《Advances in Pre-Training Distributed Word Representations》
Tomas Mikolov, Edouard Grave, Piotr Bojanowski, Christian Puhrsch, Armand Joulin,2017
Abstract
现在许多自然语言处理应用程序都依赖从大型文本语料库(如新闻集、维基百科和网络爬取)预先训练的词向量表示。在本文中,我们展示了如何使用已知但很少组合使用的技巧来训练高质量的单词向量表示。我们工作的主要成果是一系列新的公开使用的预训练模型,在许多任务上大大优于现有的技术水平。
1. Introduction
预先训练的连续词汇表示已经成为许多自然语言处理(NLP)和机器学习应用的基本构建模块。这些预先训练的表示提供了有关单词的分布信息,这通常会提高在有限数据集上学习的模型的泛化能力。这些信息通常来源于大量未标记的数据集。因此,训练的一个关键方面是尽可能多的从丰富广泛的数据来源中获取尽可能多的信息。
学习单词表示的标准方法是根据word2vec和fast-Text中实现的Skip-Gram模型或CBOW连续词袋模型体系训练对数双线性模型。在Skip-Gram模型中,给定一个目标词预测附近的单词,而在CBOW模型中,根据其上下文预测源单词。这些体系结构及其实现已被优化,以产生高质量字表示从而转移到更多任务,同时保持足够高的训练速度来缩放大量的数据。
最近,word2vec表示已被广泛应用于NLP来提高其性能,其性能表明他们正在获取有关训练语料库的重要统计数据。可以看出,一个模型训练得数据越多,其获得的词表示就能越好的转移到其他NLP问题。在大规模数据源(如Common Crawl)上训练这样的模型可能会很麻烦,许多NLP从业者更喜欢使用公开的预先训练过的单词向量来自行训练模型。在这项工作中,我们提供了新的预先训练的单词向量,与当前已有的向量相比有了改进,并且会有更广泛的使用。
对于标准的word2vec的基础修改显著提高了获得的单词向量的质量。我们主要关注已知的修改和数据预处理策略,他们很少一起使用:由Mnih and Kavukcuoglu (2013)引入的位置相关特征,Mikolov et al. (2013b)使用的短语表示和(Bojanowski et al., 2017)使用的子词信息。
我们使用标准的基准来衡量他们的质量:句法、语义和基于短语的类比(Mikolov et al., 2013b),稀有词数据集(Luong et al., 2013),并且作为Squad question answering dataset的特征(Rajpurkar et al., 2016; Chen et al., 2017)。
2. Model Description
在这一部分,我们简单的描述word2vec中使用的cbow模型,然后解释几个一致的改进方法,以学习更丰富的词表示。
2.1. Standard cbow model
在Mikolov et al. (2013a)中使用的cbow模型通过预测上下文的单词来学习词表示。上下文由包含周围词的对称窗口所定义。更准确的说,给定
其中,
其中,
该模型的自然化参数是用向量
注意,上下文中的单词和预测的单词使用不同的单数。
Word subsampling: 标准文本语料库中的词语频率分布遵循Zipf分布,这意味着大部分词汇属于整个单词表的一个小的子集(Li, 1992)。考虑到平等地对待所有出现的词,会导致模型在最频繁出现的词表示上发生参数过度拟合,而对其他词则会欠拟合。Mikolov et al. (2013a)引入的一个策略是对频繁的词进行二次抽样,用以下的概率对词进行丢弃:
其中
2.2. Position-dependent Weighting
上面描述的上下文向量只是包含在其中的单词向量的平均值。这种表示忽视了每个单词的位置。对一个单词和它的位置进行显式编码的表示将是不切实际的,容易过度拟合。Mnih and Kavukcuoglu (2013)引入一个简单而有效的解决方案,是在单词表示的上下文中,学习位置表示并使用它们来重新赋予单词向量。这种依赖于位置的加权以最小的计算成本提供更丰富的上下文表示。
上下文窗口中的每个位置
其中
2.3. Phrase representations
原始的cbow模型仅仅基于unigrams,其对单词顺序不敏感。我们用word n-gram来丰富这个模型,以获取更丰富的信息。将n-gram直接纳入模型是非常具有挑战性的,因为参数数量的大量增加导致模型内容不明确。 相反,我们遵循Mikolov et al. (2013b)的方法,通过迭代地将互信息标准应用于bigrams来选择n-gram。然后,在数据预处理步骤中,我们将所选n-gram中的单词合并成单个token(词组)。例如,像“New York”这样具有高度互信息的词汇被合并在一个双重标记“New York”中。这个预处理步骤被重复几次,以形成更长的n-gram标记,如“New York City”或“New York University”。在实践中,我们重复这个过程5-6次来构建代表较长ngram的token。我们使用word2vec project2中的word2phrase工具。需要注意的是,互信息量高的unigrams只能以50%的概率进行合并,因此我们仍然保留了大量的unigram事件。即使在应用中没有进一步使用短语表示,它们也有效地提高了词向量的质量,如实验部分所示。
2.4. Subword information
标准的单词向量忽略了单词内部结构,而内部结构往往包含丰富的信息。这些信息可以用于计算罕见的或拼写错误的单词,以及丰富多彩的语言(如芬兰语或土耳其语等)。一个简单而有效的方法是用a bag of character n-gram vectors来丰富单词向量,这些向量或者是从共生矩阵的奇异值分解得出的(Sch¨utze, 1993),或者是从大量的数据集中直接学习的(Bojanowski et al., 2017). 。在后者中,每个单词被分解成它的特征n-gram
实际上,n-grams
3. Training Data
我们使用了几种公开的文本数据源和Gigaword数据集,如表1所示。我们使用从2017.6起的英文维基,其中使用元页面存档,导致文本语料库超过90亿字。此外,我们使用了2007年至2016年的所有来自statmt.org的新闻数据集,UMBC语料库(Han et al., 2013),英语Gigaword以及2017年5月的通用网络爬取。

在Common Crawl情况下,我们编写了一个简单的基于单语言模型的数据提取器,用于检索用英文书写的文档,并丢弃低质量的数据。实际上,同样的方法可以用于从“Common Crawl”中提取许多其他语言的文本数据。我们决定不进行复杂的数据标准化或预处理,因为我们希望所得到的单词向量能够被广泛使用(文本标准化可以在发布的单词向量之上作为后续处理步骤完成)。我们只使用了Moses MT 项目中公开的tokenizer.perl脚本。我们观察到,对大文本训练语料库进行重复数据删除,特别是“Common Crawl”,显着提高了结果词向量的质量。
4. Results
我们会报告在“Common Crawl”,或者维基百科,Statmt News,UMBC和Gigaword的组合上进行培训模型的结果。其效果可以与其他试图改进word2vec的模型使用的语料库相媲美,尤其是斯坦福NLP组的GloVe模型(Pennington et al., 2014)。尽管Levy et al. (2015) 的分析表明,原来的word2vec训练速度更快,能够产生更精确的模型,并且比GloVe算法话费的内存更少,但是许多研究人员没有时间在非常大的语料集(如Common Crawl)上训练他们自己的模型,此时大规模预训练GloVe模型对他们来说就是非常有用的。
我们使用了第2.1节中描述的cbow架构。 基线模型的窗口大小为5,学习位置相关权值的模型(在2.2节中描述)的窗口大小为15。我们用10个负样本的例子进行训练,负采样和子采样频繁字的阈值设置为
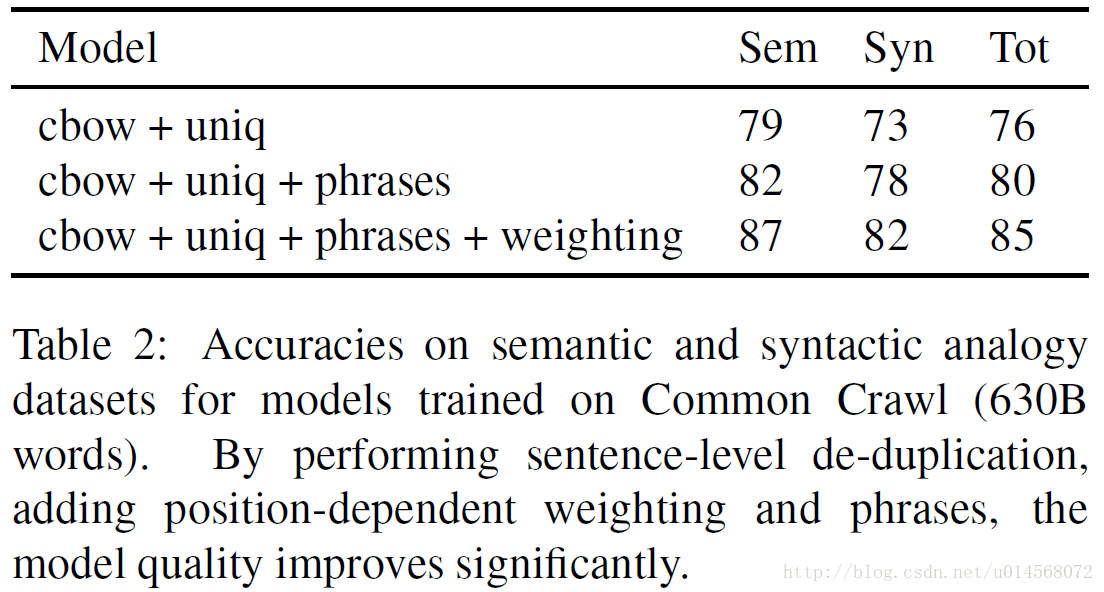
在表3中,我们可以看到 fastText库(Bojanowski et al., 2017)中实现的cbow和在语料库上训练的GloVe模型之间的比较。在词类比任务中,87%的准确性是迄今为止我们所知的最好的公布结果,比Glove模型要好得多。我们通过添加子字特征将这个结果进一步提高到了88.5%的准确度。
我们还在稀有词数据集(Luong et al., 2013)上报告了非常好的表现,再次大幅超越Glove模型。最后,我们用训练在Squad数据集上的问答系统(Rajpurkar et al., 2016)将GloVe预训练的向量替换为新的fastText向量。在Chen et al. (2017)的进一步描述中,我们确实观察到精度的显着提高。
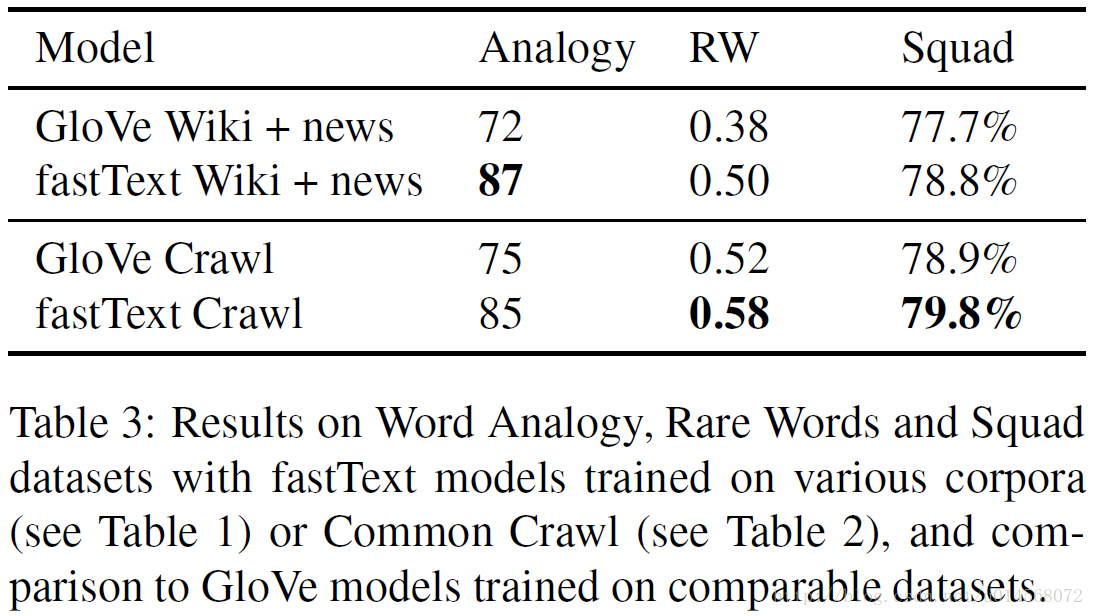
维基百科和新闻语料库以及“Common Crawl”上训练的模型已在fasttext.cc网站上发布,可供NLP研究人员使用。我们还对Mikolov et al. (2013b)中引入的基于短语的类比数据集进行了实验,并使用Crawl训练的模型达到了88%的准确率,这也是我们所了解的最新的最新技术成果。我们计划在不久的将来发布包含所有短语的模型。
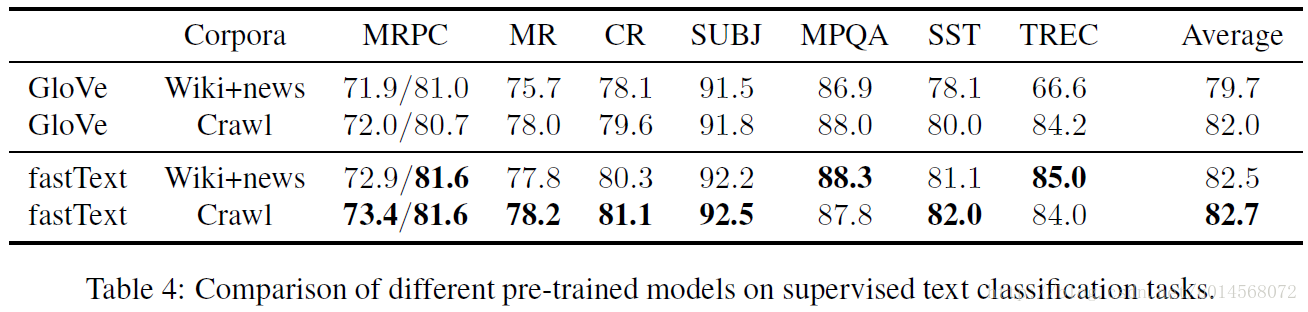
最后在表4中,我们使用由Conneau et al. (2017)提供的脚本来测量不同的预先训练的单词向量模型对几个文本分类任务(MRPC,MR CR,SUBJ,MPQA,SST和TREC)的影响。我们使用在监督模式下运行的标准fastText工具包(Joulin et al., 2016)来执行分类,使用预先训练的模型来初始化分类器。总的来说,新的快速文本词向量展示出更出色的文本分类性能。
5. Discussion
在这项工作中,我们旨在提供高质量的预先训练的单词和短语向量表示集。我们的研究结果表明,可以通过在非常大的文本数据集上训练已知算法来实现改进,并且使用某些技巧可以进一步提高质量。值得注意的是,在训练模型之前,我们发现在大规模语料库(如Common Crawl)中去除重复的句子非常重要。接下来,我们使用了一个在预处理步骤中构建短语的算法。最后,在cbow模型体系结构中添加依赖于位置的权重和子词特征,最终提高了准确性。本文描述的模型可以在fastText网页免费提供给研究人员和工程师,我们希望这些模型在使用文本数据的各种项目中都有用。