0. 前言
- 相关资料:
- 论文基本信息
- 领域:行为识别
- 作者单位:南京大学
- 发表时间:2020.12
- 一句话总结:使用RGB difference设计了新的特征提取结构。
1. 要解决什么问题
- 探索高效的temporal modeling方式。
- 常见的 temporal modeling 方式有两种
- 使用双流法,RGB用来提取appearance information,optical flow用来提取movement information。
- 这种方法能够很有效地提高识别精度,但需要的大量算力来计算光流。
- 3D模型,或 temporal convolutions,隐性地学习motion fetures。
- 没有单独考虑temporal dimension相关内容,也需要非常多算力。
- 使用双流法,RGB用来提取appearance information,optical flow用来提取movement information。
- 之前,也有方法使用RGB difference作为输入,作为光流的替代品。
- 但之前的方法都是简单的把RGB作为另一个输入,最终在结果端进行融合。
2. 用了什么方法
-
提出了Temporal Difference Network(TDN),来提取多尺寸的时间信息(multi-scale temporal information)。
- 使用了TSN的结构,sparse and holistic sampling strategy,即1x1x8这种形式
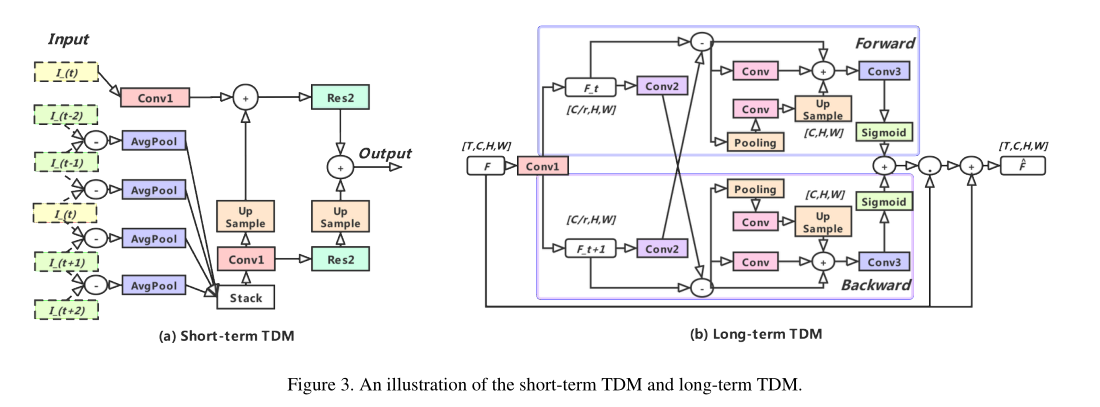
- 主要就是引入了TDM结构,包括short-term和long-term两种。
- short-term TDM的作用是提供更多frame-wise representation
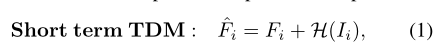
- 第一个参数是最终结果,第二个参数是普通2D CNN结果特征图,第三个参数中函数是S-TDM的结构,输入为图片
- long-term TDM的作用平衡segments之间的结构,从而提升每一帧的表达能力
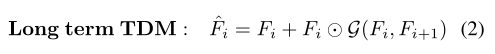
- 最后一个函数是L-TDM结构,这里的F应该是上面S-TDM的结果。
- 当前模型只考虑相邻两帧之间的关系,即L-TDM只是存在于相邻两帧之间。

-
TDN的关键在于引入了 temporal difference based module(TDM)
-
S-TDM
- 作者认为:
- 在一个很小的local temporal window中相邻的帧都非常类似,直接叠加这些信息并提取特征是不明智的。
- 另一方面,从segment中提取信息虽然能够有效提取appearance信息,但不能提取local motion信息。
- 所以,需要使用S-TDM以及相邻帧temporal difference来增强信息。
- 整体结构如上图,感觉使用了选中图片以及选中图片周边一共5帧,来提取diff信息并叠加。
- 总而言之,是提取一个segment内的local motion以及appearance信息。
- 作者认为:
-
L-TDM
- 总而言之,是提取segment之间的信息。
3. 效果如何
-
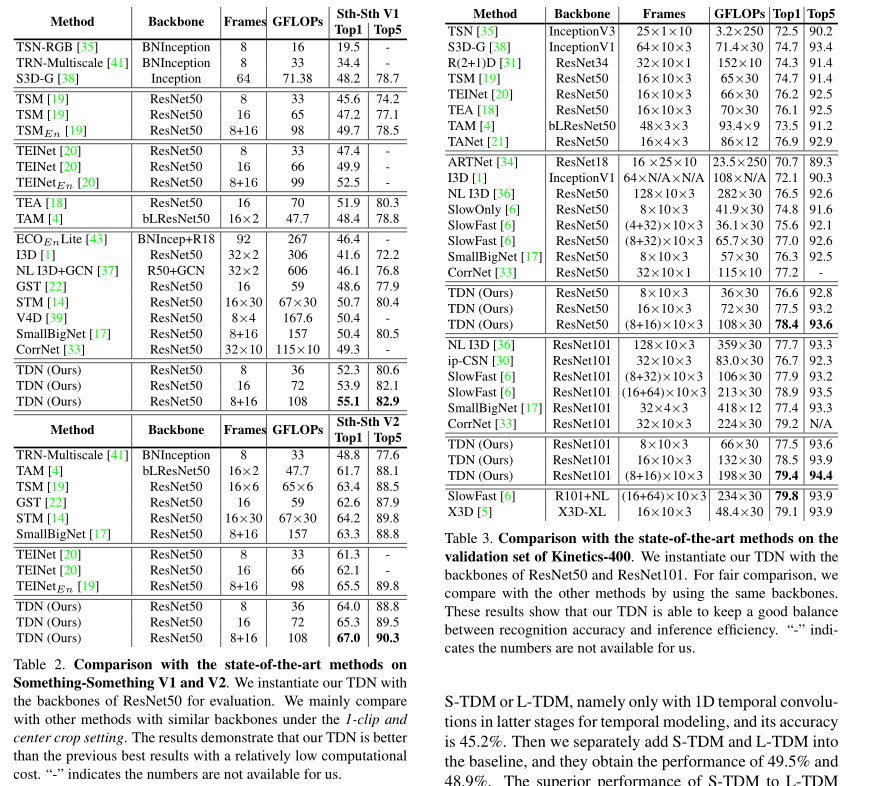
做了详细的消融实验,证明提出结构的有效。
- 说白了,就是尝试了很多种S-TDM和L-TDM的实现方法,选择了最好的发表。
-
在SomethingSomething上达到SOTA。在Kinetcis-400上达到差不多SOTA的效果。
4. 还存在什么问题&可借鉴之处
- 等待开源,不知道真实跑起来效率如何。
- 比如,x3d,看起来厉害,但不知道部署起来效果如何。
- 看起来是很诱人了。
- 但从原理上看起来,在online任务中作用可能不会太大……
- 至少,对我的跌倒检测,S-TDM并没有太好的结果。