Hive 压缩
对于数据密集型任务,I/O操作和网络数据传输需要花费相当长的时间才能完成。通过在 Hive 中启用压缩功能,我们可以提高 Hive 查询的性能,并节省 HDFS 集群上的存储空间。
HiveQL语句最终都将转换成为hadoop中的MapReduce job,而MapReduce job可以有对处理的数据进行压缩。
首先说明mapreduce哪些过程可以设置压缩:需要分析处理的数据在进入map前可以压缩,然后解压处理,map处理完成后的输出可以压缩,这样可以减少网络I/O(reduce通常和map不在同一节点上),reduce拷贝压缩的数据后进行解压,处理完成后可以压缩存储在hdfs上,以减少磁盘占用量。
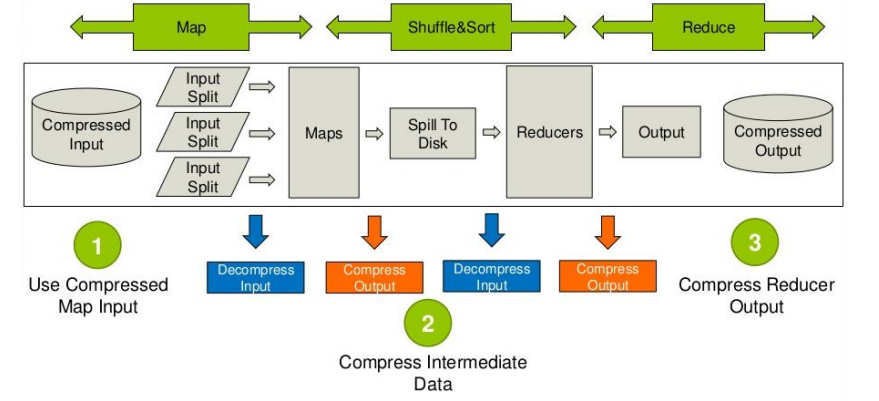
Hive中间数据压缩
提交后,一个复杂的 Hive 查询通常会转换为一系列多阶段 MapReduce 作业,这些作业将通过 Hive 引擎进行链接以完成整个查询。因此,这里的 ‘中间输出’ 是指前一个 MapReduce 作业的输出,将会作为下一个 MapReduce 作业的输入数据。
可以通过使用 Hive Shell 中的 set 命令或者修改 hive-site.xml 配置文件来修改 hive.exec.compress.intermediate 属性,这样我们就可以在 Hive Intermediate 输出上启用压缩。
hive.exec.compress.intermediate:默认为false,设置true为激活中间数据压缩功能,就是MapReduce的shuffle阶段对mapper产生中间压缩。可以使用 set 命令在 hive shell 中设置这些属性
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec
或者
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec
也可以在配置文件中进行配置
<property>
<name>hive.exec.compress.intermediate</name>
<value>true</value>
<description>
This controls whether intermediate files produced by Hive between multiple map-reduce jobs are compressed.
The compression codec and other options are determined from Hadoop config variables mapred.output.compress*
</description>
</property>
<property>
<name>hive.intermediate.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description/>
</property>
最终输出结果压缩
hive.exec.compress.output:用户可以对最终生成的Hive表的数据通常也需要压缩。该参数控制这一功能的激活与禁用,设置为true来声明将结果文件进行压缩。
mapred.output.compression.codec:将hive.exec.compress.output参数设置成true后,然后选择一个合适的编解码器,如选择SnappyCodec。设置如下(两种压缩的编写方式是一样的):
set hive.exec.compress.output=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
或者
set mapred.output.compress=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.LzopCodec
同样可以通过配置文件配置
<property>
<name>hive.exec.compress.output</name>
<value>true</value>
<description>
This controls whether the final outputs of a query (to a local/HDFS file or a Hive table) is compressed.
The compression codec and other options are determined from Hadoop config variables mapred.output.compress*
</description>
</property>
常见的压缩格式
Hive支持的压缩格式有bzip2、gzip、deflate、snappy、lzo等。Hive依赖Hadoop的压缩方法,所以Hadoop版本越高支持的压缩方法越多,可以在$HADOOP_HOME/conf/core-site.xml中进行配置:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec
</value>
</property>
<property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
需要注意的是在我们在hive配置开启压缩之前,我们需要配置让Hadoop 支持,因为hive 开启压缩只是指明了使用哪一种压缩算法,具体的配置还是需要在Hadoop 中配置
常见的压缩格式有:
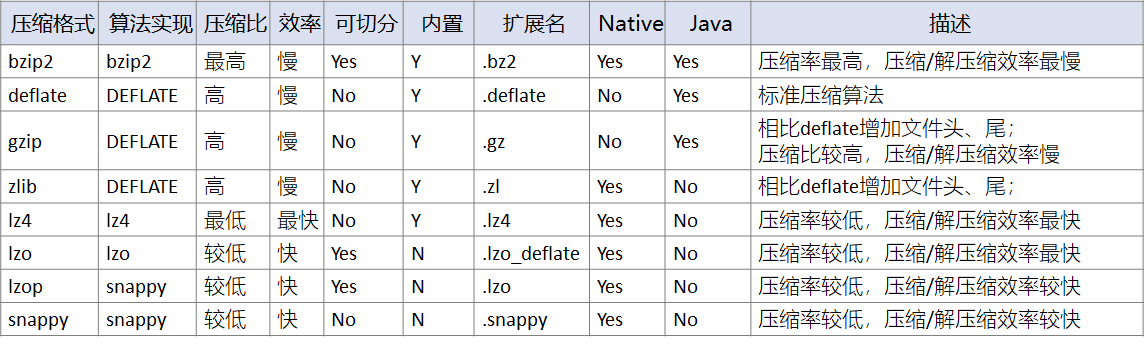
其中压缩比bzip2 > zlib > gzip > deflate > snappy > lzo > lz4,在不同的测试场景中,会有差异,这仅仅是一个大概的排名情况。bzip2、zlib、gzip、deflate可以保证最小的压缩,但在运算中过于消耗时间。
从压缩性能上来看:lz4 > lzo > snappy > deflate > gzip > bzip2,其中lz4、lzo、snappy压缩和解压缩速度快,压缩比低。
所以一般在生产环境中,经常会采用lz4、lzo、snappy压缩,以保证运算效率。
| 压缩格式 | 对应的编码/解码 |
|---|---|
| DEFAULT | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip | org.apache.hadoop.io.compress.BzipCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
| Lzo | org.apache.hadoop.io.compress.LzopCodec |
对于使用 Gzip or Bzip2 压缩的文件我们是可以直接导入到text 存储类型的表中的,hive 会自动帮我们完成数据的解压
CREATE TABLE raw (line STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
LOAD DATA LOCAL INPATH '/tmp/weblogs/20090603-access.log.gz' INTO TABLE raw;
Native Libraries
Hadoop由Java语言开发,所以压缩算法大多由Java实现;但有些压缩算法并不适合Java进行实现,会提供本地库Native Libraries补充支持。Native Libraries除了自带bzip2, lz4, snappy, zlib压缩方法外,还可以自定义安装需要的功能库(snappy、lzo等)进行扩展。而且使用本地库Native Libraries提供的压缩方式,性能上会有50%左右的提升。
使用命令可以查看native libraries的加载情况:
hadoop checknative -a

完成对Hive表的压缩,有两种方式:配置MapReduce压缩、开启Hive表压缩功能。因为Hive会将SQL作业转换为MapReduce任务,所以直接对MapReduce进行压缩配置,可以达到压缩目的;当然为了方便起见,Hive中的特定表支持压缩属性,自动完成压缩的功能。
Hive中的可用压缩编解码器
要在 Hive 中启用压缩,首先我们需要找出 Hadoop 集群上可用的压缩编解码器,我们可以使用下面的 set 命令列出可用的压缩编解码器。
hive> set io.compression.codecs;
io.compression.codecs=
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
演示
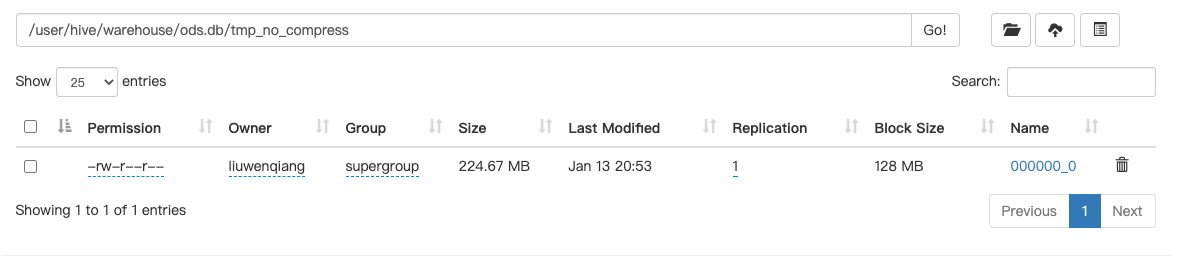
首先我们创建一个未经压缩的表tmp_no_compress
CREATE TABLE tmp_no_compress ROW FORMAT DELIMITED LINES TERMINATED BY '\n'
AS SELECT * FROM log_text;
我们看一下不设置压缩属性的输出
在 Hive Shell 中设置压缩属性:
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
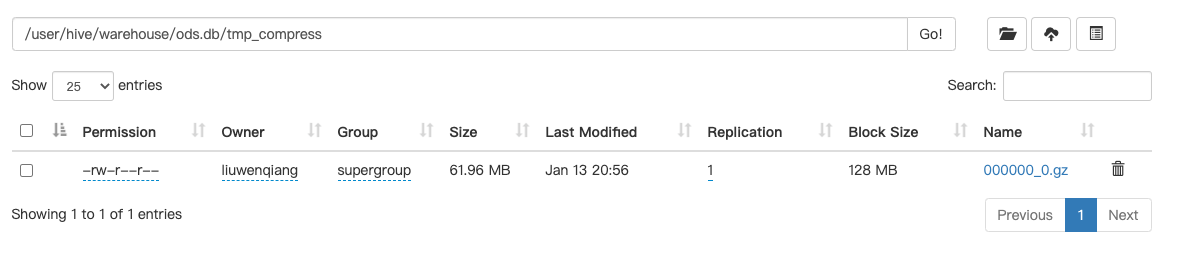
根据现有表 tmp_order_id 创建一个压缩后的表 tmp_order_id_compress:
CREATE TABLE tmp_compress ROW FORMAT DELIMITED LINES TERMINATED BY '\n'
AS SELECT * FROM log_text;
我们在看一下设置压缩属性后输出:
总结
- 数据压缩可以发生在哪些阶段 1 输入数据可以压缩后的数据 2 中间的数据可以压缩 3 输出的数据可以压缩
- hive 仅仅是配置了开启压缩和使用哪种压缩方式,真正的配置是在hadoop 中配置的,而数据的压缩是在MapReduce 中发生的
- 对于数据密集型任务,I/O操作和网络数据传输需要花费相当长的时间才能完成。通过在 Hive 中启用压缩功能,我们可以提高 Hive 查询的性能,并节省 HDFS 集群上的存储空间。