FreeAnchor: Learning to Match Anchors for Visual Object Detection
paper:https://proceedings.neurips.cc/paper/2019/file/43ec517d68b6edd3015b3edc9a11367b-Paper.pdf
code
文章目录
1. Motivation
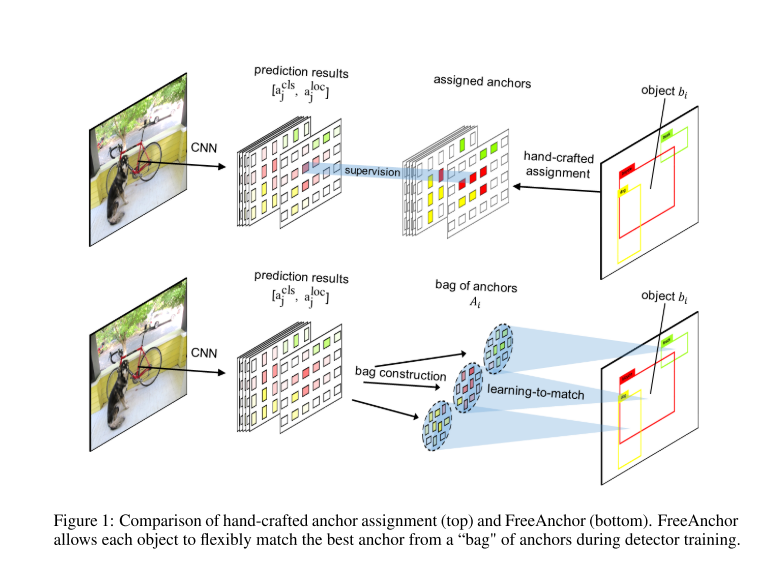
intuition:对齐的物体候选框是对于物体的分类和回归最适合的的。作者认为这种假设并不合理,并且手工制定的IoU criterion并不是最佳的选择。
另一方面,对于多物体重合时,使用IoU来匹配适合的anchors并不可行。并且手工的label assignment在面临acentric,slender和crowded的物体时候回failed。在现有的方法中,检测器训练期间仍然缺乏一种系统的方法来对锚点和对象之间的对应关系进行建模,这阻碍了特征选择和特征学习的优化。因此,作者找到一个自学习的方法,来解决这个手工设计的这个问题。
2. Contribution
- 作者制定目标检测器的训练是一个极大似然估计的方法,并且将手工设计的anchor assignment 变成 free anchor matching。
此方法,打破了IoU的限制,允许物体在MLE的准则下灵活的选择anchors。
- 作者在端到端的结构中联合优化物体的分类和回归。
3. Proposed Approach
3.1 Detector Training as Maxium Likelihood Estimation
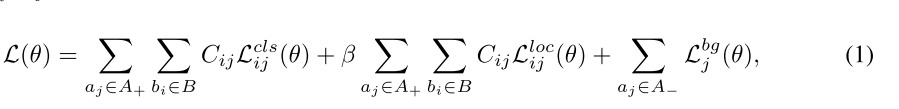
从MLE的思路中,训练损失 L ( θ ) L(\theta) L(θ)可以转换为似然概率,如下公式所示:
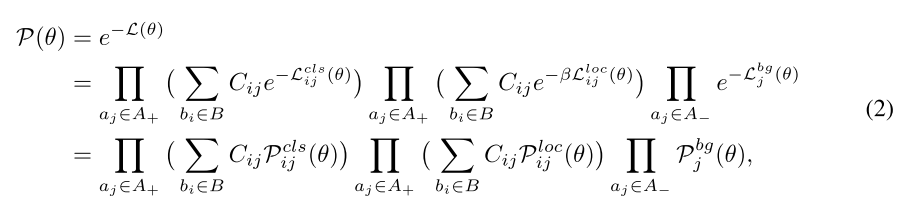 $P_{ij}^{cls}(\theta)$和$P^{bg}_j(\theta)$表示分类的confidence,$P_{ij}^{loc}(\theta)$表示位置的confidence。最小化公式1中的损失函数$L(\theta)$就是最大化公式2中的似然概率$P(\theta)$。
$P_{ij}^{cls}(\theta)$和$P^{bg}_j(\theta)$表示分类的confidence,$P_{ij}^{loc}(\theta)$表示位置的confidence。最小化公式1中的损失函数$L(\theta)$就是最大化公式2中的似然概率$P(\theta)$。
从MLE的理念中,公式2中考虑了分类的优化以及anchor的位置回归,可是它忽略了如何去学习匹配矩阵 C i j C_{ij} Cij。现有的方法通过使用IOU来挑选anchors来解决这个问题,但是忽略了object-anchor matching的优化。
3.2 Detection Customized Likelihood
为了实现关于object-anchor匹配的优化,作者在原有CNN网络框架的基础之上,加入了自制的检测似然。作者介绍一个检测自定义的似然函数,可以包含了recall和precision,同时保证NMS的兼容性。
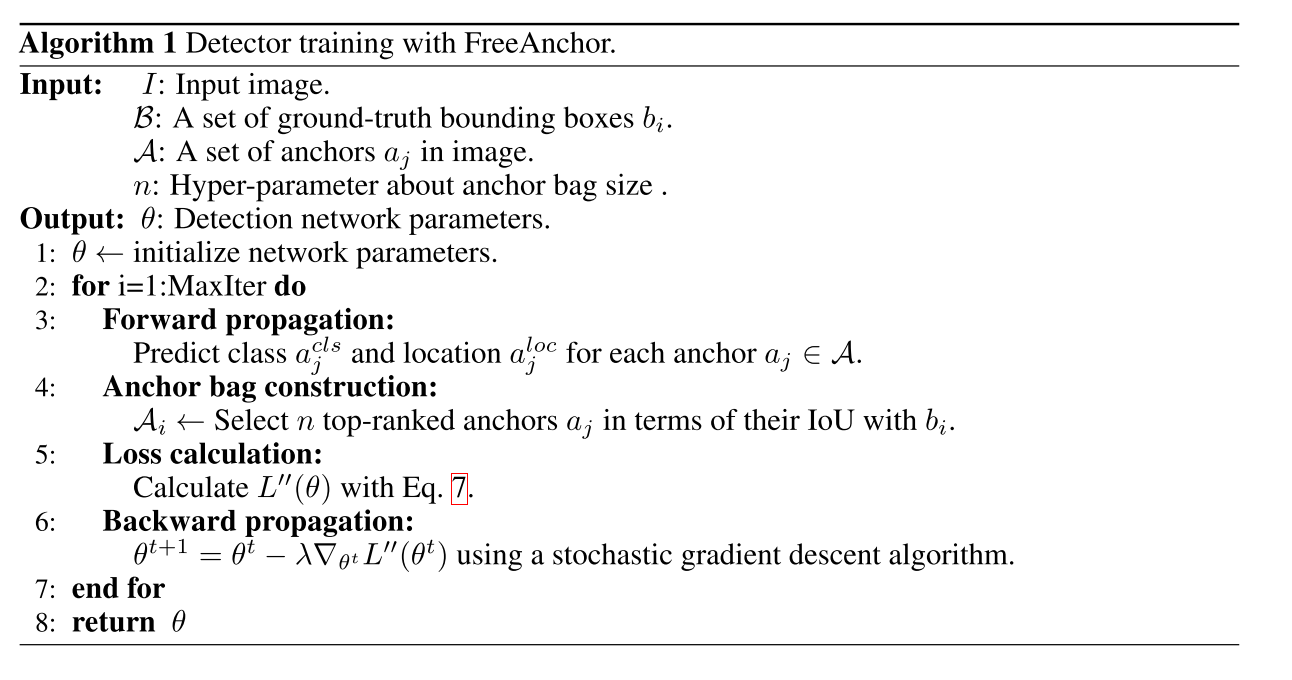
为了实现这种似然,作者构造了了一个对于每一个物体 b i b_i bi的候选anchors的bag,来学习匹配最佳的anchor,同时最大化自定义检测似然。具体做法是先通过anchors与每一个object的IOU,为**每一个目标 b j ∈ B b_j \in B bj∈B**选择top-n的anchors A i ⊂ A A_i \subset A Ai⊂A,
- 为了优化召回率recall,对于每一个目标 b j ∈ B b_j \in B bj∈B,在top-ranked anchors的基础上 A i A_i Ai,我们需要保证至少存在一个anchor, a j ∈ A i a_j \in A_i aj∈Ai与之匹配。召回率的目标函数公式如下所示:
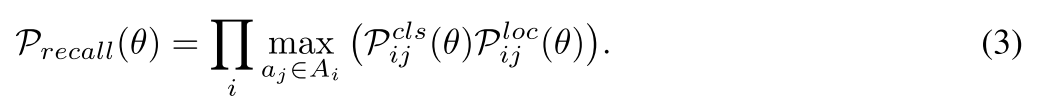
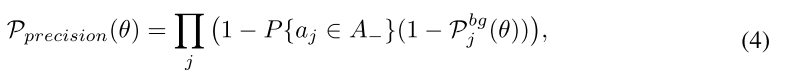
其中 P { a j ∈ A − } = 1 − max i P { a j → b i } P\{a_j ∈ A−\} = 1 − \max_i P\{a_j → b_i\} P{ aj∈A−}=1−maxiP{ aj→bi}表示 a j a_j aj错过了所有的目标的概率, P { a j → b i } P\{a_j → b_i\} P{ aj→bi}表示 a j a_j aj正确预测 b j b_j bj的概率。
-
为了与NMS方法兼容, P { a j → b i } P\{a_j → b_i\} P{ aj→bi}需要设计成分段函数,遵循3个属性。
- P { a j → b i } P\{a_j → b_i\} P{ aj→bi}是一个关于 a j l o c a_j^{loc} ajloc和 b i b_i bi的IOU( I o U i j l o c IoU_{ij}^{loc} IoUijloc)的单调递增函数。
- 当 I o U i j l o c IoU_{ij}^{loc} IoUijloc小于阈值t时, P { a j → b i } P\{a_j → b_i\} P{ aj→bi}接近于0。
- 存在并且仅有一个 a j a_j aj,对于 b j b_j bj满足 P { a j → b i } = 1 P\{a_j → b_i\}=1 P{ aj→bi}=1。
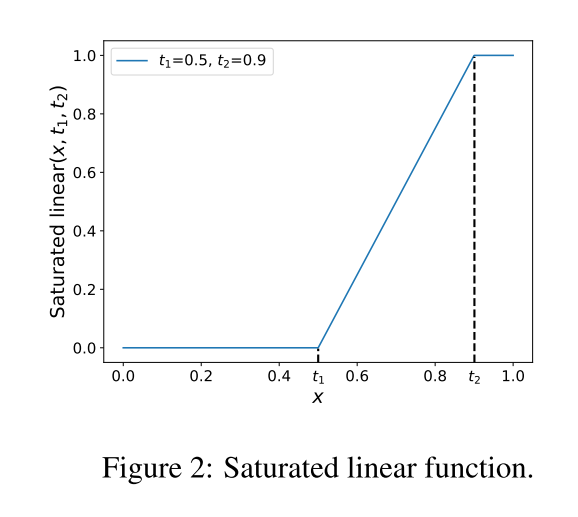
满足这3个属性可以看成是一个saturated linear function。 P { a j → b i } = S a t u r a t e d l i n e a r ( I o U i j l o c , t , m a x j ( I o U i j l o c ) ) P\{a_j \rightarrow b_i\} =Saturated linear(IoU_{ij}^{loc},t,max_j(IoU_{ij}^{loc})) P{ aj→bi}=Saturatedlinear(IoUijloc,t,maxj(IoUijloc))公式如下:
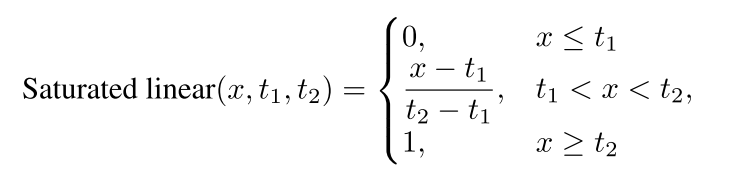
对公式4进行分析,因为我们的目的是要把poor localization分类为background的思想,因此分为以下2种情况思考:
-
当 P j b g ( θ ) P_j^{bg}(\theta) Pjbg(θ)较大时,表示 a j a_j aj为背景类的概率较大,那么 1 − P j b g ( θ ) 1-P_j^{bg}(\theta) 1−Pjbg(θ)接近于0,因此精确度就是1-接近于0的一个数,满足要求。
-
当 P j b g ( θ ) P_j^{bg}(\theta) Pjbg(θ)较小时,表示 a j a_j aj为前景类的概率较大,那么 1 − P j b g ( θ ) 1-P_j^{bg}(\theta) 1−Pjbg(θ)接近于1, 因此就不应该去掉这个前景,因此利用 P { a j ∈ A − } = 1 − max i P { a j → b i } P\{a_j ∈ A−\} = 1 − \max_i P\{a_j → b_i\} P{ aj∈A−}=1−maxiP{ aj→bi}来约束,让 P { a j → b i } = 1 P\{a_j → b_i\}=1 P{ aj→bi}=1接近于1,那么 P { a j ∈ A − } P\{a_j ∈ A−\} P{ aj∈A−}就会接近于0,因此精确度也还是接近于1的。
由以上公式,自制的似然函数可以被定义为公式(5):
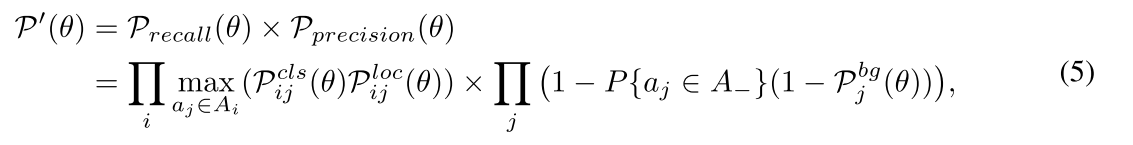
最大化 P r e c a l l ( θ ) P_{recall}(\theta) Precall(θ)和 P p r e c i s i o n P_{precision} Pprecision,从而实现object-anchor的匹配问题。
3.3 Anchor Matching Mechamism
将公式5中的自制似然函数,转化为检测的损失函数,由公式6所示:
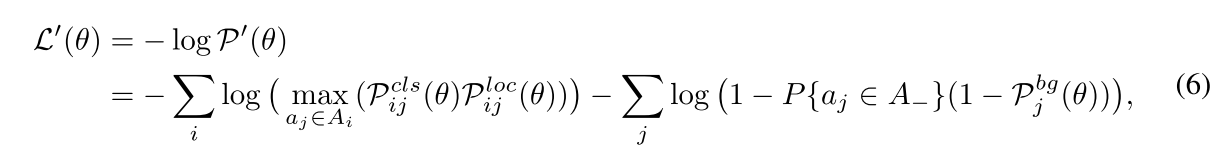
对概率 P ( θ ) P(\theta) P(θ)取负对数,类似于交叉熵的方法,连乘变为连加,概率越高,损失越小。对于每一个object b i b_i bi,都有一个anchor bag A i A_i Ai,在这里面去挑选 a j a_j aj。max函数用于找到对于每一个object最佳的anchor,在训练中每一个anchor都是从anchors的bag中挑选。用于优化模型参数 θ \theta θ。
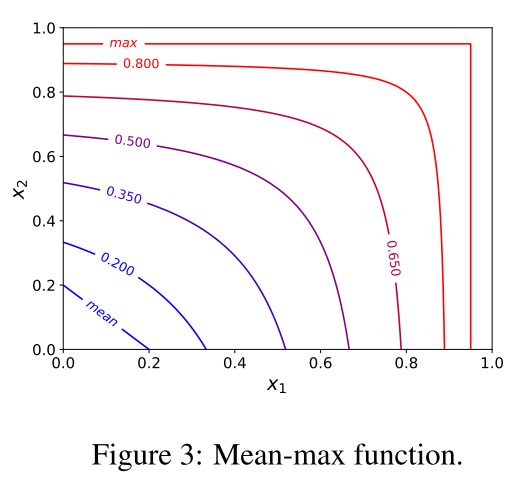
在刚开始训练时,由于初始化网络参数的缘故,所有anchors的置信度会比较小。越高的置信度并不一定适合训练,因此作者提出了Mean-max函数用于选取anchors,定义如下:
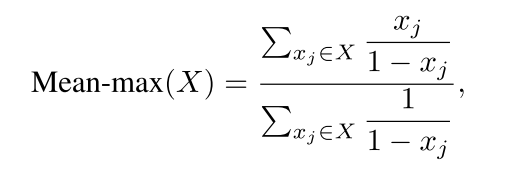
如图3所示,当训练是insufficient时,函数接近于mean函数,这以为着在bag中的大部分的anchors都用于训练了;在训练的过程中,一些anchors的置信度会增大,因此Mean-max函数会越来越接近于max函数;当训练的sufficient发生时,一个最佳的anchor就会被挑选出来去匹配每一个object。
在公式6中,用Mean-max函数取代Max函数,并且添加2个参数 w 1 , w 2 w1,w2 w1,w2,并且对于第二部分采用focal loss。如公式7所示,FreeAnchor的自定义损失函数就表示为公式7:
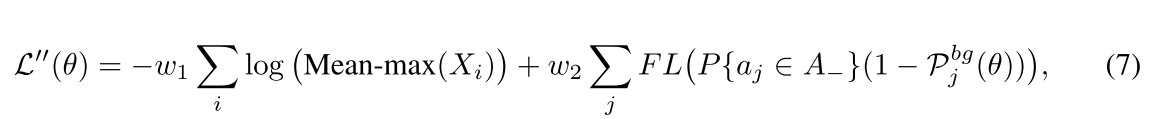
其中, X i = P i j c l s ( θ ) P i j l o c ( θ ) ∣ a j ∈ A i X_i={P_{ij}^{cls}(\theta)P_{ij}^{loc}(\theta)|a_j \in A_i} Xi=Pijcls(θ)Pijloc(θ)∣aj∈Ai表示似然的集合,相对于anchor bag A i A_i Ai。使用focal loss中的 α 和 γ \alpha和\gamma α和γ,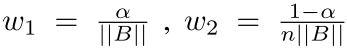 ,并且 F L ( x ) = − x γ l o g ( 1 − x ) FL(x)=-x^{\gamma}log(1-x) FL(x)=−xγlog(1−x)。算法1,表示了训练的实现步骤。
,并且 F L ( x ) = − x γ l o g ( 1 − x ) FL(x)=-x^{\gamma}log(1-x) FL(x)=−xγlog(1−x)。算法1,表示了训练的实现步骤。
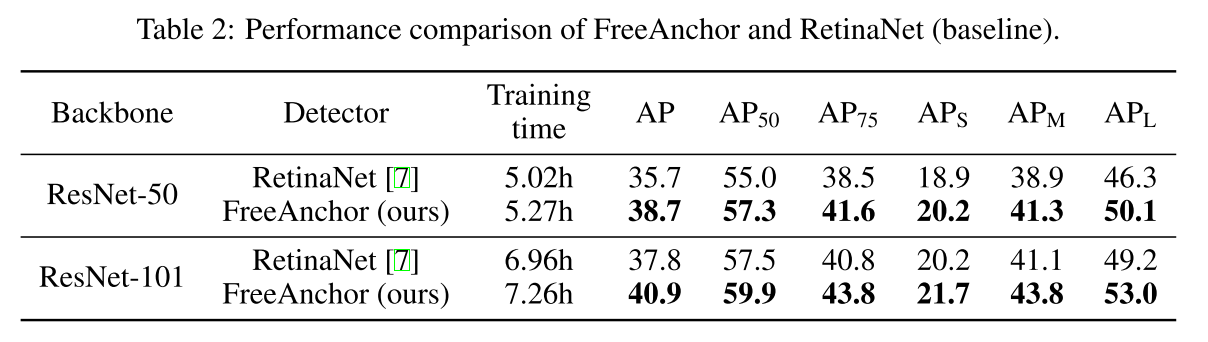
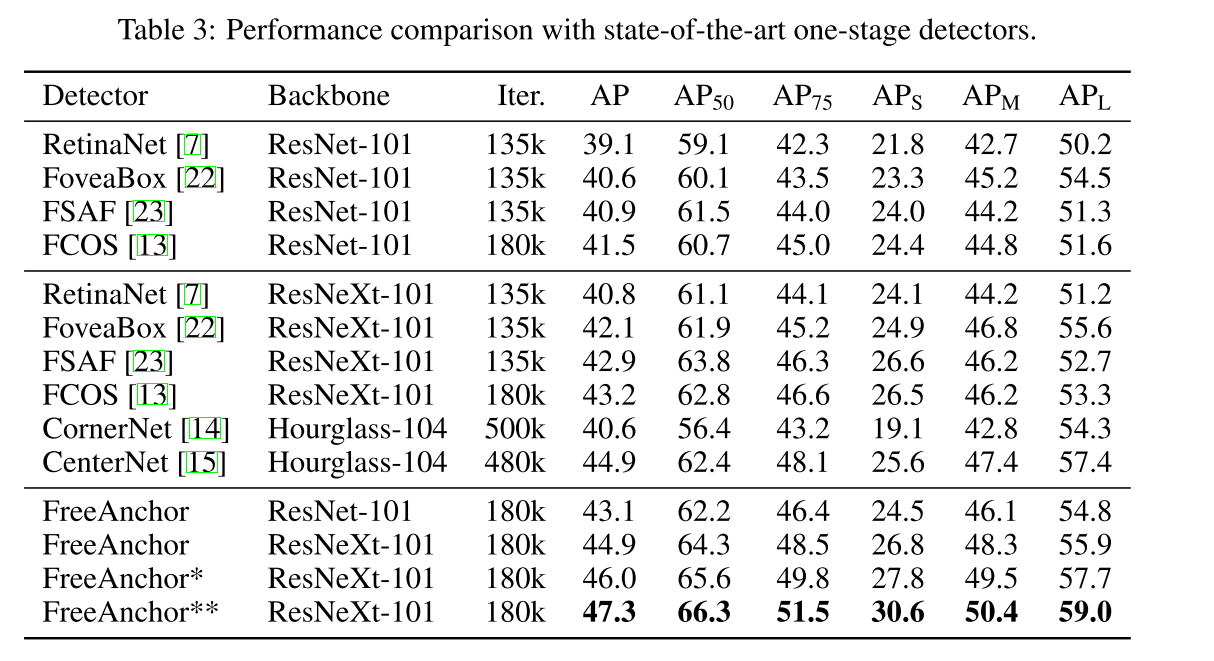
4. Experiments
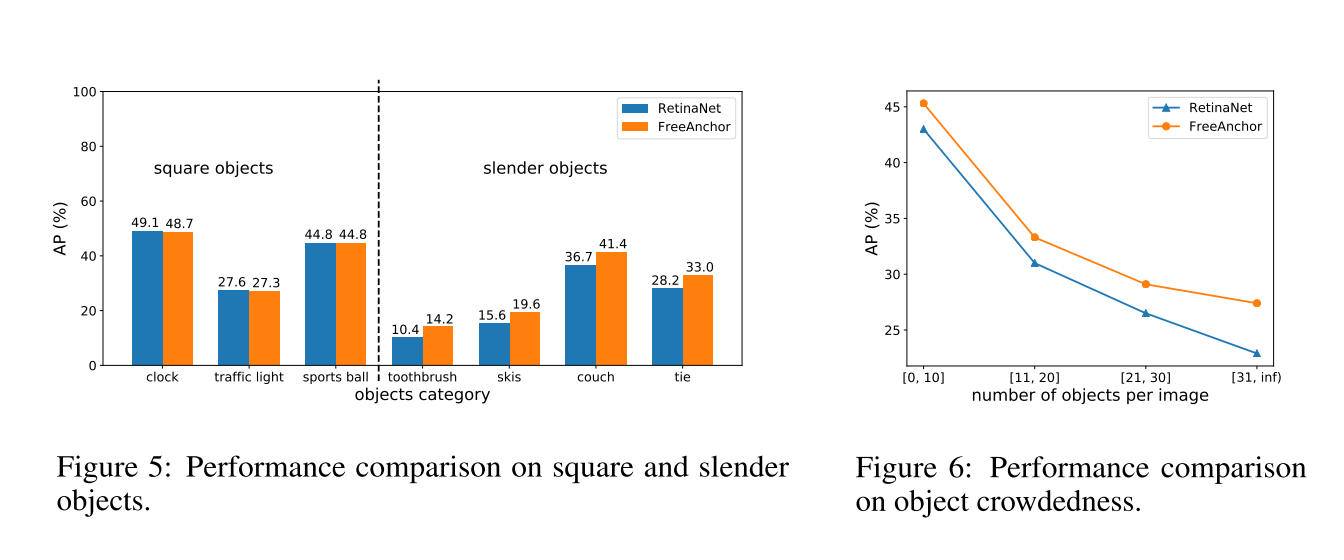
Compatibility with NMS
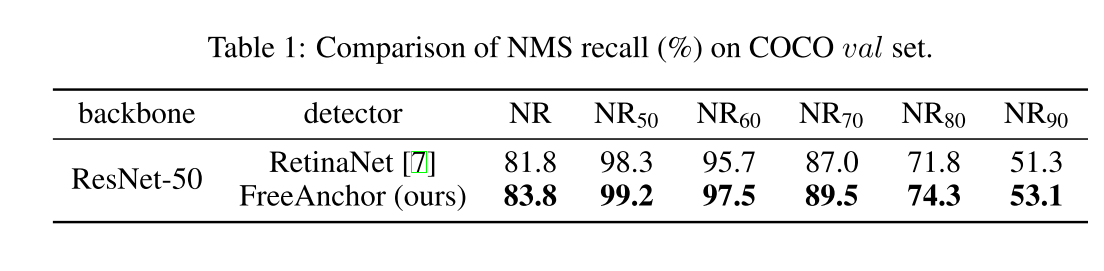
Detection Performance