最近读完了 《Hive编程指南》。回过头来对书中的知识点做一总结。
Hive 中的数据压缩 体现在 2个方面,
一个是 job 最终执行结果的数据压缩,另一个方面是计算中间结果的数据压缩。
参考文章:
hive 的几种存储格式
https://blog.csdn.net/jinfeiteng2008/article/details/56665804
关于hive数据压缩
https://www.cnblogs.com/guotianqi/p/8065588.html
hive的压缩设置
https://blog.csdn.net/djd1234567/article/details/51581354
Hive编程(十一)【其他文件格式和压缩方法】
https://blog.csdn.net/WuLex/article/details/78686552
Hadoop(九)Hadoop IO之Compression和Codecs
https://www.cnblogs.com/zhangyinhua/p/7696389.html
接下来,我们对这两个方面进行一 一总结。
大纲
Hive 中几种数据格式
Hive 中的编解码器
Hive 中的几种压缩方式 以及各自的特点
SequenceFile 的分块存储
Hive 中间结果的数据压缩
Hive 最终结果的数据压缩
Hive 压缩实践
Hive HAR 文件归档
Hive 中几种数据格式
Hive文件存储格式主要有以下几种:
TEXTFILE :
textfile为默认格式
存储方式:行存储
磁盘开销大 数据解析开销大
压缩的text文件 hive无法进行合并和拆分
SEQUENCEFILE:
二进制文件,以<key,value>的形式序列化到文件中
存储方式:行存储
可分割 压缩
一般选择block压缩
优势是文件和Hadoop api中的mapfile是相互兼容的。
RCFILE:
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
读记录尽量涉及到的block最少
读取需要的列只需要读取每个row group 的头部定义。
读取全量数据的操作 性能可能比sequencefile没有明显的优势
ORC :
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
效率比rcfile高,是rcfile的改良版本
Apache ORC :
ORC(OptimizedRC File)存储源自于RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎,
对schema演化(修改schema需要重新生成数据)支持较差,而ORC是对RC改进,但它仍对schema演化支持较差,
主要是在压缩编码,查询性能方面做了优化。RC/ORC最初是在Hive中得到使用,最后发展势头不错,独立成一个单独的项目。
Hive 1.x版本对事务和update操作的支持,便是基于ORC实现的(其他存储格式暂不支持)。
ORC发展到今天,已经具备一些非常高级的feature,比如支持update操作,支持ACID,支持struct,array复杂类型。
你可以使用复杂类型构建一个类似于parquet的嵌套式数据架构,但当层数非常多时,
写起来非常麻烦和复杂,而parquet提供的schema表达方式更容易表示出多级嵌套的数据类型。
PARQUET:
Apache Parquet
源自于google Dremel系统(可下载论文参阅),Parquet相当于Google Dremel中的数据存储引擎,
而Apache顶级开源项目Drill正是Dremel的开源实现。
Apache Parquet 最初的设计动机是存储嵌套式数据,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,
以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据,这也是Parquet相比于ORC的优势,
它能够透明地将Protobuf和thrift类型的数据进行列式存储,在Protobuf和thrift被广泛使用的今天,与parquet进行集成,
是一件非容易和自然的事情。 除了上述优势外,相比于ORC, Parquet没有太多其他可圈可点的地方,
比如它不支持update操作(数据写成后不可修改),不支持ACID等。
自定义格式 :
用户可以通过实现inputformat和 outputformat来自定义输入输出格式。
================================================================
Hive 中的编解码器
Hive 中有一下编解码器,编解码器需要在 Hadoop 配置文件中进行设置,
此处如果执行指令 set io.compression.codecs;
提示没有设置的话,需要在 Hadoop 中进行设置。
此处我们设置在 /usr/local/hadoop/etc/hadoop/mapred-site.xml 文件中:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.DeflateCodec,org.apache.hadoop.io.compress.SnappyCodec,org.apache.hadoop.io.compress.Lz4Codec
</value>
</property>
正常执行 set io.compression.codecs 提示的内容:
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--+
| set |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--+
| io.compression.codecs=org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.DeflateCodec,org.apache.hadoop.io.compress.SnappyCodec,org.apache.hadoop.io.compress.Lz4Codec |
| |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--+
可以看到提到的主要编解码器 如下:
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.DeflateCodec,
org.apache.hadoop.io.compress.SnappyCodec,
org.apache.hadoop.io.compress.Lz4Codec
==============================================================
Hive 中的几种压缩方式 以及各自的特点
Hive 中主要存在以下的压缩方式
GZip, BZip2 压缩方式, (全版本都支持)
Snappy 最近新添加的压缩方式
LZO 需要额外的安装包
下面对这几种方式做对比,主要从以下三个方面
1.编解码器
2.压缩/解压速度,压缩比
3.是否支持分割
编解码器

压缩/解压速度,压缩比

压缩格式 压缩率 压缩速度
gzip 很高 比较快
lzo 比较高 很快
snappy 比较高 很快
bzip2 最高 慢
是否支持分割
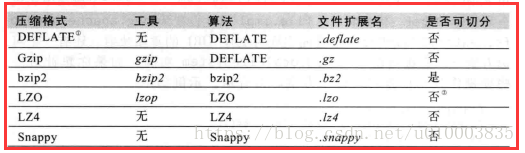
我们对分割做一个解释:
压缩格式文件是否是可分割的 也比较重要:
MapReduce 需要将非常大的输入文件分割成多个划分(通常一个文件块对应一个跨分没也就是64MB的倍数),
其中每个划分会被分发到一个单独的map进程中。
只有当Hadoop 知道文件中记录的边界才可以进行这样的分割。
GZip 跟 Snappy 将这些边界信息掩盖掉了。
BZip2和LZO提供了块(BLOCK)级别的压缩,也就是每个块都含有完整的记录信息,因此Hadoop 可以在块边界级别对这些文件进行划分。
需要注意一点:
虽然GZip 与 Snappy 文件不可分,但也有替代的方案。
当用户创建文件的时候,可以将文件分割成期望的文件大小,通常输出文件的个数等于Reducer 的个数。
用户使用了N个Reducer,通常就会得到N个输出文件。
==========================================================
SequenceFile 的分块存储
压缩文件可以节约空间。
Hadoop 存储裸压缩文件的一个缺点是,通常这些文件是不可分割的。
可分割的文件可以划分为多个部分,由多个mapper 并行进行处理。大多数压缩文件是不可分割的,也就是说只能从头读到尾。
Hadoop sequencefile 存储格式可以将一个文件划分为多个块,然后采用一种可分割的方式对块进行压缩。
SEQUENCE FILE 提供了3种级别的压缩方式 : NONE, RECORD, BLOCK, 默认是 RECORD 级别。
通常来说 BLOCK (也就是块级别) 压缩性能最好, 并且是可以分割的。
可以通过如下属性进行设置。也可以写在配置文件中。配置文件可以在 Hadoop 的 mapred-site.xml 中定义,
也可以在 HIve 的 hive-site.xml 中进行定义。
属性为:
mapred.output.compression.type
设置 属性 :
set mapred.output.compression.type=BLOCK;
==================================================
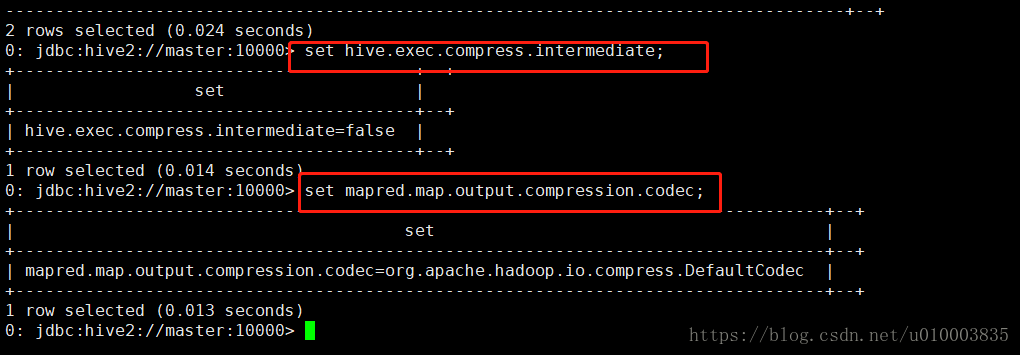
Hive 中间结果的数据压缩
影响Hive 中间结果压缩的主要是以下两个属性。
hive.exec.compress.intermediate //控制是否开启中间结果压缩
mapred.map.output.compression.codec //控制中间结果压缩使用的编解码器
可以通过set 指令进行查看:
==================================================
Hive 最终结果的数据压缩
Hive 最终结果也主要受以下两个属性影响。
hive.exec.compress.output //hive输出结果压缩
mapred.output.compression.codec //hive输出结果的压缩编解码器
//可选的 可以设置针对于SEQUENCEFILE 的块压缩:
set mapred.output.compression.type=BLOCK;
同样可以通过set 指令进行查看:

========================================================================
Hive 压缩实践
我们构建了clickcube_mid 分区表,
分区数量:
0: jdbc:hive2://master:10000> show partitions clickcube_mid;
+-----------------+--+
| partition |
+-----------------+--+
| day=2018-05-01 |
| day=2018-05-02 |
| day=2018-05-03 |
| day=2018-05-04 |
| day=2018-05-05 |
| day=2018-05-06 |
| day=2018-05-07 |
| day=2018-05-08 |
| day=2018-05-09 |
| day=2018-05-10 |
| day=2018-05-11 |
| day=2018-05-12 |
| day=2018-05-13 |
| day=2018-05-14 |
| day=2018-05-15 |
| day=2018-05-16 |
| day=2018-05-17 |
| day=2018-05-18 |
| day=2018-05-19 |
| day=2018-05-20 |
| day=2018-05-21 |
| day=2018-05-22 |
| day=2018-05-23 |
| day=2018-05-24 |
| day=2018-05-25 |
| day=2018-05-26 |
| day=2018-05-27 |
| day=2018-05-28 |
| day=2018-05-29 |
| day=2018-05-30 |
| day=2018-05-31 |
| day=2018-06-01 |
| day=2018-06-02 |
| day=2018-06-03 |
| day=2018-06-04 |
| day=2018-06-05 |
| day=2018-06-06 |
| day=2018-06-07 |
| day=2018-06-08 |
| day=2018-06-09 |
| day=2018-06-10 |
| day=2018-06-11 |
| day=2018-06-12 |
| day=2018-06-13 |
| day=2018-06-14 |
| day=2018-06-15 |
| day=2018-06-16 |
| day=2018-06-17 |
| day=2018-06-18 |
| day=2018-06-19 |
| day=2018-06-20 |
| day=2018-06-21 |
| day=2018-06-22 |
| day=2018-06-23 |
| day=2018-06-24 |
| day=2018-06-25 |
| day=2018-06-26 |
| day=2018-06-27 |
| day=2018-06-28 |
| day=2018-06-29 |
| day=2018-06-30 |
| day=2018-07-03 |
+-----------------+--+
62 rows selected (0.344 seconds)
查看记录总数:
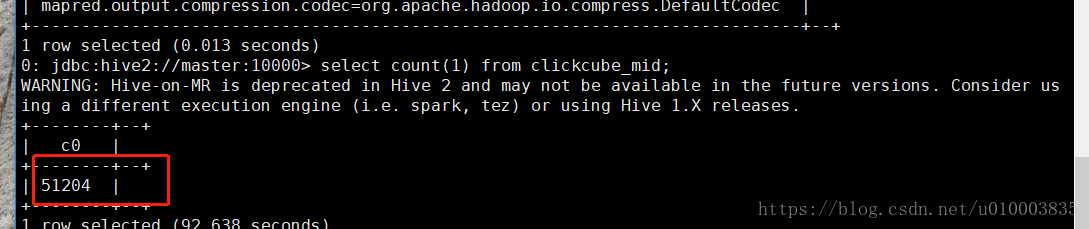
可以看到记录总数 51204
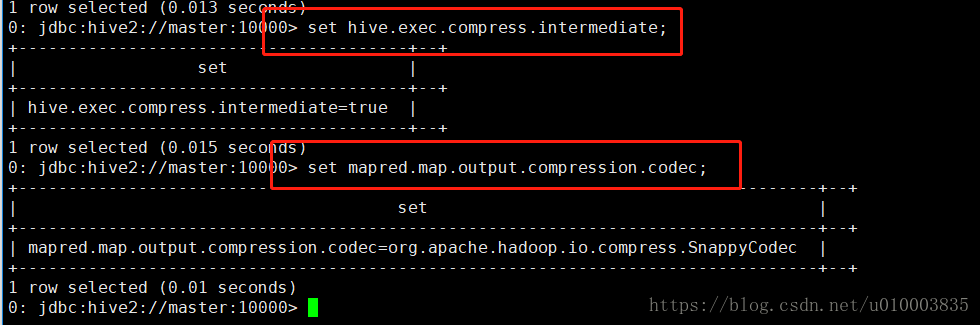
首先对中间结果压缩进行设置:
set hive.exec.compress.intermediate=true;
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
编写查询SQL
select day, sum(campimp), sum(campclick)
from clickcube_mid
group by day
order by day;
可以看到可以正常执行:
+-------------+--------+--------+--+
| day | _c1 | _c2 |
+-------------+--------+--------+--+
| 2018-05-02 | 4 | 2 |
| 2018-05-03 | 12 | 11 |
| 2018-05-10 | 17 | 4 |
| 2018-05-11 | 11 | 7 |
| 2018-05-12 | 0 | 0 |
| 2018-05-14 | 0 | 0 |
| 2018-05-16 | 36 | 20 |
| 2018-05-17 | 12 | 15 |
| 2018-05-18 | 61 | 27 |
| 2018-05-19 | 1 | 0 |
| 2018-05-20 | 5 | 6 |
| 2018-05-21 | 0 | 0 |
| 2018-05-23 | 105 | 79 |
| 2018-05-24 | 230 | 223 |
| 2018-05-25 | 147 | 124 |
| 2018-05-26 | 1 | 0 |
| 2018-05-27 | 2 | 1 |
| 2018-05-28 | 1290 | 1043 |
| 2018-05-29 | 731 | 756 |
| 2018-05-30 | 8828 | 8223 |
| 2018-05-31 | 9402 | 8365 |
| 2018-06-01 | 1293 | 1065 |
| 2018-06-02 | 4 | 1 |
| 2018-06-03 | 1 | 1 |
| 2018-06-04 | 16 | 25 |
| 2018-06-05 | 360 | 299 |
| 2018-06-06 | 1174 | 1125 |
| 2018-06-07 | 5111 | 6690 |
| 2018-06-08 | 13576 | 11122 |
| 2018-06-09 | 58 | 54 |
| 2018-06-10 | 15 | 12 |
| 2018-06-11 | 4409 | 3240 |
| 2018-06-12 | 1171 | 801 |
| 2018-06-13 | 3443 | 2058 |
| 2018-06-14 | 14067 | 12926 |
| 2018-06-15 | 1637 | 1629 |
| 2018-06-16 | 47 | 41 |
| 2018-06-17 | 15 | 15 |
| 2018-06-18 | 18 | 15 |
| 2018-06-19 | 8186 | 5990 |
| 2018-06-20 | 693 | 623 |
| 2018-06-21 | 553 | 517 |
| 2018-06-22 | 9694 | 7657 |
| 2018-06-23 | 24 | 13 |
| 2018-06-24 | 10 | 5 |
| 2018-06-25 | 210 | 5050 |
| 2018-06-26 | 48 | 2191 |
| 2018-06-27 | 1 | 1 |
| 2018-06-28 | 8 | 2 |
| 2018-06-29 | 6 | 3 |
| 2018-06-30 | 1 | 0 |
| 2018-07-03 | 223 | 5603 |
+-------------+--------+--------+--+
52 rows selected (160.106 seconds)
然后对最终结果压缩进行设置:
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
//可选的 可以设置针对于SEQUENCEFILE 的块压缩:
set mapred.output.compression.type=BLOCK;

第一个测试:
先测试通过查询结果创建表:
create table result_b as select day, sum(campimp), sum(campclick) from clickcube_mid group by day;

最终从 hdfs 上看下结果:
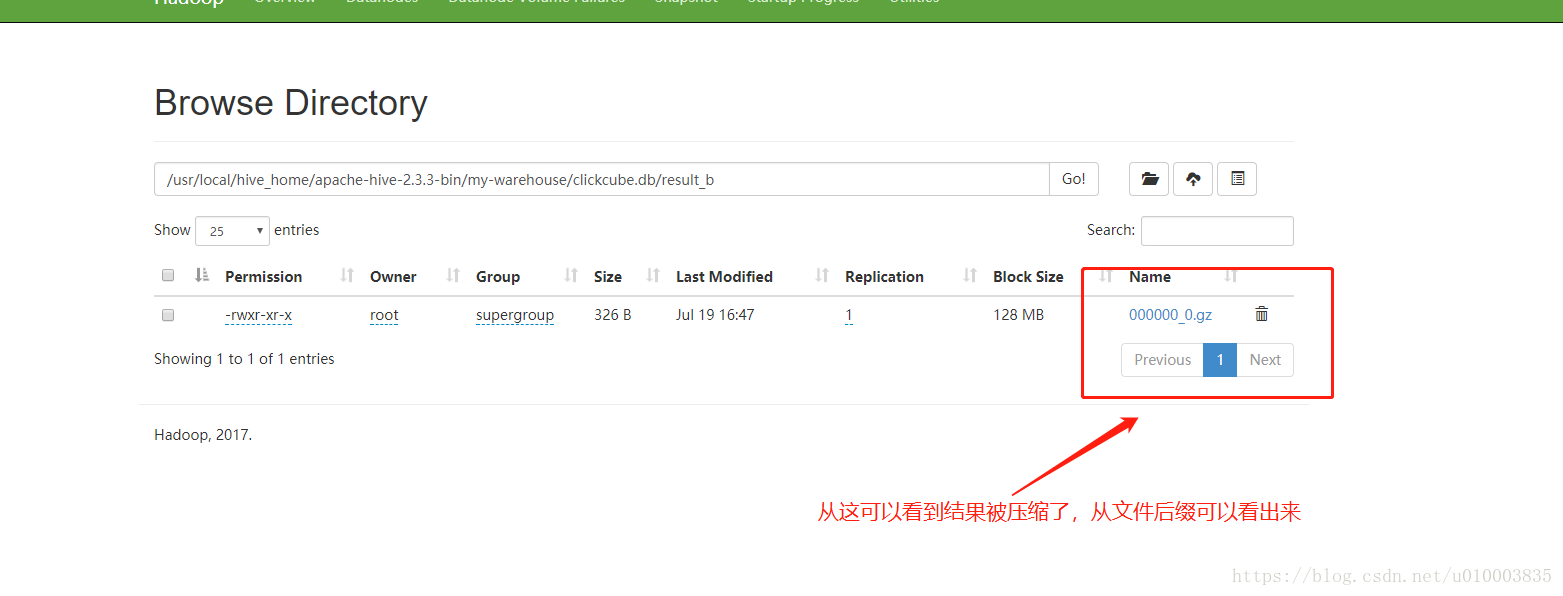
看下数据能否正常读取出来:
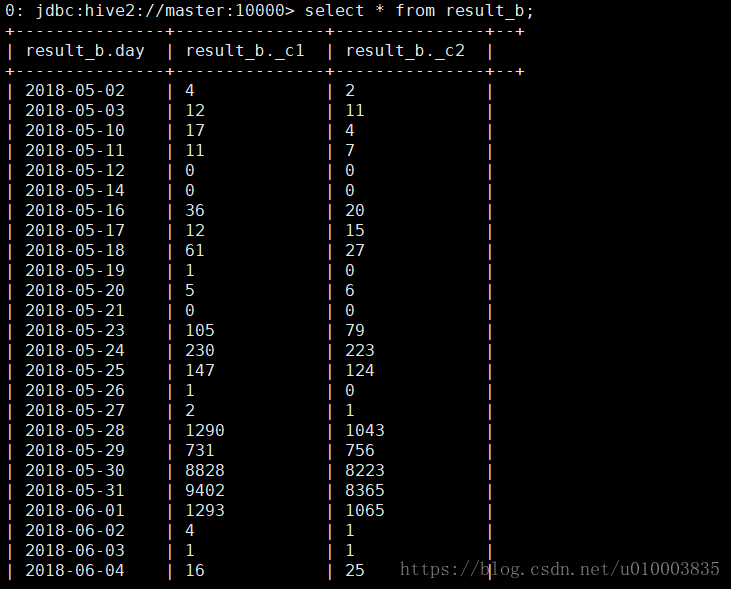
第二个测试:
创建表,并设置存储为 sequencefile .
create table result_a (day string, imp int, click int) stored as sequencefile;
插入结果数据:
insert into result_a select day, sum(campimp), sum(campclick) from clickcube_mid group by day;
最终结果:
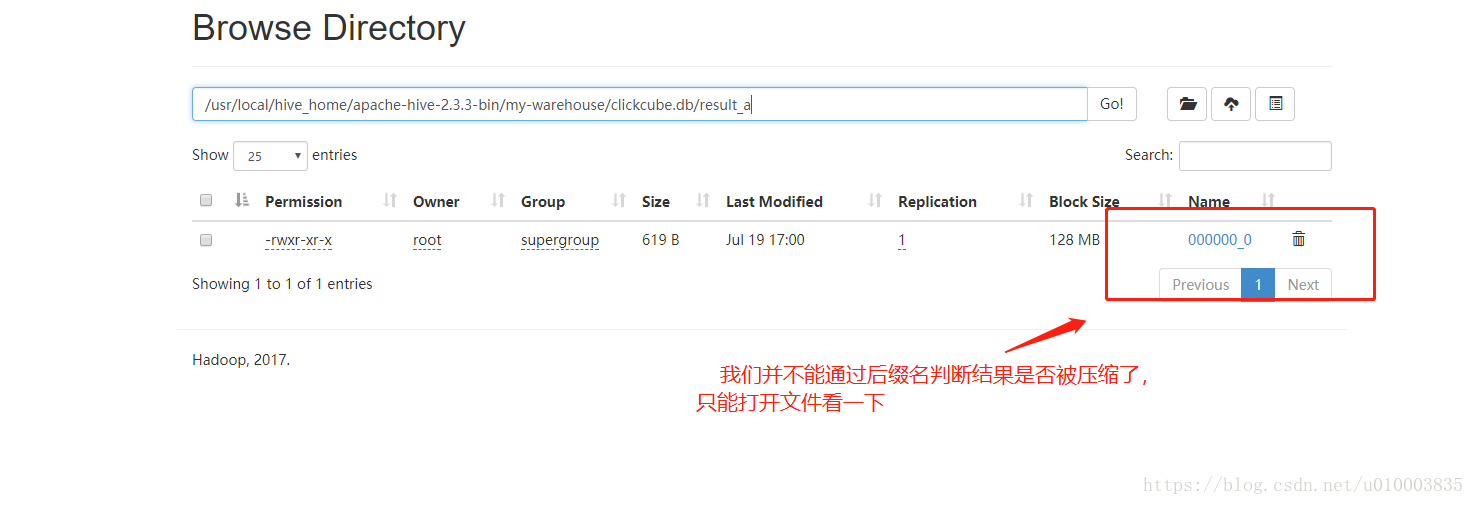
查看下文件:
文本部分内容:
SEQ"org.apache.hadoop.io.BytesWritableorg.apache.hadoop.io.Text'org.apache.hadoop.io.compress.GzipCodec����b��
�(���������b��
�(�4�ca!�3�4�c`^��"_�9�
��
A����A���Cf �`�;���>Om��9��R�4�h�USm�\1�/0��V��H@ ��XM��Wi����|x^&z��o1l�g�5�~�#T�{����� ���`�i`�A���>�E(�!�Ї� 1PK�GC�+��_�p�%0[C9t������M�jxY�\�C%q'��:����K�!��ջ¿�x��b5�j�V���l�7�ο�pe�,���B��ׁ+o��I���T���I�/|7Q�溬�(�7˖m��dE�(��.�����m�����ZZ�"�c���l��ⓕ���oFeV�ހgJ �::Q�q_\��O͐�'�������h����%+B��Ǿ/�S2O��lE60��EC��Y��8� ��, Đ�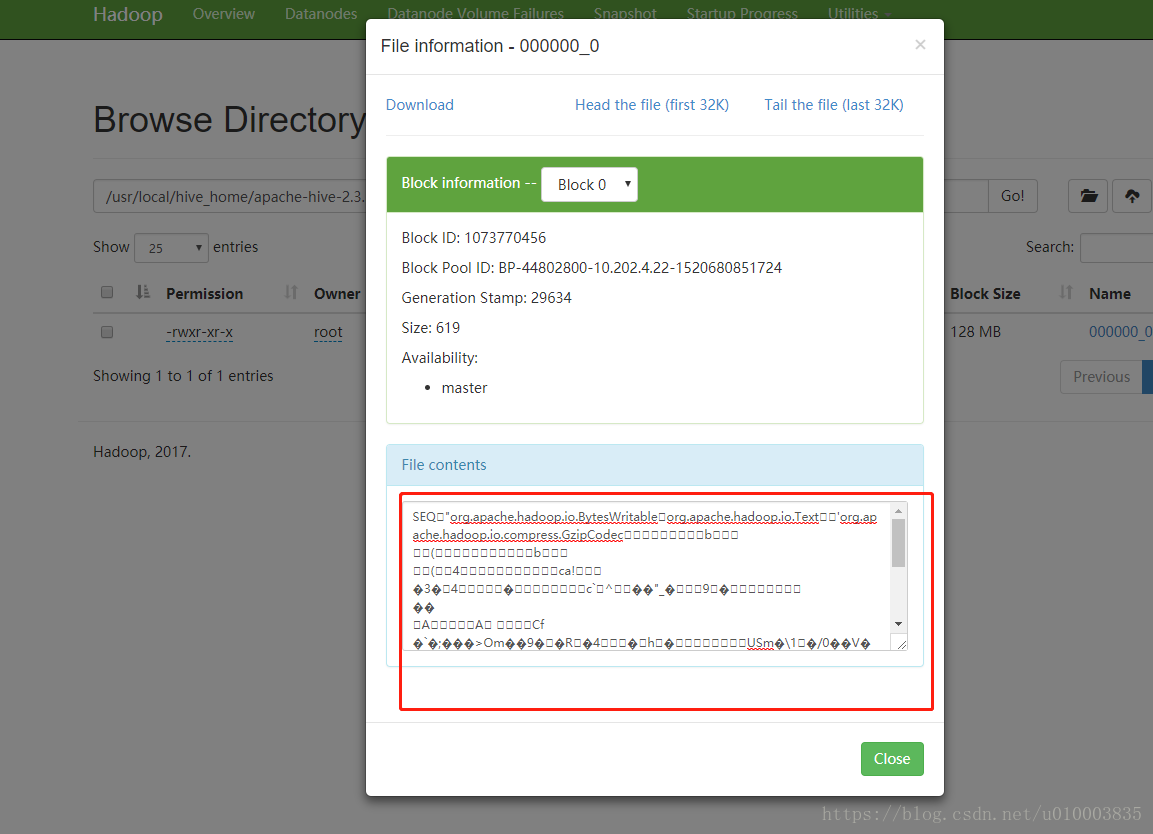
第三个测试:
创建表,并设置存储为 textfile
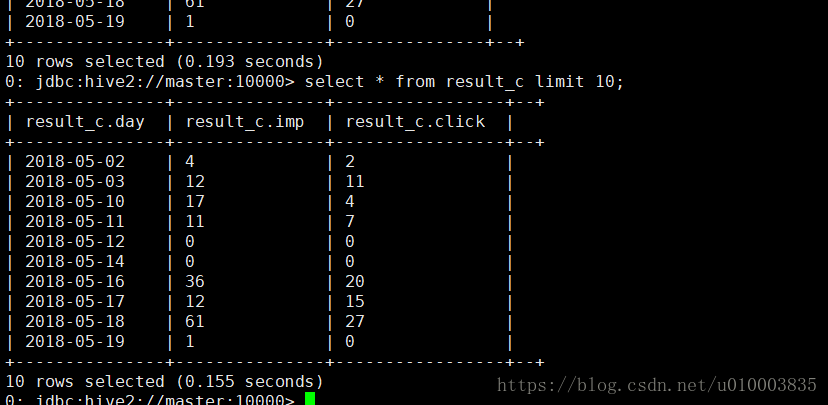
create table result_c (day string, imp int, click int) stored as textfile;
插入结果数据:
insert into result_c select day, sum(campimp), sum(campclick) from clickcube_mid group by day;
查询数据:
文件查看
我们可以通过 hdfs dfs -text 查看下压缩文件
hdfs dfs -text /usr/local/hive_home/apache-hive-2.3.3-bin/my-warehouse/clickcube.db/result_b/000000_0.gz
[root@master ~]# hdfs dfs -text /usr/local/hive_home/apache-hive-2.3.3-bin/my-warehouse/clickcube.db/result_b/000000_0.gz
2018-05-0242
2018-05-031211
2018-05-10174
2018-05-11117
2018-05-1200
2018-05-1400
2018-05-163620
2018-05-171215
2018-05-186127
2018-05-1910
2018-05-2056
2018-05-2100
2018-05-2310579
2018-05-24230223
2018-05-25147124
2018-05-2610
2018-05-2721
2018-05-2812901043
2018-05-29731756
2018-05-3088288223
2018-05-3194028365
2018-06-0112931065
2018-06-0241
2018-06-0311
2018-06-041625
2018-06-05360299
2018-06-0611741125
2018-06-0751116690
2018-06-081357611122
2018-06-095854
2018-06-101512
2018-06-1144093240
2018-06-121171801
2018-06-1334432058
2018-06-141406712926
2018-06-1516371629
2018-06-164741
2018-06-171515
2018-06-181815
2018-06-1981865990
2018-06-20693623
2018-06-21553517
2018-06-2296947657
2018-06-232413
2018-06-24105
2018-06-252105050
2018-06-26482191
2018-06-2711
2018-06-2882
2018-06-2963
2018-06-3010
2018-07-032235603
额外提示:
create table result_c stored as sequencefile as select day, sum(campimp), sum(campclick) from clickcube_mid group by day;
如果我们出现如下的报错:可以参看下面解决问题的方法:
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
这个问题困扰了我半天 !!!
我最终从 hiveserver 的 运行日志 中 找到了问题的原因: (日志是个好东西 !)
Error: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row (tag=0) {"key":{"_col0":"2018-05-03"},"value":{"_col0":12,"_col1":11}}
at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.reduce(ExecReducer.java:257)
at org.apache.hadoop.mapred.ReduceTask.runOldReducer(ReduceTask.java:444)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:392)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:177)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1886)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:171)
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row (tag=0) {"key":{"_col0":"2018-05-03"},"value":{"_col0":12,"_col1":11}}
at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.reduce(ExecReducer.java:245)
... 7 more
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.createBucketFiles(FileSinkOperator.java:574)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.process(FileSinkOperator.java:674)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:897)
at org.apache.hadoop.hive.ql.exec.SelectOperator.process(SelectOperator.java:95)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:897)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.forward(GroupByOperator.java:1047)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.processAggr(GroupByOperator.java:847)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.processKey(GroupByOperator.java:721)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.process(GroupByOperator.java:787)
at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.reduce(ExecReducer.java:236)
... 7 more
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveRecordWriter(HiveFileFormatUtils.java:274)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.createBucketForFileIdx(FileSinkOperator.java:619)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.createBucketFiles(FileSinkOperator.java:563)
... 16 more
Caused by: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.io.SequenceFile$Writer.<init>(SequenceFile.java:1163)
at org.apache.hadoop.io.SequenceFile$RecordCompressWriter.<init>(SequenceFile.java:1452)
at org.apache.hadoop.io.SequenceFile.createWriter(SequenceFile.java:283)
at org.apache.hadoop.io.SequenceFile.createWriter(SequenceFile.java:538)
at org.apache.hadoop.hive.ql.exec.Utilities.createSequenceWriter(Utilities.java:1019)
at org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat.getHiveRecordWriter(HiveSequenceFileOutputFormat.java:64)
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getRecordWriter(HiveFileFormatUtils.java:286)
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveRecordWriter(HiveFileFormatUtils.java:271)
... 18 more
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 44.02 sec HDFS Read: 363804 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 44 seconds 20 msec
NoViableAltException(24@[])
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:1300)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:208)
at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:77)
at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:70)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:468)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1317)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1295)
at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:204)
at org.apache.hive.service.cli.operation.SQLOperation.runInternal(SQLOperation.java:290)
at org.apache.hive.service.cli.operation.Operation.run(Operation.java:320)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementInternal(HiveSessionImpl.java:530)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementAsync(HiveSessionImpl.java:517)
at sun.reflect.GeneratedMethodAccessor33.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:78)
at org.apache.hive.service.cli.session.HiveSessionProxy.access$000(HiveSessionProxy.java:36)
at org.apache.hive.service.cli.session.HiveSessionProxy$1.run(HiveSessionProxy.java:63)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1886)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:59)
at com.sun.proxy.$Proxy37.executeStatementAsync(Unknown Source)
at org.apache.hive.service.cli.CLIService.executeStatementAsync(CLIService.java:310)
at org.apache.hive.service.cli.thrift.ThriftCLIService.ExecuteStatement(ThriftCLIService.java:530)
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1437)
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1422)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:56)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
最致命的错误如下:
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveRecordWriter(HiveFileFormatUtils.java:274)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.createBucketForFileIdx(FileSinkOperator.java:619)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.createBucketFiles(FileSinkOperator.java:563)
... 16 more
Caused by: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.io.SequenceFile$Writer.<init>(SequenceFile.java:1163)
at org.apache.hadoop.io.SequenceFile$RecordCompressWriter.<init>(SequenceFile.java:1452)
at org.apache.hadoop.io.SequenceFile.createWriter(SequenceFile.java:283)
at org.apache.hadoop.io.SequenceFile.createWriter(SequenceFile.java:538)
at org.apache.hadoop.hive.ql.exec.Utilities.createSequenceWriter(Utilities.java:1019)
at org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat.getHiveRecordWriter(HiveSequenceFileOutputFormat.java:64)
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getRecordWriter(HiveFileFormatUtils.java:286)
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveRecordWriter(HiveFileFormatUtils.java:271)
... 18 more
可以看到出错的原因就是 native-hadoop lib 找不到
错误的解决方法有如下两种:
参考文章:
记录Hadoop native libraries无法load的问题
http://san-yun.iteye.com/blog/2043196
1. 把 hadoop.native.lib 设置为false
2. 从根本上解决 ,解决方法同以下问题,
Hadoop之—— WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform...
可以参看我的另一篇文章:
Hadoop _ 疑难杂症 解决1 - WARN util.NativeCodeLoader: Unable to load native-hadoop library for your plat
https://blog.csdn.net/u010003835/article/details/81127984
====================================================================
Hive HAR 文件归档
Hadoop 中有一种存储格式名为HAR, 也就是 Hadoop Archive (Hadoop 归档文件) 的缩写。
一个HAR文件就像在HDFS文件系统中的一个TAR 文件一样是一个单独的文件。不过,其内部可以存放多个文件与文件夹。
使用场景:
某些场景,较旧的文件夹 和 文件比较新的文件夹 被访问的概率要低很多。
如果摸个特定的分区下保存的文件有成千上万,那么就需要HDFS 的 NameNode 消耗非常大的代价来管理这些文件。
通过将分区下的文件归档成一个巨大的,但是同时可以被Hive 访问的文件,可以减轻 NameNode 的压力。
缺点:
1) HAR 文件查询效率不高
2) 同时,HAR 文件并非是压缩的,因此也不会节约存储空间。
归档主要与以下3个属性相关:
hive> set hive.archive.enabled=true;
hive> set hive.archive.har.parentdir.settable=true;
hive> set har.partfile.size=1099511627776;
hive.archive.enabled
用来控制归档是否可用,
hive.archive.har.parentdir.settable
通知Hive在创建归档时是否可以设置父目录,这个配置主要是因为在比较老的hadoop版本(2011之前),-p选项是不可用的,因此这个选项需要设置为false。
har.partfile.size
控制需要归档文件的大小,使用了这个参数后这个归档将会包含 size_of_partition/har.partfile.size(四舍五入)个文件,这个值越大以为值文件数越小,结果文件数越小以为值归档时的reduce数目越小,需要更多的归档时间。
使用示例:
创建一个表:
create table har_test(line string) partitioned by (folder string);
新增分区:
alter table har_test add partition(folder='docs');
导入数据:
导入 HIVE_HOME 中的文件放入到 har_test 表 的 docs 分区中。
先看下 HIVE_HOME 的定义:
set env:HIVE_HOME;

导入命令:
LOAD DATA LOCAL INPATH '${env:HIVE_HOME}/NOTICE' INTO TABLE har_test PARTITION (folder='docs');
LOAD DATA LOCAL INPATH '${env:HIVE_HOME}/RELEASE_NOTES.txt' INTO TABLE har_test PARTITION (folder='docs');

我们从HDFS 上看一下:

设置文件归档:
开启文件归档属性:(默认是不开启的)
set hive.archive.enabled=true;

执行归档指令:
alter table har_test archive partition(folder='docs');

从HDFS 上查看一下:

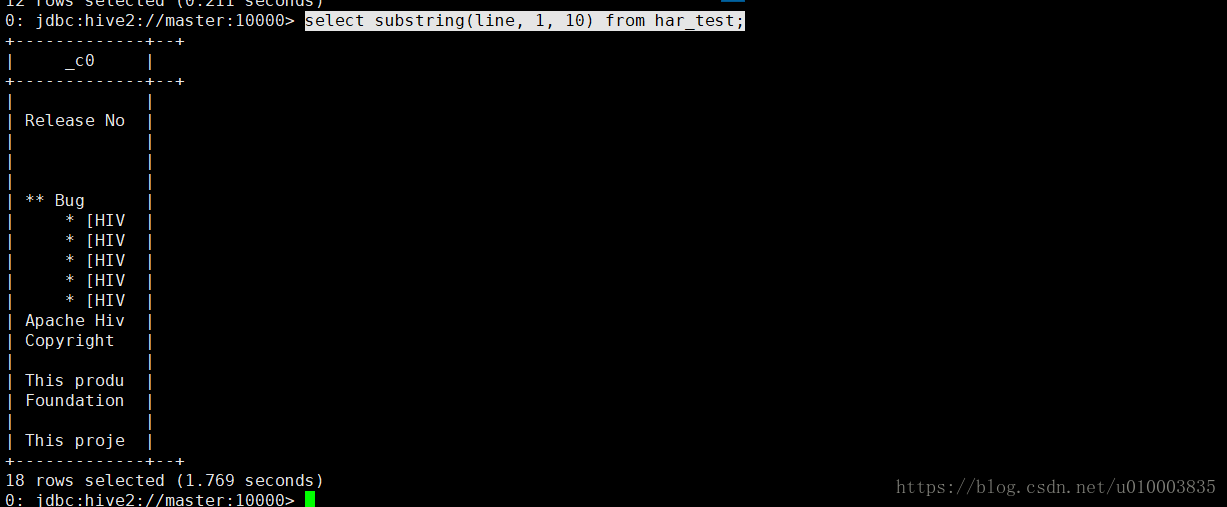
我们再来看下文件是否可查:
select substring(line, 1, 10) from har_test;
设置文件解档:
执行从har 解档指令:
alter table har_test unarchive partition(folder='docs');

从HDFS 上查看一下:

可能存在的问题:
在执行归档的时候可能出现以下问题:
Error: org.apache.hive.service.cli.HiveSQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org/apache/hadoop/tools/HadoopArchives
at org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:380)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:257)
at org.apache.hive.service.cli.operation.SQLOperation.access$800(SQLOperation.java:91)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:348)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1886)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:362)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NoClassDefFoundError: org/apache/hadoop/tools/HadoopArchives
at org.apache.hadoop.hive.ql.exec.DDLTask.archive(DDLTask.java:1526)
at org.apache.hadoop.hive.ql.exec.DDLTask.execute(DDLTask.java:414)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:100)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2183)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1839)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1526)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1237)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1232)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:255)
... 11 more
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.tools.HadoopArchives
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:338)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 21 more (state=08S01,code=1)
划重点:
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.tools.HadoopArchives
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:338)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 21 more (state=08S01,code=1)
可以看出来是缺少了包导致的问题,我们通过Maven 坐标下载下包:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-archives</artifactId>
<version>2.8.0</version>
</dependency>hadoop-archives-2.8.0.jar

并把包放到 HADOOP_HOME/lib 以及 HIVE_HOME/lib 下 (其实我也不确定到底要放置在哪一个路径下面,索性两个都放置了)
并重新启动Hadoop 以及 Hive 集群 即可解决问题!!!