Deep Contextualized Word Representations
M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, et al., Deep Contextualized Word Representations, NAACL (2018)
摘要
深度上下文词表示(deep contextualized word representation):
(1)词特征(complex characteristics of word),如语法(syntax)、语义(semantics)
(2)一词多义(vary across linguistic contexts i.e., polysemy)
本文词向量为双向深度语言模型中间状态的函数(learned functions of the internal states of a deep bidirectional language model (biLM))
验证任务:问答(question answering)、语义继承(textual entailment)、情感分析(sentiment analysis)等
1 引言
预训练词表示(pre-trained word representations)理想(ideally)建模:
(1)词特征(complex characteristics of word),如语法(syntax)、语义(semantics)
(2)一词多义(vary across linguistic contexts i.e., polysemy)
本文提出一种深度上下文词表示(deep contextualized word representation):
(1)各词条的表示为整条语句的函数(each token is assigned a representation that is a function of the entire input sentence);
(2)向量由耦合语言模型损失训练的双向LSTM导出(vectors derived from a bidirectional LSTM that is trained with a coupled language model (LM) objective on a large text corpus)。
本文称之为ELMo(Embeddings from Language Models),其中“深”指:表示为biLM所有中间层的函数(ELMo representations are deep, in the sense that they are a function of all of the internal layers of the biLM)。此外,对每个终端任务,可学习不同的向量线性组合(learn a linear combination of the vectors stacked above each input word for each end task)。
LSTM的高层LSTM向量能捕获词条的上下文相关语义(higher-level LSTM states capture context-dependent aspects of word meaning);低层向量捕获词条语法特征(lower-level states model aspects of syntax)。
■本文中,biLM指ELMo,biRNN指下游任务模型。■
2 相关工作
由于能够从大规模无标签语料库(large scale unlabeled text)中捕获词条的语法、语义信息(capture syntactic and semantic information of words),预训练词向量(pretrained word vectors)已成为顶尖NLP标准组件(a standard component of most state-of-the-art NLP architectures),如问答(question answering)、语义继承(textual entailment)、语义角色标注(semantic role labeling)。然而,早期词向量方法仅为各词条分配一个与上下文无关的单一表示(a single context-independent representation for each word)。
为克服这一缺陷,子词条信息(subword information)、词条词义向量(learning separate vectors for each word sense)等方法被提出。本文通过字符卷积从子词条中获益(benefits from subword units through the use of character convolutions),并能将多词义信息与下游任务无缝衔接(seamlessly incorporate multi-sense information into downstream tasks without explicitly training to predict predefined sense classes)。
上下文相关表示(context-dependent representations):context2vec,使用双向LSTM对引导词的上下文编码(encode the context around a pivot word)。
3 ELMo:语言模型词嵌入(ELMo: Embeddings from Language Models)
ELMo词表示(word represntations)为输入语句的函数(functions of the entire input sentence):
(1)取自字符卷积双层biLMs(computed on top of two-layer biLMs with character convolutions)
(2)中间网络状态的线性函数(a linear function of the internal network states)
通过大规模数据集预训练,biLM能够半监督学习(allows us to do semi-supervised learning, where the biLM is pretrained at a large scale),并易于加入现有NLP结构中(easily incorporated into a wide range of existing neural NLP architectures)。
3.1 双向语言模型(bidirectional language models)
给定长度为 的词条序列(a sequence of tokens), ,前向语言模型(forward language model)对序列概率的表示为:给定历史序列 ,计算词条 的概率:
后向语言模型(backward language model):
双向语言模型(biLM):同时最大化前、后向对数似然(jointly maximizes the log likelihood of the forward and backward directions):
前、后向网络的词条表示权值 和softmax权值 共享,LSTM权值独立(tie the parameters for both the token representation ( ) and Softmax layer ( ) in the forward and backward direction while maintaining separate parameters for the LSTMs in each direction)。
3.2 ELMo
ELMo的biLM中间层表示组合与任务相关(ELMo is a task specific combination of the intermediate layer representations in the biLM)。给定词条 , 层biLM计算 个表示集合(for each token , a -layer biLM computes a set of representations):
其中, 为词条层(token layer)表示、 为各biLSTM层表示。
为在下游模型引入ELMo,本文将 简化为单一向量 (for inclusion in a downstream model, ELMo collapses all layers in into a single vector),各biLM层的权值与任务相关(compute a task specific weighting of all biLM layers)
其中, 为softmax归一化权值(softmax-normalized weights)、标量参数(scalar parameter) 使任务模型能够对ELMo向量缩放(allows the task model to scale the entire ELMo vector)
3.3 监督NLP任务(using biLMs for supervised NLP tasks)
给定预训练biLM和目标NLP任务的监督结构(a supervised architecture for a target NLP task)
(1)运行biLM,记录各词条的所有层表示(record all of the layer representations for each word)
(2)使终端任务模型学习所有表示的线性组合(let the end task model learn a linear combination of these representations)
3.4 biLM结构(pre-trained bidirectional language model architecture)
双向联合训练(support joint training of both directions)、LSTM层间通过残差相连(add a residual connection between LSTM layers)
层biLSTM,输入4096维、输出512维(L = 2 biLSTM layers with 4096 units and 512 dimension projections);biLSTM之间通过残差相连。
2048字符 -gram卷积、512维线性投影(context insensitive type representation uses 2048 character -gram convolutional filters followed by two highway layers and a linear projection down to a 512 representation)
在1B Word Benchmark数据集上进行10轮训练,前、后向平均困惑度(average forward and backward perplexities)为39.7。
4 评估(Evaluation)
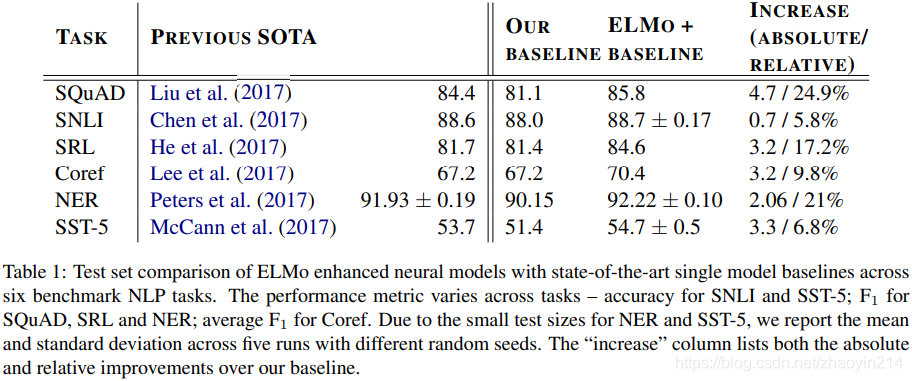
问答(question answering)
SQuAD(Stanford Question Answering Dataset)
语义继承(textual entailment)
语义继承:给定前提,判断假设是否成立(textual entailment is the task of determining whether a “hypothesis” is true, given a “premise”)。
SNLI(Stanford Natural Language Inference)
语义角色标注(semantic role labeling)
语义角色标注:判断语句结构,谁对谁做了什么(a semantic role labeling (SRL) system models the predicate-argument structure of a sentence, and is often described as answering “Who did what to whom”)。
指代消解(coreference resolution)
指代消解:文本中代词所指(coreference resolution is the task of clustering mentions in text that refer to the same underlying real world entities)
命名实体识别(named entity extraction)
CoNLL 2003 NER
情感分析(sentiment analysis)
SST-5(Stanford Sentiment Treebank),五分类
5 分析(Analysis)
biLM模型的低层捕获语法信息,而高层捕获语义信息(syntactic information is better represented at lower layers while semantic information is captured a higher layers)。
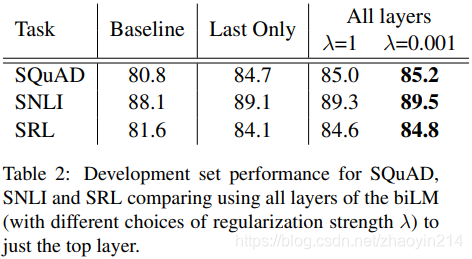
5.1 层加权策略(Alternate layer weighting schemes)
正则参数(regularization parameter) :
(1) ,权值方程简化为平均加权(reduce the weighting function to a simple average over the layers)
(2)减小 ,例如 ,各层权值可变(smaller values allow the layer weights to vary)
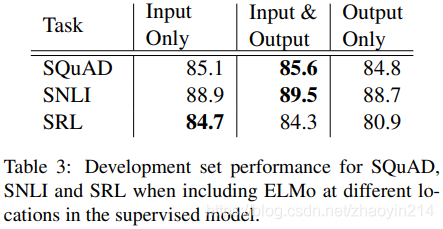
5.2 ELMo引入位置(Where to include ELMo?)
biRNN的输入、输出均可引入ELMo
5.3 biLM表示的信息(What information is captured by the biLM’s representations?)
biLM必须能够通过上下文区分词义(the biLM must be disambiguating the meaning of words using their context)
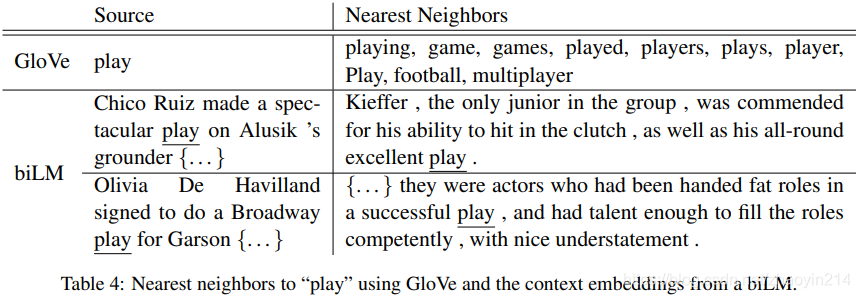
词义辨析(word sense disambiguation)
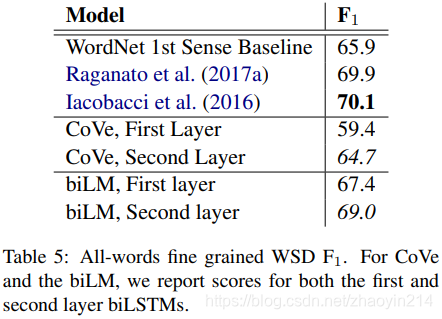
词性标注(POS tagging)
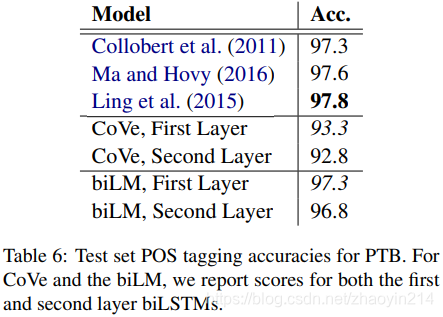
对监督任务的启示(implications for supervised tasks)
5.4 样本效率(sample efficiency)
ELMo能够加快训练速度、减小训练集规模,从而提升样本效率(adding ELMo to a model increases the sample efficiency considerably, both in terms of number of parameter updates to reach state-of-the-art performance and the overall training set size)。
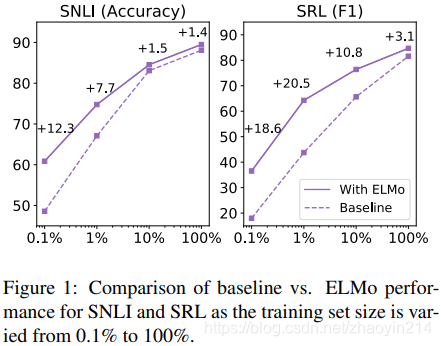
5.5 权值可视化(Visualization of learned weights)

