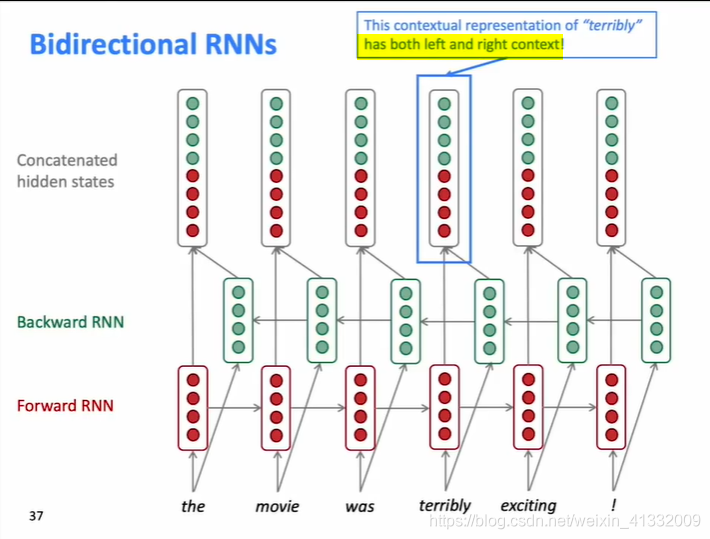
把forward RNN和backward RNN的hidden state都拼接在一起,就可以得到包含双向信息的hidden state。

4.3 双向RNN记号

【注意】
只有当我们有整句话的时候才能用双向RNN。对于language model问题,就不能用双向RNN,因为只有左边的信息。
5. Multi-layer RNNs
多层RNN也叫 stacked RNNs .
5.1 多层RNN结构
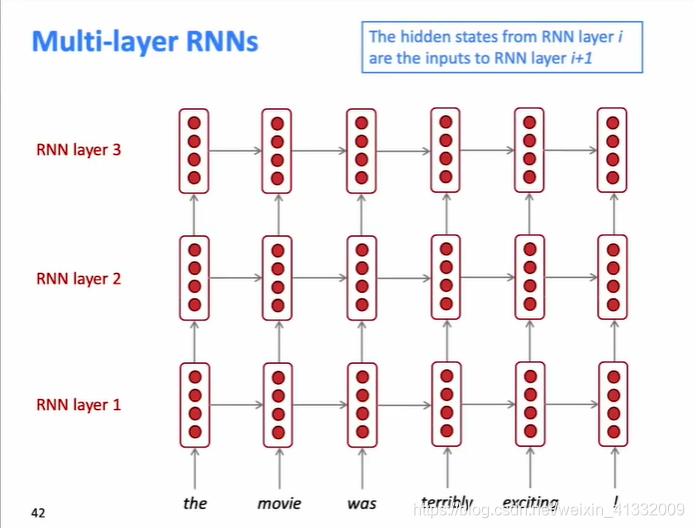
下一层的hidden state作为上一层的输入。
5.2 多层RNN的好处
- 多层RNN可以让RNN网络得到词语序列更加复杂的表示(more complex representations)
- 下面的RNN层可以得到低阶特征(lower-level features)
- 上面的RNN层可以得到高阶特征(higher-level features)
5.3 多层RNN的应用

【注意】
如果multi-layer RNN深度很大,最好用一些skip connection