本文主要是记录和简义这个github项目的练习
设备windows10
tensorflow1.10.0
原文github:点这里
偶然发现的和我类似的文章还没看 点这里
首先我们知道,tensorflow官方是有一个物体检测的API接口的。而我们今天要练习的项目就是基于这个API在window10的一个实现。
你不可能是从零开始吧。如果是那你看这个太早了
我们从步骤二开始了。不说怎么来安装tensorflow了
step 2
我们需要clone下来这个项目。


然后需要将python加入系统环境变量。
2.a
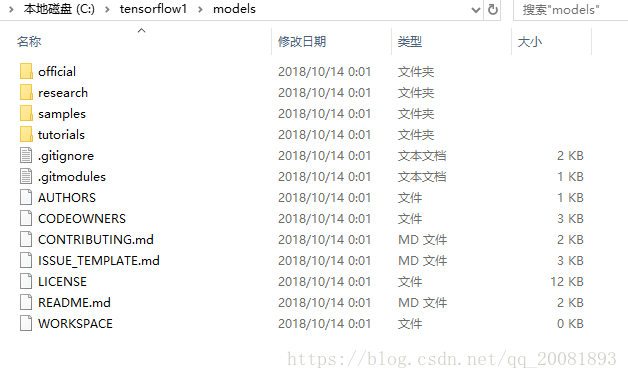
我们要在C盘建一个叫tensorflow1的文件夹
然后吧tensorflow官方的model整个的zip下载下来
在这说一句,这个文件有点大。。。
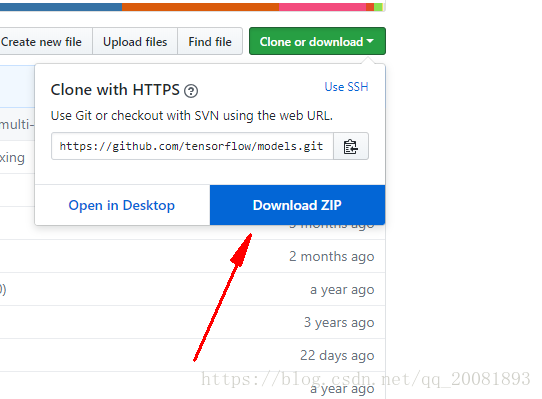
下载完了之后,我们直接解压。然后吧model-master这个解压得到的文件夹放到tensorflow1这个文件夹中
并且改名为model
如下图
这些步骤如果出错可以检查网络等原因。目前基于当前版本
2b
Download the Faster-RCNN-Inception-V2-COCO model from TensorFlow's model zoo
意思是我们需要上tensorflow上下载这个模型。
在这先别着急。作者似乎告诉我们。他一开始使用的是官方的那个模型,然后这个模型是有一个很快的速度。但是对于这个准确率好像不太高尤其是对于它这个卡片识别。所以它又训练了一个速度慢的,但是准确高的这么一个模型。也给了我们下载地址。
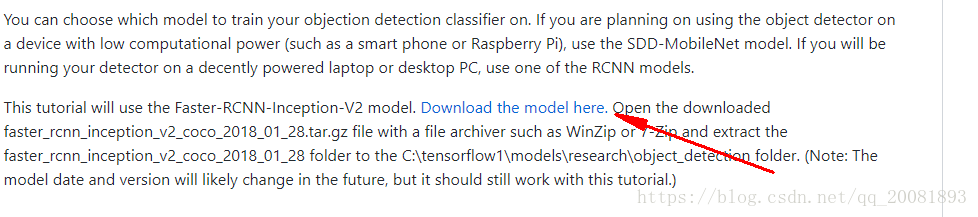
直接点这里就能够下载了。
解压后把这个文件放到C:\tensorflow1\models\research\object_detection
2c
再把我们一开始clone或者下载项目文件也移入到这里面,然后覆盖掉readme.md文件。

这里作者主要就是解析我们可以自己去构建

我们下载下来之后需要把文件放到如下位置
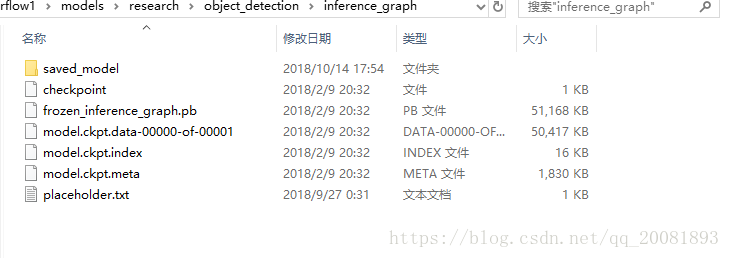
这个是github上告诉我们怎么来在训练自己的检测模型时的文件夹配置。

接下来我没有按照github作者的方式了,原作者使用的是anaconda但是我没有安装哈。所以目前我用pycharm打开,然后如下图中所示。原文中我们继续往后看会发现有需要我们将一些路径加入到path中区,所以我们需要用pycharm中加入为source root中去加入完成之后目录颜色会有所变化。

这个是需要添加的所有文件夹

然后接下来我们这有一个问题,我们原作者说tensorflow提供的这个API不支持windows,所以我们需要手动的去用protoc这个工具去做一件事。我不太秦楚这个工具的效果
但是我们安装anaconda的时候原作者告诉我们怎么安装了。但是那是通过anaconda里。所以我们需要单独安装
https://github.com/protocolbuffers/protobuf/releases
这个是他的文件位置。

我下载之后解压了。
放在了这样一个位置上
然后我将这个加入了系统环境变量中去‘这样,我们就能够在命令行中间去使用。
最后我们复制图片中间的这一串命令。然后在C:\tensorflow1\models\research这个文件下打开命令行执行。

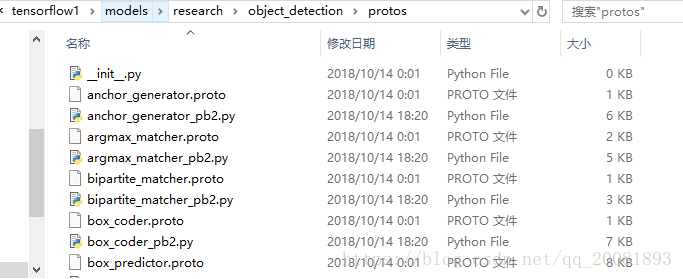
如作者所说,这个目录下生成了对应的pb2.py文件
接下来进入如下位置

运行

第一个执行完
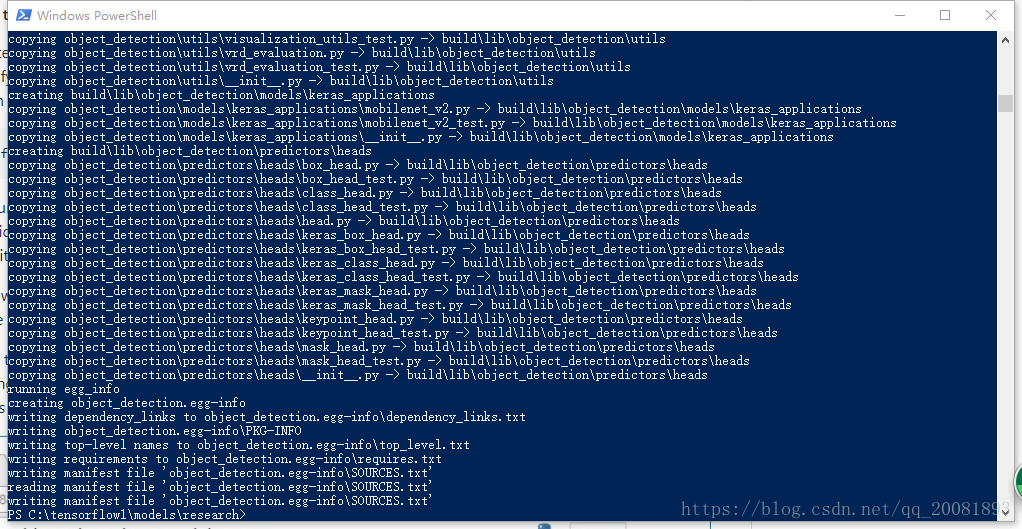
第二个执行完成
这个中间我看到有一些错误,目前不知道能不能成功。
我继续了,他是成功的
,接下来我们需要安装jupyter notebook
我么这里使用pip 安装方式,我们如果不安装的话需要我们手动去改写ipynb文件,提取有用的数据为py文件。
安装完之后我么还需要在pycharm中间把object-detection文件也加入到source root中间,然后我们在
如图中的位置打开jupyter notebook

原作者所说的这个文件。并且从头开始运行。
注意。这里在代码中我们还要下载一些模型,所以请保证网络通畅。
最后全部运行完之后如下图
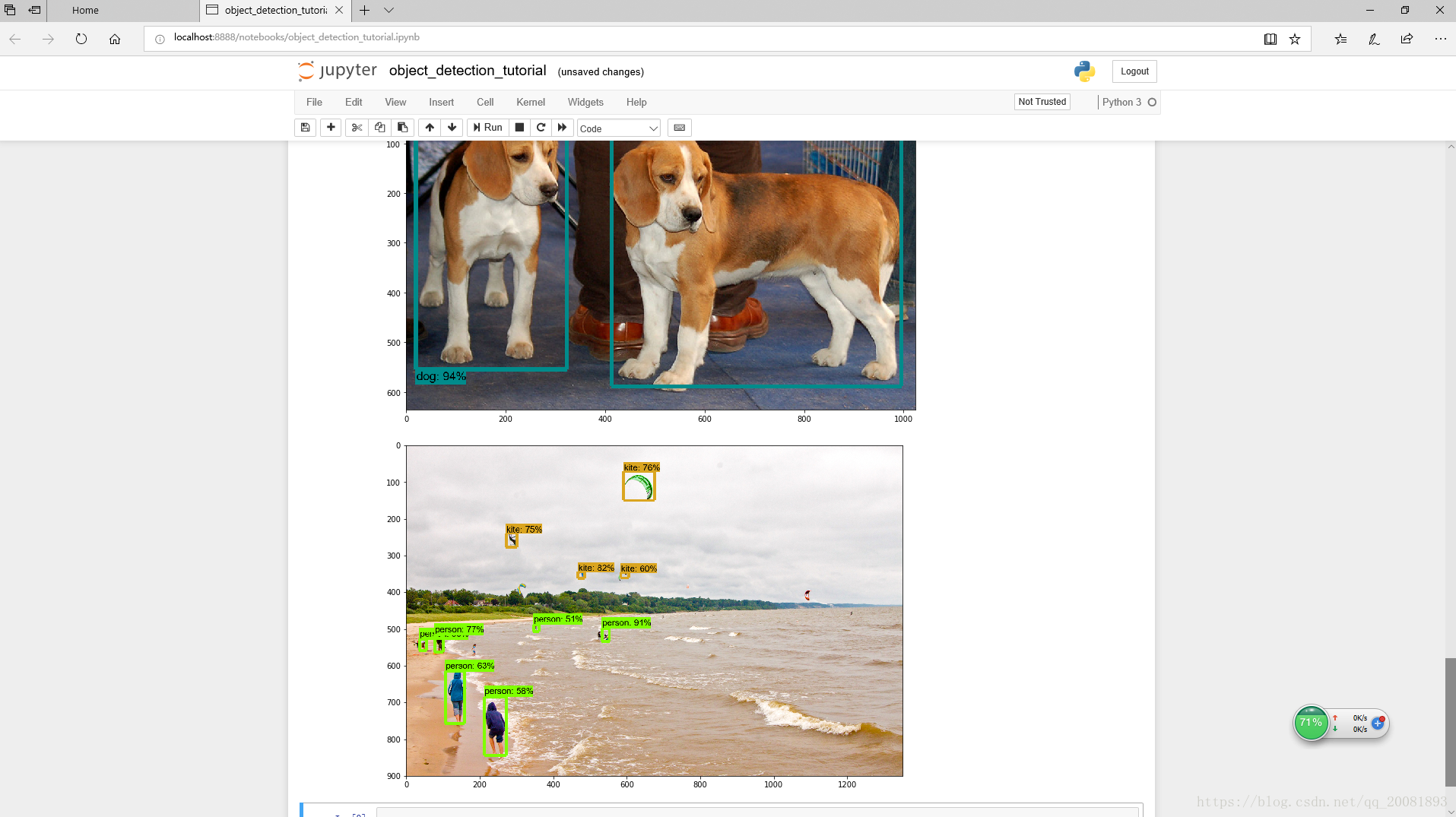
最后提醒一下,其中很多东西下载需要梯子,请自行解决。
这样我们就完成了github中作者的第二部,我们能测试我们的环境了。
step3 收集和标记我们的图片
终于来到第三步了。
这一步主要好像是讲怎么训练。

(请原谅我渣渣的英语)
很尴尬,我刚刚看来一下,发现他没给图片,要我们自己去找,。。。先暂停。。。
2018.10.19/19.31
这一步是收集我们自己的图片了。
源作者说,为了训练一个强健的分类器,这里的这个图片需要有要检测目标和其他目标,有不同的光线和背景
有的目标应该是模糊的,被盖住,重叠存放,或者只有一半。
我们可以使用我们自己的手机拍照,原作者就是自己拍的,也可以上百度图片Google图片搜索。
需要确保有一定量的重叠图片
每张图片文件不要太大,像素也不要太大。