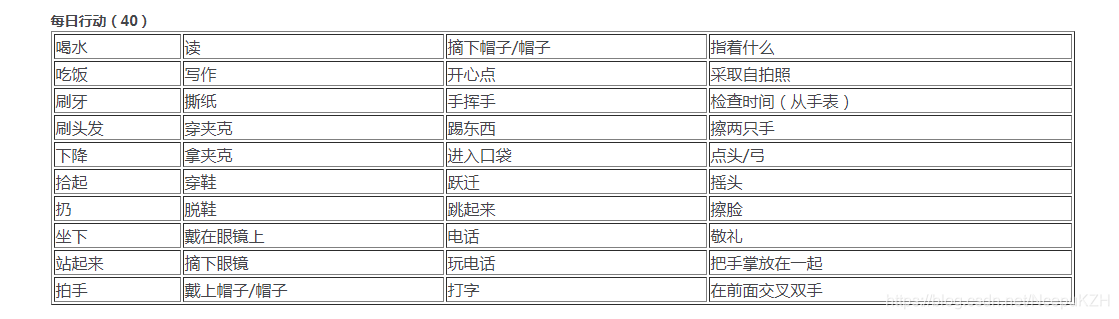
首先感谢 https://blog.csdn.net/dake1994/article/details/82591852 对其博客进行的转载。
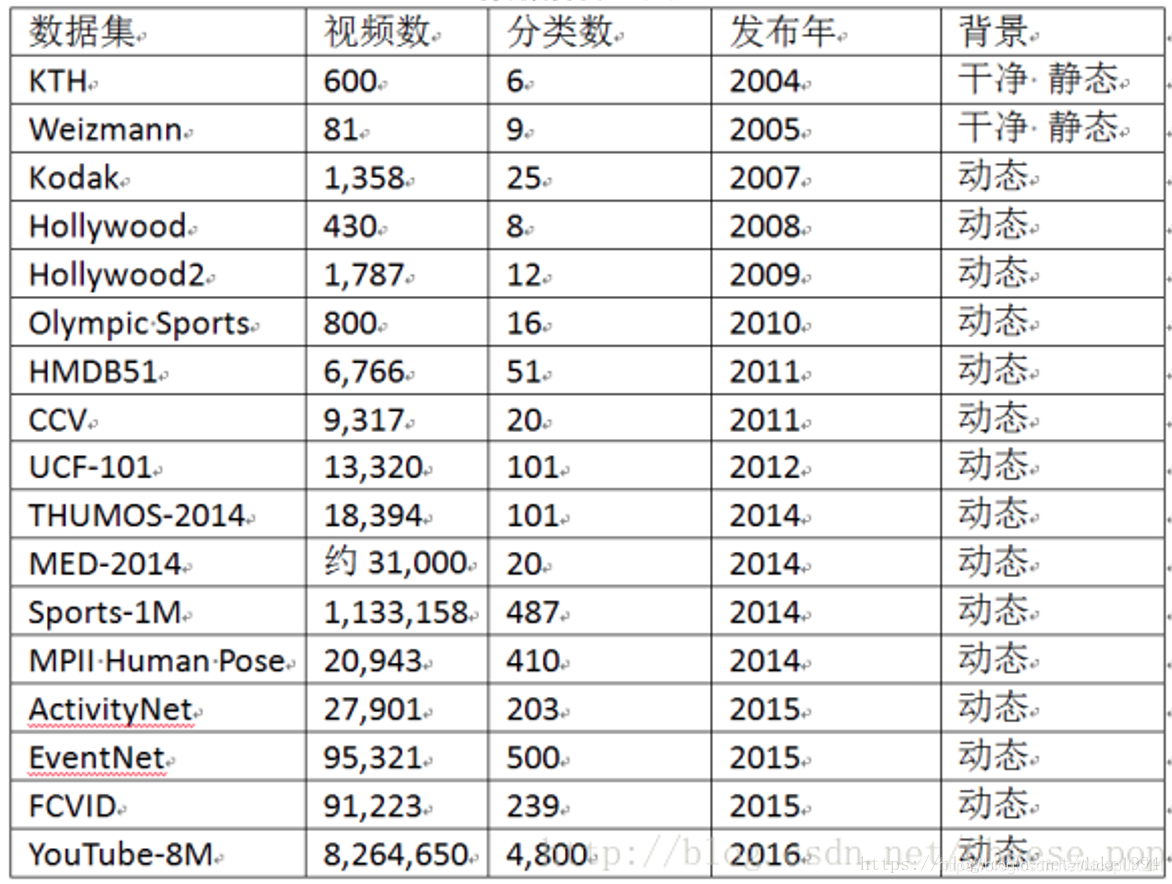
对其中的部分数据集进行介绍:
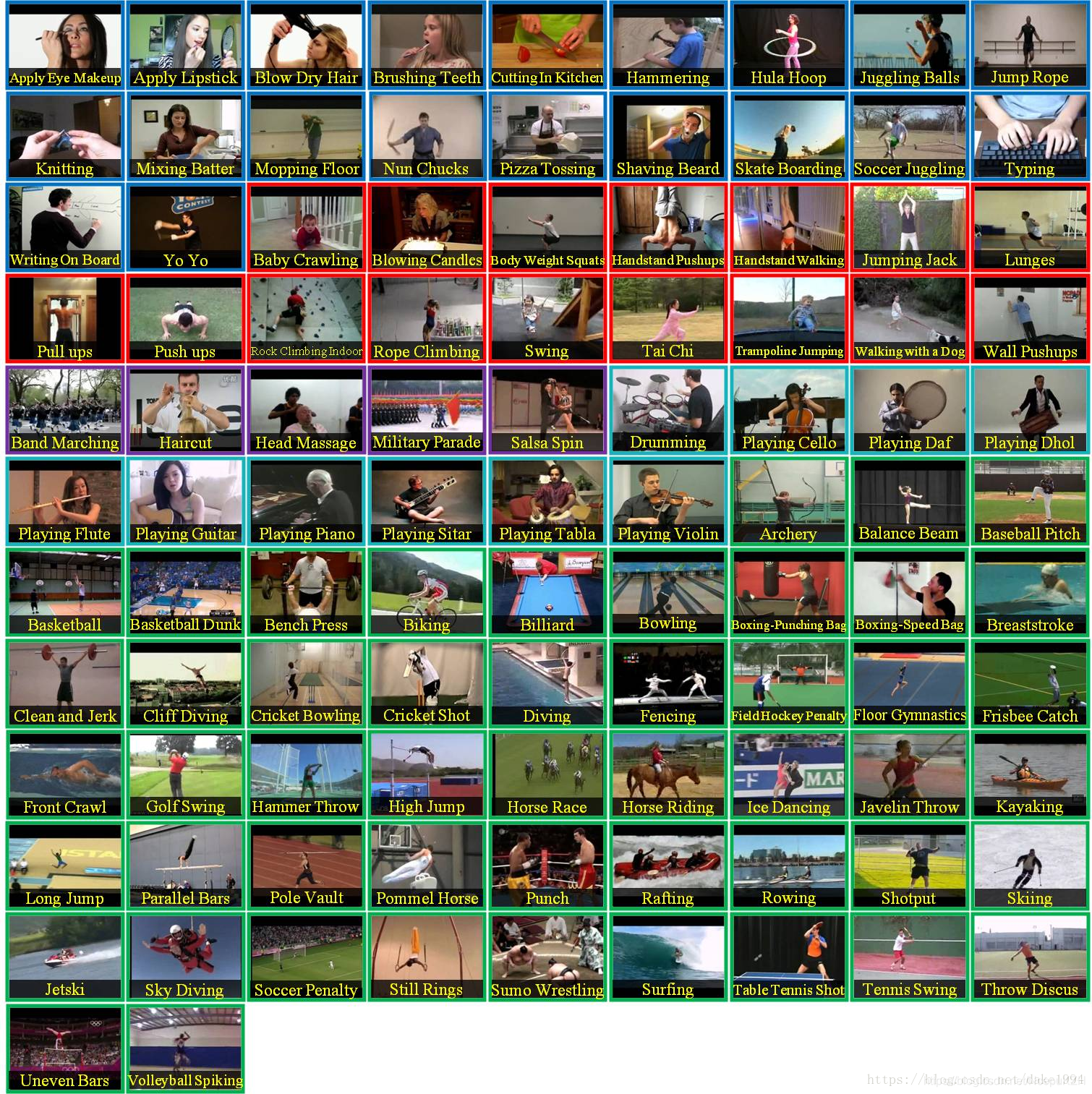
- UCF101
动作识别数据集,从youtube收集而得,共包含101类动作。其中每类动作由25个人做动作,每人做4-7组,共13320个视频,分辨率为320*240,共6.5G。
UCF101在动作的采集上具有非常大的多样性,包括相机运行、外观变化、姿态变化、物体比例变化、背景变化、光纤变化等。
101类动作可以分为5类:人与物体互动、人体动作、人与人互动、乐器演奏、体育运动。
参考文档:http://crcv.ucf.edu/papers/UCF101_CRCV-TR-12-01.pdf
下载网址:http://crcv.ucf.edu/data/UCF101/UCF101.rar

2. HMDB
HMDB51包含51类动作,共有6849个视频,每个动作至少包含51个视频,分辨率320*240,。来自于YouTube,google视频等,共2G.
动作主要包括:
-
一般面部动作微笑,大笑,咀嚼,交谈。
-
面部操作与对象操作:吸烟,吃,喝。
-
一般的身体动作:侧手翻,拍手,爬,爬楼梯,跳,落在地板上,反手翻转、倒立、跳、拉、推、跑,坐下来,坐起来,翻跟头,站起来,转身,走,波。
-
与对象交互动作:梳头,抓,抽出宝剑,运球、高尔夫、打东西,球、挑、倒、推东西,骑自行车,骑马,射球,射弓、枪、摆棒球棍、剑锻炼,扔。
-
人体动作:击剑,拥抱,踢某人,亲吻,拳打,握手,剑战。


下载:http://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/#Downloads
3.Kinetics
Kinetics-600是一个大规模,高质量的YouTube视频网址数据集,其中包含各种人的动作。 还有一个2017年发布的初始数据集,现在称为Kinetics-400。
该数据集由大约500,000个视频组成,涵盖600个人类动作,每个动作至少有600个视频。 每个视频持续大约10秒钟,并标有一个类。 这些动作涵盖了广泛的范围,包括人 - 物体交互,如演奏乐器,以及人与人之间的互动,如握手和拥抱。
下载:https://deepmind.com/research/open-source/open-source-datasets/kinetics/
或者https://github.com/activitynet/ActivityNet/blob/master/Crawler/Kinetics/README.md
4.Google的AVA数据集
Google发布AVA:一个用于理解人类动作的精细标记视频数据集

教机器理解视频中的人类动作是计算机视觉的一个基本研究课题,对于个人视频搜索和发现、运动分析和手势接口等应用必不可少。过去几年来,在图像中分类和查找对象取得了令人兴奋的突破,但识别人类动作仍然是一个巨大的挑战。原因在于,就其本性而言,人类动作的定义不如视频对象完善,因此,很难构建精细标记的动作视频数据集。尽管有许多基准数据集(如 UCF101、ActivityNet 和 DeepMind 的 Kinetics)采用图像分类标记模式,并为数据集中的每个视频或视频剪辑分配一个标签,但对于有多人执行不同动作的复杂场景,还没有相应的数据集。
为促进对人类动作识别的进一步研究,我们发布了 AVA,它诞生于“原子视觉动作”,是一个全新的数据集,为扩展视频序列中的每个人提供多个动作标签。AVA 由 YouTube 中公开视频的网址组成,注解了一组 80 种时空局部化的原子动作(如“走”、“踢(物体)”、“握手”等),产生了 5.76 万个视频片段、9.6 万个标记动作执行人以及总共 21 万个动作标签。
了解数据集和下载注解: https://research.google.com/ava
arXiv 论文:https://arxiv.org/abs/1705.08421
3 秒视频片段(来自视频来源)示例,其边界框注解在每个片段的中间帧中。(为清楚起见,每个示例只显示一个边界框)
与其他动作数据集相比,AVA 具有以下重要特征:
(1)以人为中心的注解。每个动作标签与人相关,而不是与视频或剪辑相关。因此,我们可以将不同标签分配到同一场景中执行不同动作的多个人(这种情况很常见)。
(2)原子视觉动作。我们将动作标签限于很小的时间尺度(3 秒),在此范围内,动作的性质是身体活动,具有清晰的视觉特征。
(3)现实视频材料。我们使用电影作为 AVA 的来源,从很多不同的流派和原产国取材。因此,数据中包含广泛的人类行为。
为创建 AVA,我们先从 YouTube 收集了一组变化多的长形式内容,集中于“电影”和“电视”类别,有许多不同国籍的专业演员。我们对每个视频分析了 15 分钟的片段,将其统一分隔为 300 个不重叠的 3 秒片段。采样策略将动作序列保持在连贯的时间背景中。
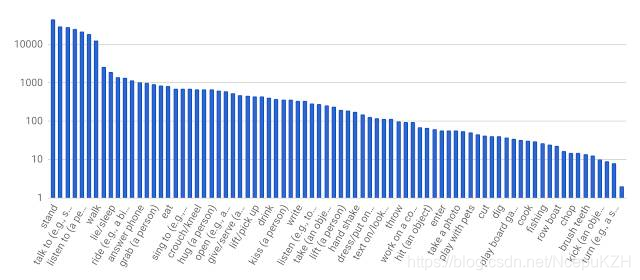
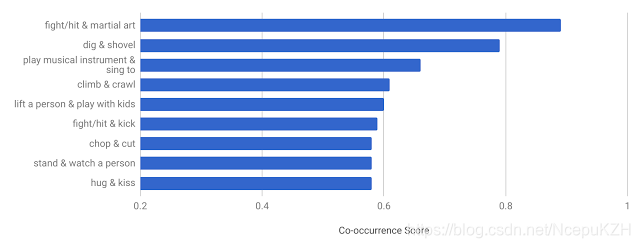
AVA 的核心团队包括 Chunhui Gu、Chen Sun、David Ross、Caroline Pantofaru、Yeqing Li、Sudheendra Vijayanarasimhan、George Toderici、Susanna Ricco、Rahul Sukthankar、Cordelia Schmid 和 Jitendra Malik。感谢许多 Google 同事和注解人员对此项目的全力支持。
5、NTU RGB+D
只需要下载5.8G数据集,需要使用edu邮箱进行注册,申请后邮件会给出专门的下载账号和密码http://rose1.ntu.edu.sg/Datasets/actionRecognition.asp
PDF论文下载:
http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Shahroudy_NTU_RGBD_A_CVPR_2016_paper.pdf
数据集的结构
该数据集由56,880个动作样本组成,每个样本包含4种不同的数据模态:
(1)RGB视频
(2)深度图序列
(3)3D骨架数据
(4)红外视频
Kinect V2的默认30 fps设置来捕获所有模态。
60类动作: