Hive SerDe
SerDe是Serializer/Deserializer的缩写。序列化是对象转换成字节序列的过程。反序列化是字节序列转换成对象的过程。
对象的序列化主要有两种用途:
- 对象的持久化,即把对象转换成字节序列后保存到文件。
- 对象数据的网络传输。
Hive使用SerDe接口完成IO操作也就是数据的读取和写入,hive本身并不存储数据,它用的是hdfs上存储的文件,在与hdfs的文件交互读取和写入的时候需要用到序列化。
Hive Serde用来做序列化和反序列化,构建在数据存储和执行引擎之间,对两者实现解耦。 org.apache.hadoop.hive.serde 已经被淘汰了,现在主要使用 org.apache.hadoop.hive.serde2 ,SerDe允许Hive从表中读入数据,然后以任何自定义格式将数据写回HDFS。任何人都可以为自己的数据格式编写自己的SerDe。
所以序列化(serialize)是将导入的数据转成hadoop的Writable格式,反序列化就是将HDFS 上的数据导入到内存中形成row object
Hive 的读写流程
其实SerDe就是Hive 的序列化和反序列化的组件,主要用在读写数据上,下面就是Hive 读写的过程
读取 HDFS files --> InputFileFormat --> <key, value> --> Deserializer --> Row object
写出 Row object --> Serializer --> <key, value> --> OutputFileFormat --> HDFS files
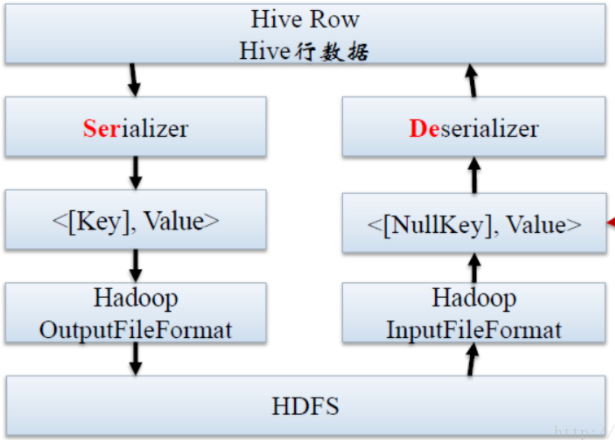
需要注意的是key 这部分在读取的时候会被忽略,写入的时候是一个常量,通常情况下Row object存储在value 中
我们前面学习Hive 的架构的时候说过,hive 本身并不存储数据,所以它也就没有数据格式而言,用户可以使用任何工具直接读取Hive表中的HDFS 文件,也可以直接向HDFS 上写文件然后可以通过创建外部表CREATE EXTERNAL TABLE或者LOAD DATA INPATH 来使用数据文件,LOAD DATA INPATH 会将数据移动到Hive 表的文件夹下
SerDe 的使用
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)]
INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
如上创建表语句, 使用 row format 参数来指定 SerDe 的类型。
Hive 的 SerDe
Hive 内置的 SerDe 类型
-
TextInputFormat/HiveIgnoreKeyTextOutputFormat: 这个两个类主要用来操作文本文件
-
SequenceFileInputFormat/SequenceFileOutputFormat: 这两个类主要用来操作Hadoop 的SequenceFile文件
-
MetadataTypedColumnsetSerDe 这个类主要用来读写特定分隔符分割的文件,例如CSV 文件或者tab 、control-A 分割的文件(quote is not supported yet)
-
LazySimpleSerDe
这个是默认的 SerDe 类型。读取与 MetadataTypedColumnsetSerDe 和 TCTLSeparatedProtocol 相同的数据格式,可以用这个 Hive SerDe 类型。它是以惰性的方式创建对象的,因此具有更好的性能。在 Hive 0.14.0 版本以后,在读写数据时它支持指定字符编码。例如:
ALTER TABLE person SET SERDEPROPERTIES (‘serialization.encoding’=’GBK’)如果把配置属性
hive.lazysimple.extended_boolean_literal设置为true(Hive 0.14.0 以后版本),LazySimpleSerDe 可以把 ‘T’, ‘t’, ‘F’, ‘f’, ‘1’, and ‘0’ 视为合法的布尔字面量。而该配置默认是 false 的,因此它只会把 ‘True’ 和 ‘False’ 视为合法的布尔字面量。 -
Thrift SerDe 读写 Thrift 序列化对象,可以使用这种 Hive SerDe 类型。需要确定的是,对于 Thrift 对象,类文件必须先被加载。
其他的SerDe
- JsonSerDe 可以读取JSON格式文件( 0.12.0)
- Avro SerDe 可以用来读取Avro(STORED AS AVRO,0.14.0 版本中被添加)
- ORC SerDe 可以读取ORC 文件(0.11.0)
- Parquet SerDe 可以读取Parquet 文件(0.11.0)
- ORC SerDe 可以读取ORC 文件(0.13.0)
- CSV SerDe 可以读取CSV 文件(0.14.0)
自定义SerDe
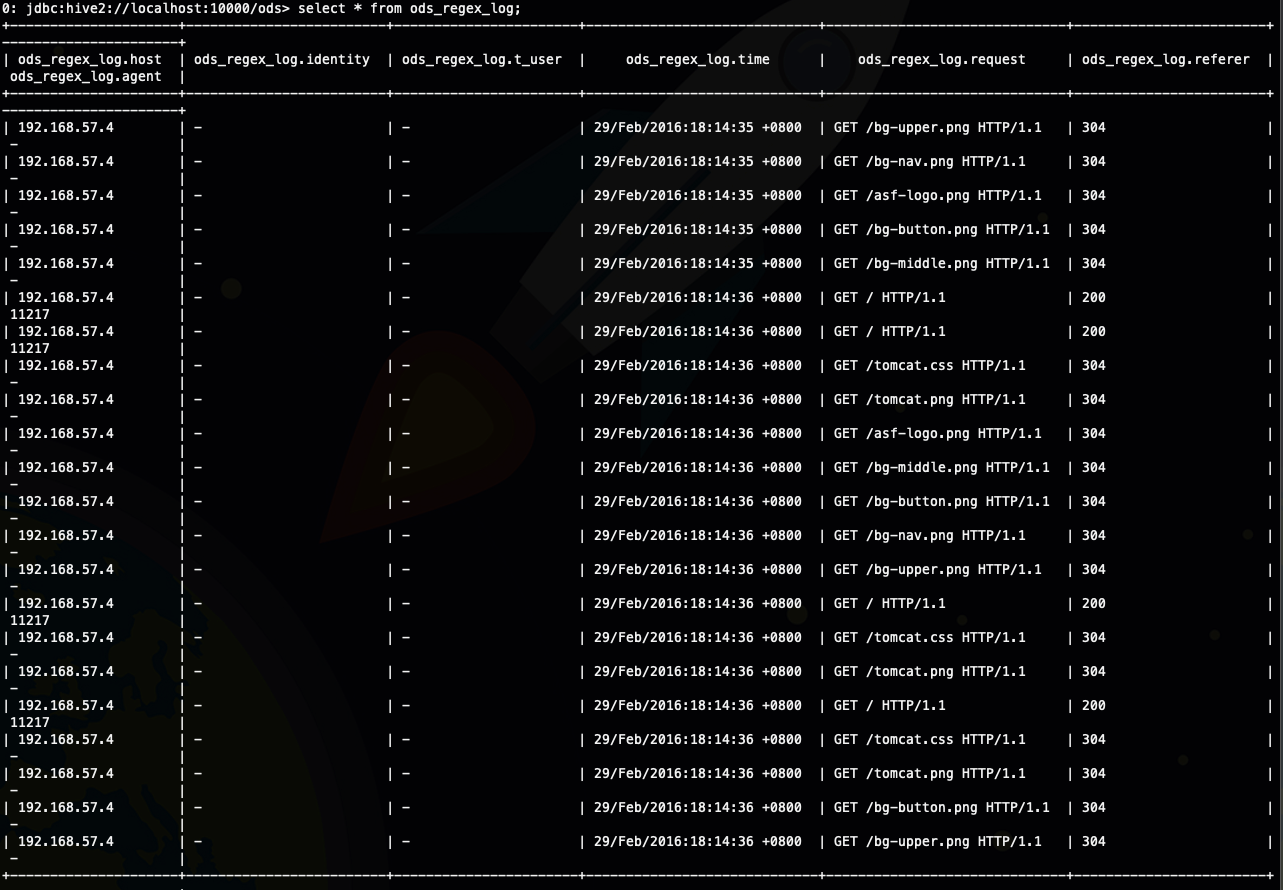
其实很多时候我们只想写自己的Deserializer而不是SerDe,这是因为我们只是要读取我们自己特定格式的数据,而不是写这样格式的数据,RegexDeserializer 就是这样的一个Deserializer,没有Serializer, RegexDeserializer可以根据参数配置的regex规则来反序列化数据也就是读取数据
RegexDeserializer
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
建表语句
CREATE TABLE ods_regex_log (
host STRING,
identity STRING,
t_user STRING,
`time` STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE
;
load data local inpath '/Users/liuwenqiang/workspace/hive/regexseserializer.txt' overwrite into table ods_regex_log;
自定义实现
前面我们也介绍了很多的Serde ,所以我们自定实现的最好方法就是模拟,也就是说照着别人的写,这里我们可以把hive 的源码clone 下来,然后去看别人是在怎么写的,hive 的Serde 有一个单独的模块,如下
前面我们也说过了org.apache.hadoop.hive.serde 已经被淘汰了,现在主要使用 org.apache.hadoop.hive.serde2 ,现在serde下面只有一个常量类了
接下来我们就看一下JsonSerDe 的实现,定义了一个类, 继承抽象类 AbstractSerDe
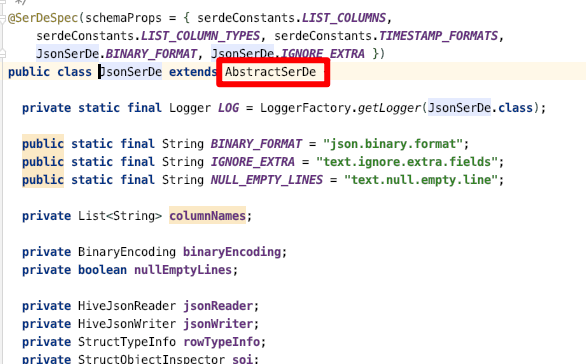
既然如此我们就看一下AbstractSerDe 抽象类,然后看一下类的注释
public abstract class AbstractSerDe implements Deserializer, Serializer {
protected String configErrors;
/**
* Initialize the SerDe. By default, this will use one set of properties, either the
* table properties or the partition properties. If a SerDe needs access to both sets,
* it should override this method.
* 初始化SerDe,默认情况下,这将使用一组属性,或者表属性或分区属性。如果SerDe需要访问这两个集合,它应该重写此方法。
* Eventually, once all SerDes have implemented this method, we should convert it to an abstract method.
* 上面这句话,你可以不用理解,是面向对象里面的一个知识
*/
public void initialize(Configuration configuration, Properties tableProperties,roperties partitionProperties) throws SerDeException {
initialize(configuration,
SerDeUtils.createOverlayedProperties(tableProperties, partitionProperties));
}
/**
* Initialize the HiveSerializer.
*
* @param conf
* System properties. Can be null in compile time
* @param tbl
* table properties
* @throws SerDeException
*/
@Deprecated
public abstract void initialize(@Nullable Configuration conf, Properties tbl)
throws SerDeException;
/**
* Returns the Writable class that would be returned by the serialize method.
* This is used to initialize SequenceFile header.
*/
public abstract Class<? extends Writable> getSerializedClass();
/**
* Serialize an object by navigating inside the Object with the
* ObjectInspector. In most cases, the return value of this function will be
* constant since the function will reuse the Writable object. If the client
* wants to keep a copy of the Writable, the client needs to clone the
* returned value.
*/
public abstract Writable serialize(Object obj, ObjectInspector objInspector)
throws SerDeException;
/**
* Returns statistics collected when serializing.
*
* @return A SerDeStats object or {@code null} if stats are not supported by
* this SerDe.
*/
public SerDeStats getSerDeStats() {
return null;
}
/**
* Deserialize an object out of a Writable blob. In most cases, the return
* value of this function will be constant since the function will reuse the
* returned object. If the client wants to keep a copy of the object, the
* client needs to clone the returned value by calling
* ObjectInspectorUtils.getStandardObject().
*
* @param blob
* The Writable object containing a serialized object
* @return A Java object representing the contents in the blob.
*/
public abstract Object deserialize(Writable blob) throws SerDeException;
/**
* Get the object inspector that can be used to navigate through the internal
* structure of the Object returned from deserialize(...).
*/
public abstract ObjectInspector getObjectInspector() throws SerDeException;
/**
* Get the error messages during the Serde configuration
*
* @return The error messages in the configuration which are empty if no error occurred
*/
public String getConfigurationErrors() {
return configErrors == null ? "" : configErrors;
}
/**
* @return Whether the SerDe that can store schema both inside and outside of metastore
* does, in fact, store it inside metastore, based on table parameters.
*/
public boolean shouldStoreFieldsInMetastore(Map<String, String> tableParams) {
return false; // The default, unless SerDe overrides it.
}
}
看起来我们需要实现initialize,serialize,deserialize 和getObjectInspector 四个方法,前面我们看到hive 的serde 是在hive-serde,模块里的,所以你要是想实现自定义的serde,就需要引入这个依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-serde</artifactId>
<version>3.1.0</version>
</dependency>
下面我们写一个简单的Serde来解析特定的数据格式
id=1,name="jack",age=20
id=2,name="john",age=30
下面就是代码实现,我们还是是现在我们以前写UDF 的那个工程里
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.serde.serdeConstants;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.PrimitiveTypeInfo;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.annotation.Nullable;
import java.util.*;
/**
* @description: 自定义序列化
* 继承自AbstractSerDe,主要实现下面的initialize,serialize,deserialize
*/
public class KingcallSerde extends AbstractSerDe {
private static final Logger logger = LoggerFactory.getLogger(KingcallSerde.class);
// 用于存储字段名
private List<String> columnNames;
// 用于存储字段类型
private List<TypeInfo> columnTypes;
private ObjectInspector objectInspector;
// 初始化,在serialize和deserialize前都会执行initialize
@Override
public void initialize(Configuration configuration, Properties tableProperties, Properties partitionProperties) throws SerDeException {
String columnNameString = tableProperties.getProperty(serdeConstants.LIST_COLUMNS);
String columnTypeString = tableProperties.getProperty(serdeConstants.LIST_COLUMN_TYPES);
columnNames = Arrays.asList(columnNameString.split(","));
columnTypes = TypeInfoUtils.getTypeInfosFromTypeString(columnTypeString);
List<ObjectInspector> columnOIs = new ArrayList<>();
ObjectInspector oi;
for(int i = 0; i < columnNames.size(); i++) {
oi = TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(columnTypes.get(i));
columnOIs.add(oi);
}
objectInspector = ObjectInspectorFactory.getStandardStructObjectInspector(columnNames, columnOIs);
}
// 重载的方法,直接调用上面的实现
@Override
public void initialize(@Nullable Configuration configuration, Properties properties) throws SerDeException {
this.initialize(configuration, properties, null);
}
@Override
public Class<? extends Writable> getSerializedClass() {
return null;
}
// o是导入的单行数据的数组,objInspector包含了导入的字段信息,这边直接就按顺序
// 将数据处理成key=value,key1=value1的格式的字符串,并返回Writable格式。
@Override
public Writable serialize(Object o, ObjectInspector objInspector) throws SerDeException {
Object[] arr = (Object[]) o;
List<String> tt = new ArrayList<>();
for (int i = 0; i < arr.length; i++) {
tt.add(String.format("%s=%s", columnNames.get(i), arr[i].toString()));
}
return new Text(StringUtils.join(tt, ","));
}
@Override
public SerDeStats getSerDeStats() {
return null;
}
// writable转为字符串,其中包含了一行的信息,如key=value,key1=value1
// 分割后存到map中,然后按照字段的顺序,放到object中
// 中间还需要做类型处理,这边只简单的做了string和int
@Override
public Object deserialize(Writable writable) throws SerDeException {
Text text = (Text) writable;
Map<String, String> map = new HashMap<>();
String[] cols = text.toString().split(",");
for(String col: cols) {
String[] item = col.split("=");
map.put(item[0], item[1]);
}
ArrayList<Object> row = new ArrayList<>();
Object obj = null;
for(int i = 0; i < columnNames.size(); i++){
TypeInfo typeInfo = columnTypes.get(i);
PrimitiveTypeInfo pTypeInfo = (PrimitiveTypeInfo)typeInfo;
if(typeInfo.getCategory() == ObjectInspector.Category.PRIMITIVE) {
if(pTypeInfo.getPrimitiveCategory() == PrimitiveObjectInspector.PrimitiveCategory.STRING){
obj = StringUtils.defaultString(map.get(columnNames.get(i)));
}
if(pTypeInfo.getPrimitiveCategory() == PrimitiveObjectInspector.PrimitiveCategory.INT) {
obj = Integer.parseInt(map.get(columnNames.get(i)));
}
}
row.add(obj);
}
return row;
}
@Override
public ObjectInspector getObjectInspector() throws SerDeException {
return objectInspector;
}
@Override
public String getConfigurationErrors() {
return super.getConfigurationErrors();
}
@Override
public boolean shouldStoreFieldsInMetastore(Map<String, String> tableParams) {
return super.shouldStoreFieldsInMetastore(tableParams);
}
}
使用自定义 Serde 类型
-
add jar /Users/liuwenqiang/workspace/code/idea/HiveUDF/target/original-HiveUDF-0.0.4.jar; -
创建表格时属性 row fromat 指定自定义的 SerDe 类。
CREATE EXTERNAL TABLE `ods_test_serde`( `id` int, `name` string, `age` int ) ROW FORMAT SERDE 'com.kingcall.bigdata.HiveSerde.KingcallSerde' STORED AS TEXTFILE; -
加载数据或者插入数据
LOAD DATA LOCAL INPATH '/Users/liuwenqiang/workspace/hive/serde.txt' OVERWRITE INTO TABLE ods_test_serde; -
查看数据
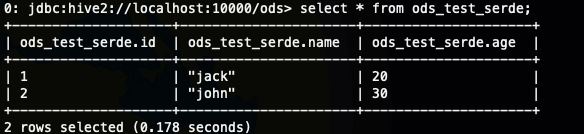
-
插入数据并查看
insert into table ods_test_serde values(3, "test", 10);
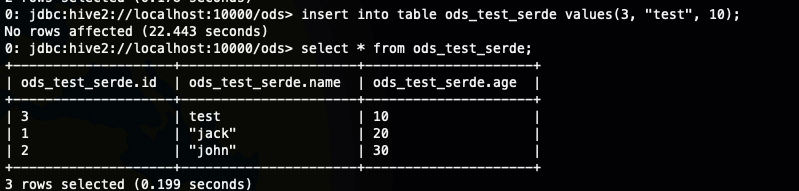
- 查看HDFS 上的数据
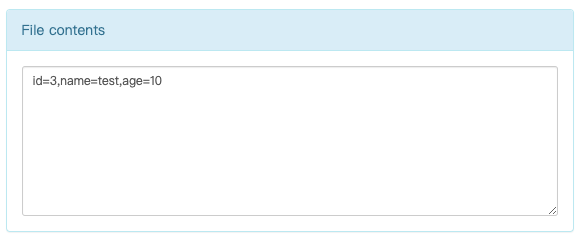
新版本的Hadoop 的HDFS 的web 页面上可以直接查看文件的部分数据,不用再去拉倒本地来看或者是使用hdfs 命令在命令行里看
ObjectInspector
Hive 使用 ObjectInspector 对象分析行对象的内部结构以及列的结构。
具体来说,ObjectInspector 给访问复杂的对象提供了一种统一的方式。对象可能以多种格式存储在内存中:
- Java 类实例,Thrift 或者 原生 Java
- 标准 Java 对象,比如 Map 字段,我们使用 java.util.List 表示 Struct 和 Array ,以及使用 java.util.Map。
- 惰性初始化对象。
此外,可以通过 (ObjectInspector, java 对象) 这种结构表示一个复杂的对象。它为我们提供了访问对象内部字段的方法,而不涉及对象结构相关的信息。出了序列化的目的,Hive 建议为自定义 SerDes 创建自定义的 objectinspector,SerDe 有两个构造器,一个无参构造器,一个常规构造器。
总结
- Hive 本身不存储数据,它与数据的交互都是通过SerDe来完成的,所以我们可以将SerDe看成是Hive 和HDFS 解耦的一个设计
- Hive 本身提供了非常多的SerDe,可以很好的满足我们的日常开发,当不能满足的时候我们也可以自己开发所需的SerDe