
二 、配置mapreduce和hive中使用snappy压缩
将snappy解压,将Lib下的native复制到hadoop下的lib
1、 实际就是对mapreduce过程中数据进行压缩
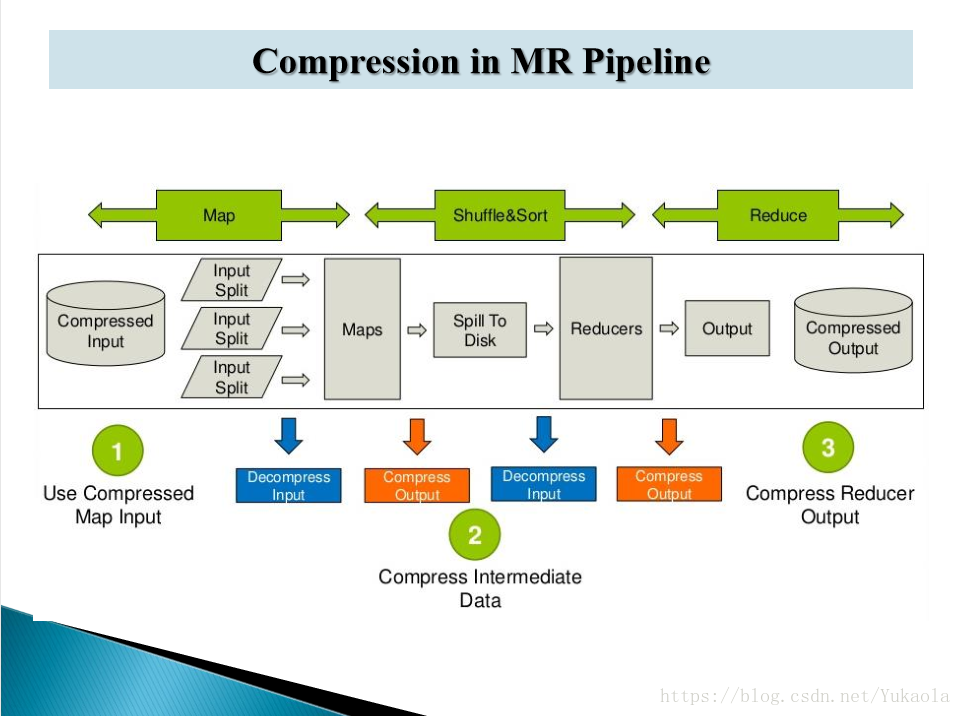
2、hadoop支持的压缩格式

3、在mapreduce中设置压缩

4、在hive中设置压缩

5、数据文件格式

数据存储
* 按行存储数据:TEXTFILE
* 按列存储数据: RCFILE ORC(存储列数较多的表) PARQUET(常用)
6、几种存储格式压缩比较

6.1、创建Text表
create table page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE ;
加载数据到表中 load data local inpath '/home/beifeng/opt/datas/page_views.data' into table page_views ;
6.2、创建ORC表
create table page_views_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc ;
加载数据到orc表 insert into table page_views_orc select * from page_views ;
6.3、创建parquet表
create table page_views_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUET ;
加载数据到parquet表 insert into table page_views_parquet select * from page_views ;
查看三种存储格式的表的大小 dfs -du -h /user/hive/warehouse/page_views/ ; 相同数据量orc格式占内存最小
在实际项目开发中数据存储格式一般用orcfile格式和qarquet格式
数据压缩格式一般用snappy格式
7、创建一张orc存储格式表,并用snappy压缩。默认的压缩格式为zlib
create table page_views_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
8、Hive企业使用优化
8.1、使用 Limit 、where 、*、不走mapreduce
8.2、大表拆分-创建子表:创建表时使用As select
8.3、外部表和分区表结合使用
CREATE EXTERNAL TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[ROW FORMAT row_format]
8.4、数据:存储格式和数据压缩,在6中已讲
8.5、将8.2、8.3、8.4结合起来创建一张表,该表为一张表的子表,用snappy压缩,表格式为parquet
set parquet.compression=SNAPPY ;
create table page_views_par_snappy
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS parquet
AS select * from page_views ;
8.6、hive高级优化——join优化Join优化官网 面试常问
数据倾斜
Common/Shuffle/Reduce Join
连接发生的阶段,发生在 Reduce Task
大表对大表
每个表的数据都是从文件中读取的

Map Join
连接发生的阶段,发生在 Map Task
小表对大表
* 大表的数据放从文件中读取 cid
* 小表的数据内存中 id
DistributedCache
SMB Join
Sort-Merge-BUCKET Join 桶的概念

设置启用自动优化

9、执行计划
EXPLAIN select * from emp ; 查看一个语句的执行信息
EXPLAIN select deptno,avg(sal) avg_sal from emp group by deptno ;
EXPLAIN EXTENDED select deptno,avg(sal) avg_sal from emp group by deptno ; 查看一个语句的详细执行信息
10、Hive高级优化
对属性进行设置
并行执行:设置job可以并行执行的个数。改为true
JVM重用:默认每个mapreduce任务都会打开新的JVM来运行程序,打开JVM需要时间,可设置每个 JVM运行多个任务
Reduce数目:map个数默认是根据块大小分配。自己手动调试Reduce个数,直到每个Reduce任务完成的时间都在一个时间范围之内。适用每天都需要测的大量数据
推测执行:属于mapreduce的优化,当在一定标准内mapreduce任务没有完成,自动开启新的任务进行执行。在使用hive时应该都设置为false

创建分区表时一般为手动
* bf_log_ip
load data path '' into table bf_log_ip partition(month='2015-09',day='20') ;
了解以下自动进行分区


作者:Yukaola
来源:CSDN
原文:https://blog.csdn.net/Yukaola/article/details/79763006
版权声明:本文为博主原创文章,转载请附上博文链接!