文件存储格式
从Hive官网得知,Apache Hive支持Apache Hadoop中使用的几种熟悉的文件格式,如 TextFile(文本格式),RCFile(行列式文件),SequenceFile(二进制序列化文件),AVRO,ORC(优化的行列式文件)和Parquet 格式,而这其中我们目前使用最多的是TextFile,SequenceFile,ORC和Parquet。
下面来详细了解下这2种行列式存储。
1、ORC
1.1 ORC的存储结构
我们先从官网上拿到ORC的存储模型图
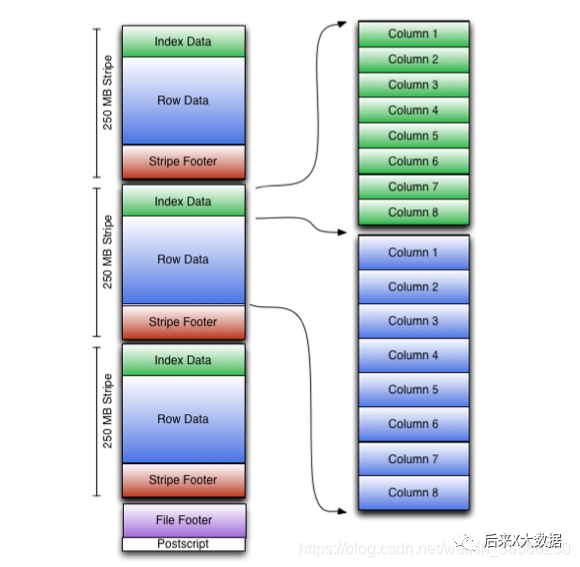
看起来略微有点复杂,那我们稍微简化一下,我画了一个简单的图来说明一下
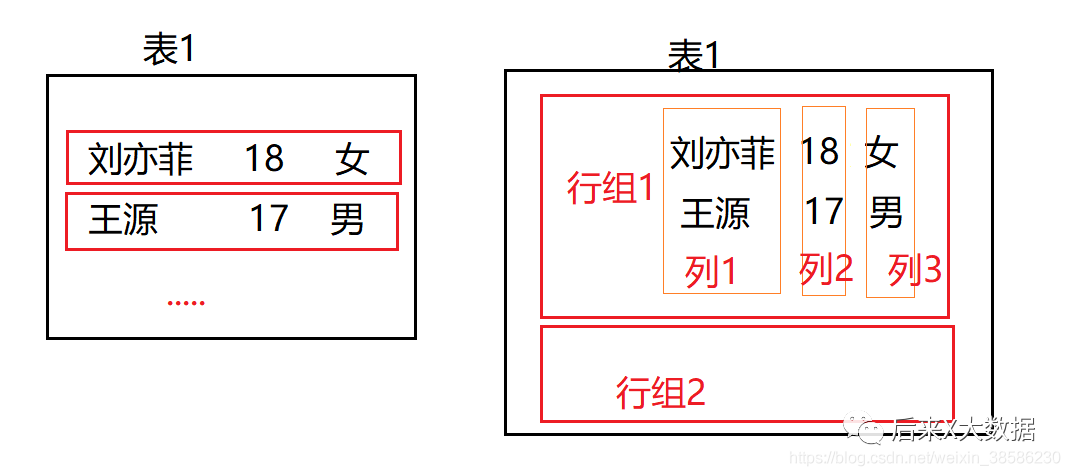
左边的图就表示了传统的行式数据库存储方式,按行存储,如果没有存储索引的话,如果需要查询一个字段,就需要把整行的数据都查出来然后做筛选,这么做是比较消耗IO资源的,于是在Hive中最开始也是用了索引的方式来解决这个问题。
但是由于索引的高成本,在「目前的Hive3.X 中,已经废除了索引」,当然也早就引入了列式存储。
列式存储的存储方式,是按照一列一列存储的,如上图中的右图,这样的话如果查询一个字段的数据,就等于是索引查询,效率高。但是如果需要查全表,它因为需要分别取所有的列最后汇总,反而更占用资源。于是ORC行列式存储出现了。
-
在需要全表扫描时,可以按照行组读取
-
如果需要取列数据,在行组的基础上,读取指定的列,而不需要所有行组内所有行的数据和一行内所有字段的数据。
了解了ORC存储的基本逻辑后,我们再来看看它的存储模型图。
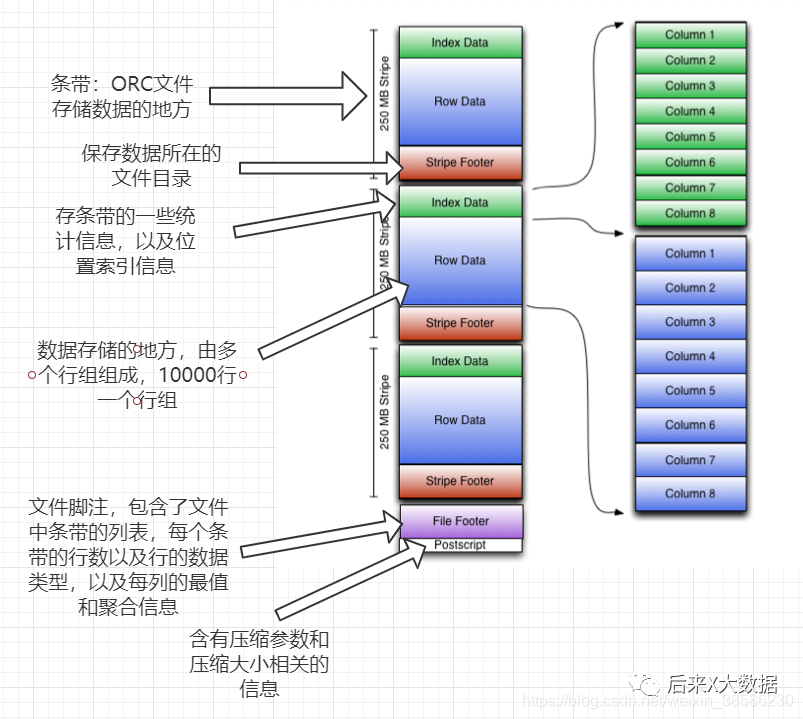
同时我也把详细的文字也附在下面,大家可以对照着看看:
-
条带( stripe):ORC文件存储数据的地方,每个stripe一般为HDFS的块大小。(包含以下3部分)
index data:保存了所在条带的一些统计信息,以及数据在 stripe中的位置索引信息。
rows data:数据存储的地方,由多个行组构成,每10000行构成一个行组,数据以流( stream)的形式进行存储。
stripe footer:保存数据所在的文件目录
-
文件脚注( file footer):包含了文件中sipe的列表,每个 stripe的行数,以及每个列的数据类型。它还包含每个列的最小值、最大值、行计数、求和等聚合信息。
-
postscript:含有压缩参数和压缩大小相关的信息
所以其实发现,ORC提供了3级索引,文件级、条带级、行组级,所以在查询的时候,利用这些索引可以规避大部分不满足查询条件的文件和数据块。
但注意,ORC中所有数据的描述信息都是和存储的数据放在一起的,并没有借助外部的数据库。
「特别注意:ORC格式的表还支持事务ACID,但是支持事务的表必须为分桶表,所以适用于更新大批量的数据,不建议用事务频繁的更新小批量的数据」
#开启并发支持,支持插入、删除和更新的事务
set hive. support concurrency=truei
#支持ACID事务的表必须为分桶表
set hive. enforce bucketing=truei
#开启事物需要开启动态分区非严格模式
set hive.exec,dynamicpartition.mode-nonstrict
#设置事务所管理类型为 org. apache.hive.q1. lockage. DbTxnManager
#原有的org. apache. hadoop.hive.q1.1 eckmar. DummyTxnManager不支持事务
set hive. txn. manager=org. apache. hadoop. hive. q1. lockmgr DbTxnManageri
#开启在相同的一个 meatore实例运行初始化和清理的线程
set hive. compactor initiator on=true:
#设置每个 metastore实例运行的线程数 hadoop
set hive. compactor. worker threads=l
#(2)创建表
create table student_txn
(id int,
name string
)
#必须支持分桶
clustered by (id) into 2 buckets
#在表属性中添加支持事务
stored as orc
TBLPROPERTIES('transactional'='true‘);
#(3)插入数据
#插入id为1001,名字为student 1001
insert into table student_txn values('1001','student 1001');
#(4)更新数据
#更新数据
update student_txn set name= 'student 1zh' where id='1001';
# (5)查看表的数据,最终会发现id为1001被改为 sutdent_1zh
1.2关于ORC的Hive配置
表配置属性(建表时配置,例如tblproperties ('orc.compress'='snappy');)
-
orc.compress:表示ORC文件的压缩类型,「可选的类型有NONE、ZLB和SNAPPY,默认值是ZLIB(Snappy不支持切片)」---这个配置是最关键的。
-
orc. compress.Slze:表示压缩块( chunk)的大小,默认值是262144(256KB)。
-
orc. stripe.size:写 stripe,可以使用的内存缓冲池大小,默认值是67108864(64MB)
-
orc. row. index. stride:行组级别索引的数据量大小,默认是10000,必须要设置成大于等于10000的数
-
orc. create index:是否创建行组级别索引,默认是true
-
orc. bloom filter. columns:需要创建布隆过滤的组。
-
orc. bloom filter fpp:使用布隆过滤器的假正( False Positive)概率,默认值是0.
扩展:在Hive中使用 bloom过滤器,可以用较少的文件空间快速判定数据是否存表中,但是也存在将不属于这个表的数据判定为属于这个这表的情况,这个称之为假正概率,开发者可以调整该概率,但概率越低,布隆过滤器所需要
2、Parquet
上面说过ORC后,我们对行列式存储也有了基本的了解,而Parquet是另一种高性能的行列式存储结构。
2.1 Parquet的存储结构
既然ORC都那么高效了,那为什么还要再来一个Parquet,那是因为「Parquet是为了使Hadoop生态系统中的任何项目都可以使用压缩的,高效的列式数据表示形式」
❝Parquet 是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与 Parquet 配合的组件有:
查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
数据模型: Avro, Thrift, Protocol Buffers, POJOs
❞
再来看看Parquet的存储结构吧,先看官网给的

嗯,略微有点头大,我画个简易版
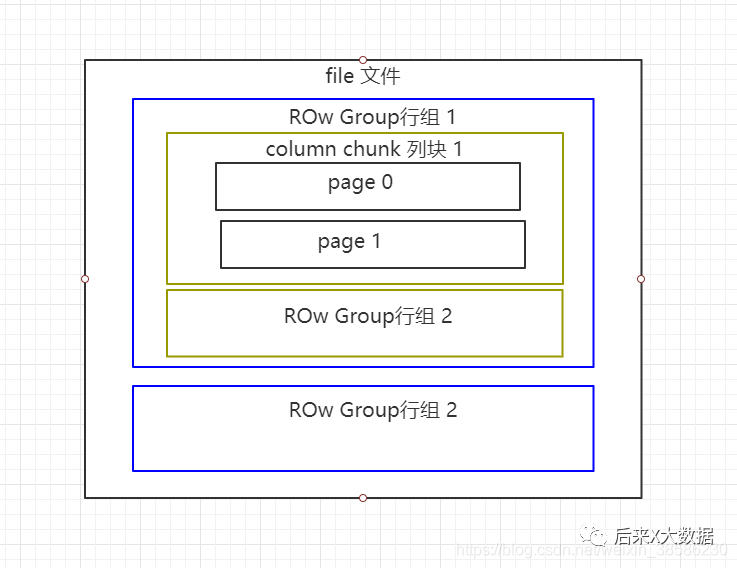
Parquet文件是以二进制方式存储的,所以不可以直接读取,和ORC一样,文件的元数据和数据一起存储,所以Parquet格式文件是自解析的。
-
行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
-
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
-
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
2.2Parquet的表配置属性
-
parquet. block size:默认值为134217728byte,即128MB,表示 Row Group在内存中的块大小。该值设置得大,可以提升 Parquet文件的读取效率,但是相应在写的时候需要耗费更多的内存
-
parquet. page:size:默认值为1048576byt,即1MB,表示每个页(page)的大小。这个特指压缩后的页大小,在读取时会先将页的数据进行解压。页是 Parquet操作数据的最小单位,每次读取时必须读完一整页的数据才能访问数据。这个值如果设置得过小,会导致压缩时出现性能问题
-
parquet. compression:默认值为 UNCOMPRESSED,表示页的压缩方式。「可以使用的压缩方式有 UNCOMPRESSED、 SNAPPY、GZP和LZO」。
-
Parquet enable. dictionary:默认为tue,表示是否启用字典编码。
-
parquet. dictionary page.size:默认值为1048576byte,即1MB。在使用字典编码时,会在 Parquet的每行每列中创建一个字典页。使用字典编码,如果存储的数据页中重复的数据较多,能够起到一个很好的压缩效果,也能减少每个页在内存的占用。
3、ORC和Parquet对比
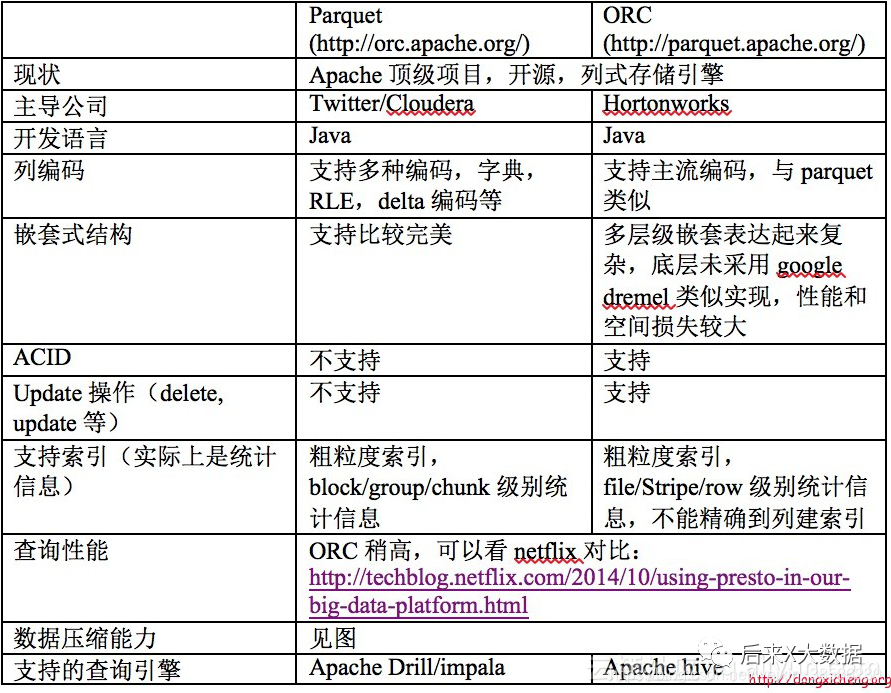
同时,从《Hive性能调优实战》作者的案例中,2张分别采用ORC和Parquet存储格式的表,导入同样的数据,进行sql查询,「发现使用ORC读取的行远小于Parquet」,所以使用ORC作为存储,可以借助元数据过滤掉更多不需要的数据,查询时需要的集群资源比Parquet更少。(查看更详细的性能分析,请移步https://blog.csdn.net/yu616568/article/details/51188479)
「所以ORC在存储方面看起来还是更胜一筹」
压缩方式
| 格式 | 可分割 | 平均压缩速度 | 文本文件压缩效率 | Hadoop压缩编解码器 | 纯Java实现 | 原生 | 备注 |
|---|---|---|---|---|---|---|---|
| gzip | 否 | 快 | 高 | org.apache.hadoop.io.compress.GzipCodec | 是 | 是 | |
| lzo | 是(取决于所使用的库) | 非常快 | 中等 | com.hadoop.compression.lzo.LzoCodec | 是 | 是 | 需要在每个节点上安装LZO |
| bzip2 | 是 | 慢 | 非常高 | org.apache.hadoop.io.compress.Bzip2Codec | 是 | 是 | 为可分割版本使用纯Java |
| zlib | 否 | 慢 | 中等 | org.apache.hadoop.io.compress.DefaultCodec | 是 | 是 | Hadoop 的默认压缩编解码器 |
| Snappy | 否 | 非常快 | 低 | org.apache.hadoop.io.compress.SnappyCodec | 否 | 是 | Snappy 有纯Java的移植版,但是在Spark/Hadoop中不能用 |
存储和压缩结合该如何选择?
根据ORC和parquet的要求,一般就有了
1、ORC格式存储,Snappy压缩
create table stu_orc(id int,name string)
stored as orc
tblproperties ('orc.compress'='snappy');
2、Parquet格式存储,Lzo压缩
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='lzo');
3、Parquet格式存储,Snappy压缩
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='snappy');
因为Hive 的SQL会转化为MR任务,如果该文件是用ORC存储,Snappy压缩的,因为Snappy不支持文件分割操作,所以压缩文件「只会被一个任务所读取」,如果该压缩文件很大,那么处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间,这就是常说的「Map读取文件的数据倾斜」。
那么为了避免这种情况的发生,就需要在数据压缩的时候采用bzip2和Zip等支持文件分割的压缩算法。但恰恰ORC不支持刚说到的这些压缩方式,所以这也就成为了大家在可能遇到大文件的情况下不选择ORC的原因,避免数据倾斜。
在Hve on Spark的方式中,也是一样的,Spark作为分布式架构,通常会尝试从多个不同机器上一起读入数据。要实现这种情况,每个工作节点都必须能够找到一条新记录的开端,也就需要该文件可以进行分割,但是有些不可以分割的压缩格式的文件,必须要单个节点来读入所有数据,这就很容易产生性能瓶颈。