文章目录
1 数据压缩配置
1.1 MR支持的压缩编码
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|
| DEFLATE | DEFLATE | .deflate | 否 |
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .bz2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
1.2 压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
| 参数 | 默认值 | 阶段 |
|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | 输入压缩 |
| mapreduce.map.output.compress | false | mapper输出 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 |
| mapreduce.output.fileoutputformat.compress | false | reducer输出 |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 |
| mapreduce.output.fileoutputformat.compress.type | RECORD | reducer输出 |
设置Map输出阶段压缩
开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。具体配置如下:
(1)开启 hive 中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
(2)开启 MR中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
(3)设置MR中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
设置Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。
属性hive.exec.compress.output控制着这个功能。默认值false,默认输出非压缩的纯文本文件。具体配置如下:
(1)开启 hive 最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
(2)开启 MR 最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
(3)设置 MR 最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
(4)设置 MR 最终数据输出压缩为块压缩(默认值式RECORD)
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
2 文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
2.1 列式存储和行式存储
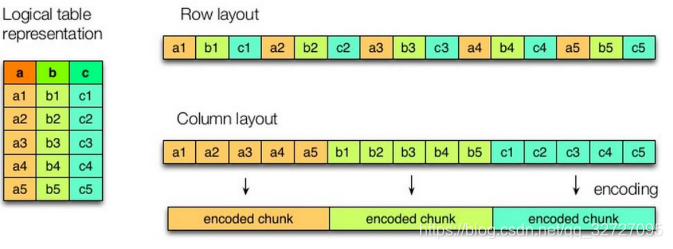
如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
1)行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
例如:SELECT * FROM table;
2)列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;并且每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
-
TEXTFILE和SEQUENCEFILE的数据格式是基于行存储的;
-
ORC和PARQUET的数据格式是基于列式存储的。
TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
Orc格式
Orc是Hive 0.11版里引入的新的存储格式。
如下图所示可以看到每个Orc文件由 1个或多个 stripe 组成,每个 stripe 一般为HDFS的块大小,每一个 stripe 包含多条记录,这些记录按照列进行独立存储,对应到 Parquet 中的 row group 的概念。每个 Stripe 里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
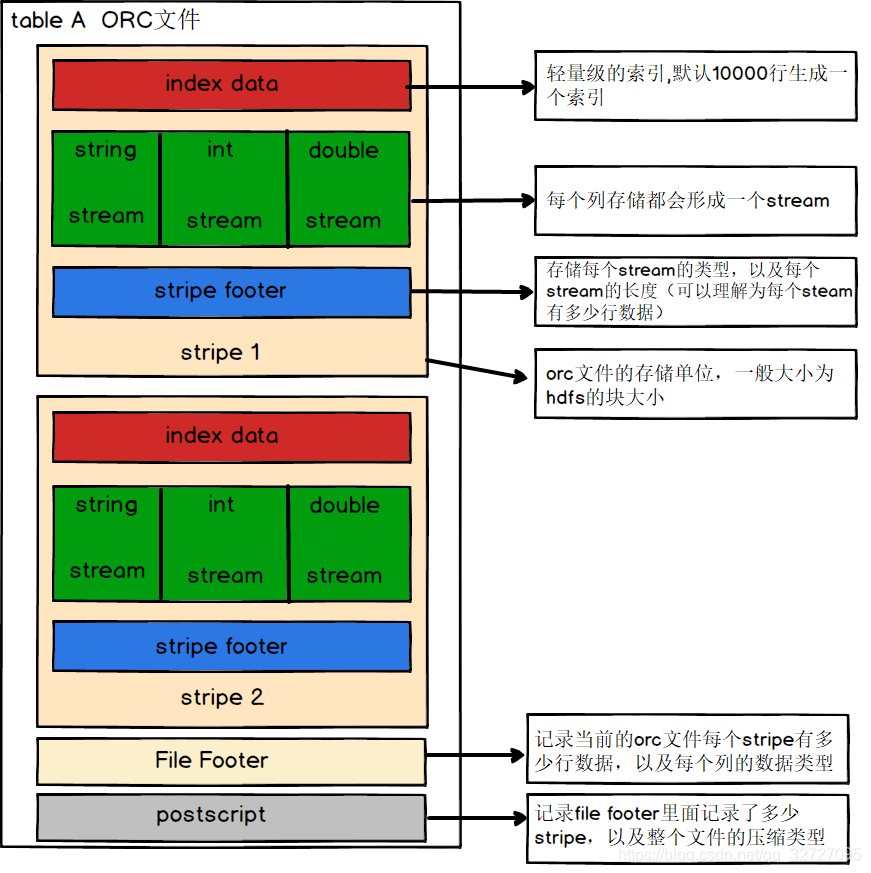
1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在 Row Data 中的 offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个 Stream 的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个 Stripe 的行数,每个 Column 的数据类型信息等;每个文件的尾部是一个 PostScript,这里面记录了整个文件的压缩类型以及 File Footer 的长度信息等。在读取文件时,会 seek 到文件尾部读 PostScript,从里面解析到 File Footer 长度,再读 File Footer ,从里面解析到各个 Stripe 信息,再读各个 Stripe ,即从后往前读。
Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
(1)行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
(2)列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
(3)页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储 Parquet 数据的时候会按照hdfs Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式。
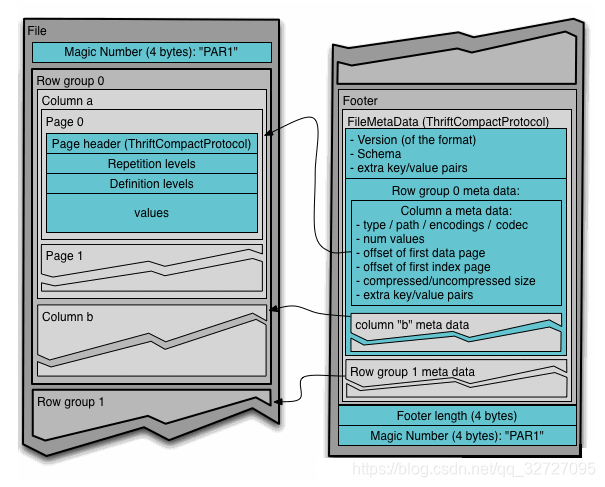
上图展示了一个 Parquet 文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的 Magic Code,用于校验它是否是一个 Parquet 文件,Footer length 记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的 Schema 信息。
除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
3 文件存储格式对比测试
从存储文件的压缩比和查询速度两个角度对比。
- 注意:一般文本文件都是行式存储格式,往 列式存储表 加载数据时,不能使用load data加载,会报格式不匹配错误,要使用 insert into查询加载
存储文件的压缩比测试:
测试数据:log.txt(文件大小18M)
1)TextFile
(1)创建表,存储数据格式为TEXTFILE
create table log_text (
。。。
)
row format delimited fields terminated by '\t'
stored as textfile;
(2)查看表中数据大小(18.13M)
hive (default)> dfs -du -h /user/hive/warehouse/log_text;
18.13M /user/hive/warehouse/log_text/log.data
2)ORC
(1)创建表,存储数据格式为ORC
create table log_orc(
。。。
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="NONE"); -- 设置orc存储不使用压缩默认会使用zlib
(2)查看表中数据大小(7.69M)
hive (default)> dfs -du -h /user/hive/warehouse/log_orc/;
7.69M /user/hive/warehouse/log_orc/000000_0
3)Parquet
(1)创建表,存储数据格式为parquet
create table log_parquet(
。。。
)
row format delimited fields terminated by '\t'
stored as parquet ;
(2)查看表中数据大小(13.1M)
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet/;
13.1M /user/hive/warehouse/log_parquet/000000_0
存储文件的对比总结:
ORC (7.69M)> Parquet(13.1M) > textFile(18.13M)
存储文件的查询速度测试:
1) TextFile
hive (default)> insert overwrite local directory '/opt/module/hive/datas/log_text' select substring(url,1,4) from log_text ;
No rows affected (10.522 seconds)
2) ORC
hive (default)> insert overwrite local directory '/opt/module/hive/datas/log_orc' select substring(url,1,4) from log_orc ;
No rows affected (11.495 seconds)
3) Parquet
hive (default)> insert overwrite local directory '/opt/module/hive/datas/log_parquet' select substring(url,1,4) from log_parquet ;
No rows affected (11.445 seconds)
存储文件的查询速度总结:查询速度相近。
存储和压缩结合测试:
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
ORC存储方式的压缩:
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.stripe.size | 268,435,456 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
| orc.bloom.filter.columns | “” | comma separated list of column names for which bloom filter should be created |
| orc.bloom.filter.fpp | 0.05 | false positive probability for bloom filter (must >0.0 and <1.0) |
- 注意:所有关于ORCFile的参数都是在HQL语句的
TBLPROPERTIES字段里面出现
1)创建一个ZLIB压缩的ORC存储方式
(1)建表
create table log_orc_zlib(
。。。
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="ZLIB");
(2)查看数据(2.78M)
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_zlib/;
2.78M /user/hive/warehouse/log_orc_none/000000_0
2)创建一个SNAPPY压缩的ORC存储方式
(1)建表
create table log_orc_snappy(
。。。
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");
(2)查看数据(3.75 M)
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_snappy/;
3.75 M /user/hive/warehouse/log_orc_snappy/000000_0
- ZLIB比Snappy压缩的还小。原因是ZLIB采用的是deflate压缩算法。比snappy压缩的压缩率高。
3)创建一个SNAPPY压缩的parquet存储方式
(1)建表
create table log_parquet_snappy(
。。。
)
row format delimited fields terminated by '\t'
stored as parquet
tblproperties("parquet.compression"="SNAPPY");
(2)查看数据(6.39MB)
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet_snappy /;
6.39MB /user/hive/warehouse/ log_parquet_snappy /000000_0
- 总结:用
mr引擎一般使用orc+lzo,用spark引擎一般使用parquet+snappy