Explanation-Guided Training for Cross-Domain Few-Shot Classification
公众号:EDPJ
目录
2.1 Few-shot Classification(FSC)
2.2 Cross-domain Few-shot Classification(CD-FSC)
3. Explanation-guided Training
4.1 Dataset and model preparation
4.3 Explanation-guided training与LFT的结合
4.4 解析explanation-guided training的效果
0. 摘要
跨域少样本分类任务(Cross-domain few-shot classification task,CD-FSC)面对的挑战主要来自于:每个类别中有标签样本(labelled data)少,以及training set和testing set属于不同的domain。本文基于现有的FCS提出了新的训练方法。它使用了FSC模型预测时获得的解释(explanation),该值用于模型的中间特征图(feature map)。首先,我们调整了每个layer的重要性传播(relevance propagation),从而解释FSC模型的预测。第二,作者改进了与模型无关的(model-agnostic)由解释引导的(explanation-guided)训练策略:动态的寻找并强调(emphasis)对预测重要的特征。本研究不是为了提出新的解释方法,而是聚焦于explanation在训练阶段的新用法。
0.1 关键词和名词解释
- cross-domain(跨域):在source domain学习到的model(例如:识别),用于另一个不同的target domain
- few-shot(少样本):对于已经预训练(pre-train)好的model,只看过少量的labelled data(support set),就能完成task(query set)。
- N-way K-shot:few-shot learning的设置。Support set共有N个类别,每个类别有K个labelled data。
- relevance(重要性):本文使用的方法是增强对预测(分类)重要的特征,削弱对预测不重要的特征。在我看来这也应该叫做置信度,如公式(2)所示,显示的是对特征属于某一个类别确信的程度。
- BP:本文使用的是back propagation,把relevance从后往前传,最终获得初始特征的relevance。其实叫做置信传播(belief propagation)也是可以的。
- explanation(解释):通过BP,获得初始特征的relevance,也称之为explanation。这是因为:当成功预测时,与该类别对应的特征对于预测也最为重要,相应的relevance也最大。这也解释了为什么预测的是这个类别而不是其他的。
- information bottleneck(信息瓶颈):舍弃不重要的信息,保留重要的信息。本文使用的方法也是基于这个理论。但是舍弃的对某一轮(episod)预测不重要的信息可能对于其它轮的预测很重要,这就导致了overfitting。所以本作的方法虽然会舍弃一些信息,但是并不会过度。
1. 简介
人类在看到少量的样本后就能识别新的目标。然而,一般分类模型的训练和精调(fine-tune)都需要大量的labelled data。而FSC基于少量的样本就能对新的类别进行分类。在model部署后,人类标记新类别里的少量样本,这些样本是原本训练好的model没有看到过的。Testing data源于与training data同一domain的dataset。FSC面临的挑战是从源域(source domain)向目标域(target domain)的泛化。例如:人类通过少量的样本就能识别鸟和植物,而现有基于鸟训练的FSC可能不能精确地识别不同种类的植物。
解决这个问题要避免对source domain的过拟合(overfitting)。本文改进CD-FSC:explanation引导model获得更好的feature representation。Explanation的方法有:gradient-type method、Shapley-type method、LRP和LIME。它们对一个feature map的每一维计算一个score,并注明其对最终预测的重要性。
虽然许多研究在解释模型预测(explaining model prediction)领域大有进展,但它们通常是在测试阶段使用,而没有在训练阶段使用。例如:预测的审计(audit)、更综合的explanation-weighted documents representation,以及识别dataset中的偏差(biases)。
本文的FSC model使用LRP的方法。LRP已经在CNN、RNN、GNN和聚类(clustering)中使用过。它在neural network中后向传播(backpropagate)target label的relevance并把这些relevance 分配给network中的neuron。Relevance的符号和大小反映了一个neuron对预测的贡献。

上图是输入图像(有五个target label)的LRP explanation热力图(heatmap)。使用的model是在5-way 5-shot(5个类别,每个类别五个样本)的设置下,在miniImagenet上训练的RelationNet。第一行是suport images的样本。其它两行是两个query images的explanation heatmaps。两个分类都正确,且heatmap是基于不同的target label生成的。红/蓝像素分别表示正/负LRP explanation scores。颜色的强度表示explanation scores的值。如图所以,query image与support image相似度越高,红色像素越多越红,反之亦反。
中层feature map的LRP relevance被当做权重,从而构建LRP加权的feature map。这一步强化与预测更相关的feature dimension,削减与预测相关小的feature dimension。由LRP加权的特征接下来被喂给网络进行训练。因为对每一对sample-label都要计算LRP explanation,在训练时,由explanation指引的training加入了label-dependent的加权机制。该机制可以减少对source domain的overfitting。
本文explanation-guided的training策略是不受模型限制的(model-agnostic)的,且可以与其他的CD-FSC结合,例如:Learned Feature-wise Transformation(LFT)。
2. 相关研究
2.1 Few-shot Classification(FSC)
Few-shot learning有两个方向:基于优化(optimization-based),基于度量(metric-based)。前者学习可以快速迁移到新类别的初始化参数,或者设计一个学习如何更新模型参数的meta-optimizer。后者学习一个距离度量,对比support image和query image,并把query分给最接近的类别。其他的方法也值得注意,例如:
- 为model添加条件任务层(task-conditional task);
- 为新类别动态更新分类器的参数;
- 结合多模态(multi-modal)信息(例如,类别标签的word embedding);
- 通过生成(hallucinate)新样本来增强(augmentation)训练数据;
- 用无标签训练数据进行semi-supervised learning;
- 为模型添加self-supervised的机制。
然而这些方法还是要面对domain迁移的难题。
2.2 Cross-domain Few-shot Classification(CD-FSC)
基于现有的FSC方法产生了许多CD-FSC方法。
- LFT在training时学习一个噪声分布,然后将其加入intermediate feature maps,从而生成更多样的特征,并提升model的泛化性能;
- 组合多个编码器,对每个编码器的图像特征采用batch spectral regularization(BSR):限制一个batch中feature matrix的奇异值(singular vaules),使学到的feature在不同的domain有相似的谱(spectra)。即,避免model与source domain过拟合,从而提升在target domain的泛化性能;
- 与一阶MAML以及基于度量的GNN结合的方法;
- 用一个prototypical triplet loss增大类间距离,用一个large margin cosine loss减小类内距离。另一个相关研究表明,减少类内差异有益于FSC,尤其是对浅的feature encoder。
2.3 用于FSC的explanation
FSC模型可用CNN编码图像特征,许多基于度量的方法可用neural network学习距离度量。对于使用非参数(non-parametric)距离度量的FSC model,一项研究把K-means分类器变形为neural network的结构,然后用LRP获得explanation。本文使用LRP是因为:它合理的性能;其超参数的理解;相比于LIME和Shapley-type method的合理的训练速度。
3. Explanation-guided Training
3.1 CD-FSC结构
对于一个K-way N-shot task,给定用于训练的包含K个类别且每个类别中有N个labeled samples的support set ,以及用于测试的与S类别相同的query set
。CD-FSC的task:从一个base domain
上随机采样获得
,称为一个episod,用于训练FSC model;然后在另一个domain
上采样,用于测试model。
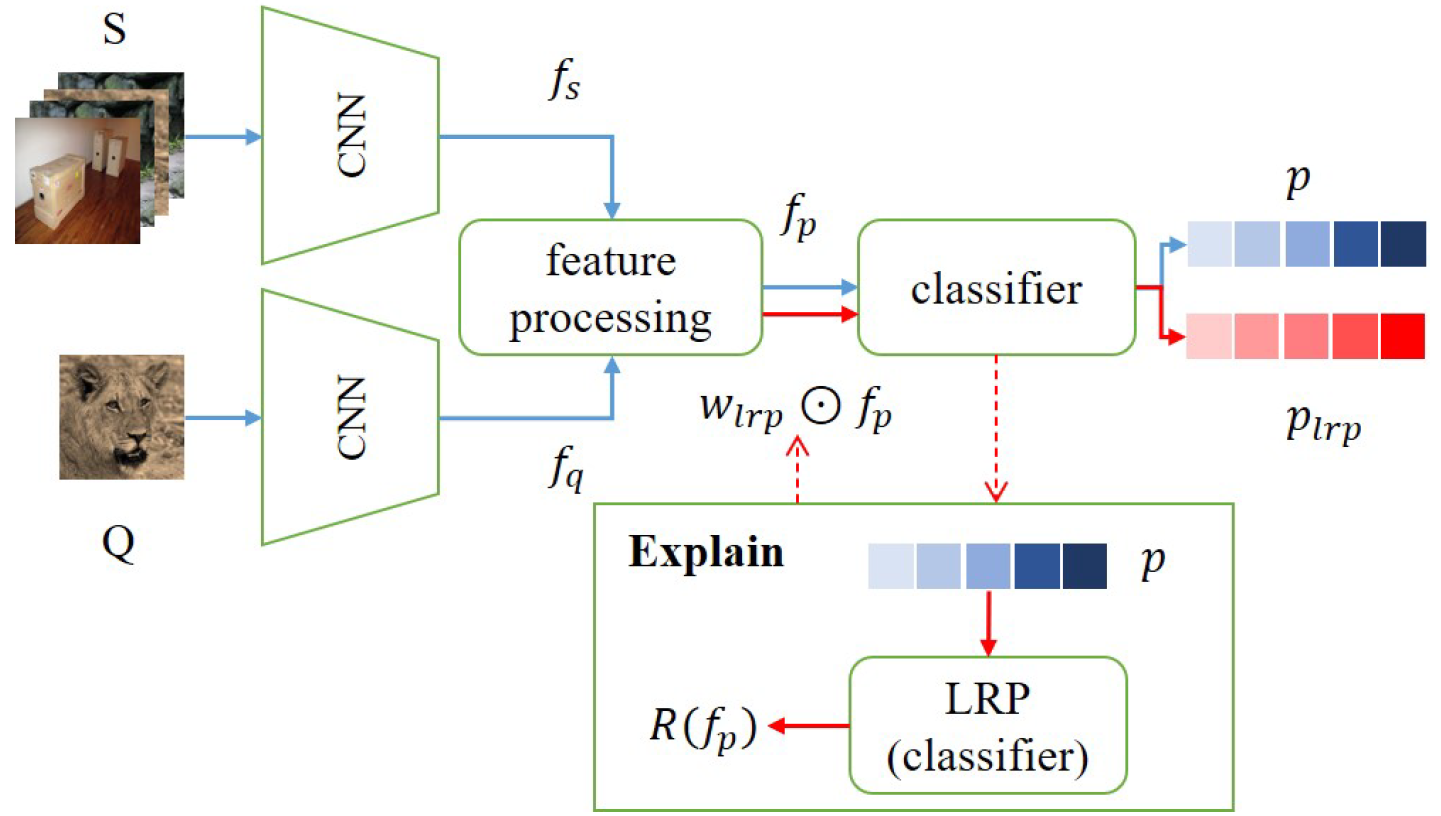
图中的蓝色路径是FSC的训练,红色路径是explanation的方法(在蓝色路径完成之后进行)。
Support set S和query set Q由CNN编码,可能有augmentated layers,从而获得support image features 和query image features
,在进行分类之前要先对它们进行处理,例如:
- 基于类别平均
,然后把平均的class representation与
成对级联;
- 设计一个attention模块,用于生成attention加权的support / query image features;
- 对
应用GNN,从而获得有garph结构的features。
分类器基于处理过的特征进行预测(分类):使用基于优化(neural network)的方法;或者基于度量(Cosine Similarity,Euclidean distances,Mahalanobis distance)的方法。预测结果为 p。
Explain模块对预测 p 解释,并生成对的解释
,该解释被用于计算LRP的权重
。
经由LRP加权的特征被喂给分类器,从而更新预测
。
3.2 Training
Step 1:基于forward-pass在model中获得预测 p
Step 2:解释分类器。对每一个label初始化LRP relevance,然后用LRP解释分类器。如上图Explain块所示,可以获得分类器输入的explanation 。
使用neural network作为分类器的FSC model,每一个label的relevance可以用它们出现的几率(logits)初始化。对于基于度量的model,因为对所有的label的预测值都是正的,这将导致对这些label有相似的explanation。
以Cosine Similarity为例,首先用公式(1)计算每个类别的概率:
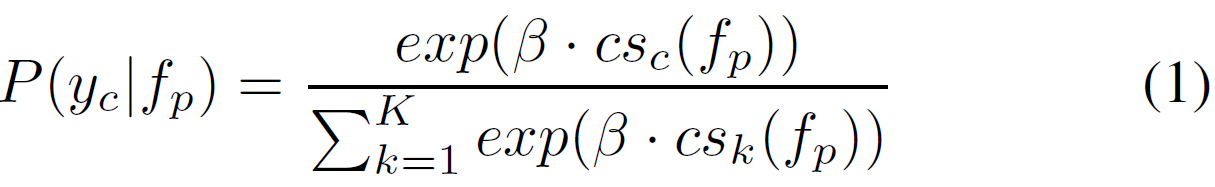
其中,是query sample和类别 k 的cosine similarity。
是喂给分类器的处理后的特征。
是用来强化最大概率的常量缩放参数。基于上式定义的概率,类别 c 的relevance表示为:
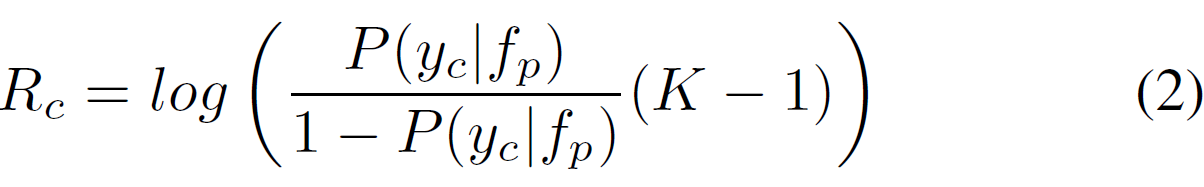
当时,
是正的。换句话说,当类别标签的概率大于随机猜猜对的概率时,该类别标签会有一个正的relevance。然后,经分类器把
后传(backpropagation,BP),最终生成relevance
。考虑到layer
的前传(forward pass,FP)表示为:
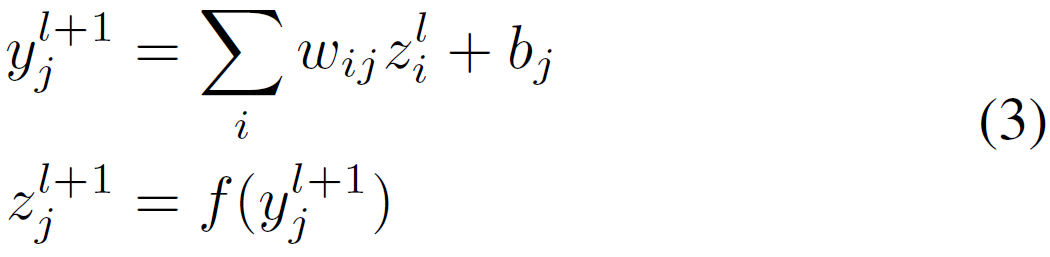
其中,是第
层neuron的索引,
是激活函数。令
表示一个neuron的relevance,用
表示
贡献的relevance。这里,依赖于两个LRP的BP机制,
:
1)

其中,是一个小正数,
确保了除法不出错。
2)
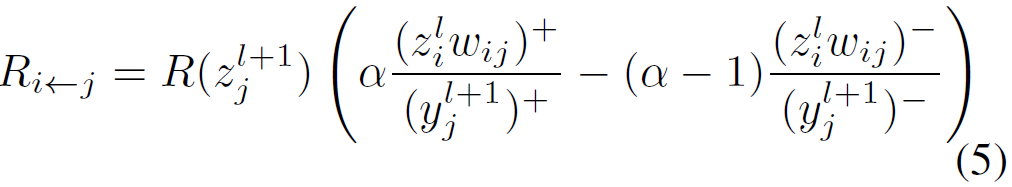
其中,控制正的relevance被BP的比例。
。
的relevance是流向它的所有的relevance的贡献之和:
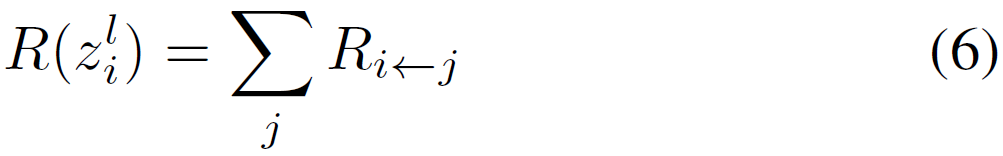
为获得,本文对线性层使用
,对卷积层使用
。
由其最大绝对值进行归一化。
Step 3:LRP加权的特征。为了强化与预测相关高的特征削弱与预测相关低的特征,定义了LRP加权以及LRP加权的特征:

其中,是按元素进行的乘积。因为在归一化后,
,所以
放大了relevance为正的特征,削弱了relevance为负的特征。
Step 4:最后,把LRP加权的特征传给分类器,生成由explanation-guided的预测:
![]()
其中,是cross-entropy loss。
是正数系数,用于控制
有多少信息被使用。
4. Experiment
本实验在RelationNet(RN)和两个最新的model上进行:cross attention network(CAN),GNN。这三个model在CD-FSC结构下的对应设置如下图:

此外,还将explanation-guided training与LFT结合,性能的提升显示出了与LFT的兼容性。
4.1 Dataset and model preparation
五个数据集:miniImagenet,CUB,Cars,Places,Plantae。miniImagenet作为训练集和验证集,其他四个作为测试集。
RN和CAN的image encoder分别为ResNet10和ResNet12。这三个model都在5-way 5-shot和5-way 1-shot的设置下训练。所有实验使用的LRP BP参数为:。
通过改变公式(9)total loss中的值,观察到:对于RN和GNN这两个使用参数可训练分类器的model,完全依赖于
使model难以收敛,且只获得微小的增益;而对CAN这种使用cosine similarity这样非参数分类器的model,则不受影响。这是因为对坏的分类器解释的意义不大,并且从一开始就会使分类器的参数偏离正常方向,尤其是few-shot的时候。因此,要和
结合来稳定训练,并在1-shot的时候增加
的比重。对于RN和GNN,5-way 1-shot时,设置为:
;5-way 5-shot时,设置为:
。对CAN,
,公式(1)cosine similarity中,
。
在测试时,进行了2000个随机采样的周期(episodes),每个episode有16个query images。
4.2 Evaluation
为了更综合的分析,使用transductive inference(转导推理 / 直推式学习):在测试阶段使用已完成高可信度分类的query images作为support images增强support set。这是一个迭代的过程。本实验实现transductive有两个迭代:第一次迭代有35个这样的query image,第二次有70个。因为GNN要求support image的数量固定,所以只在RN和CAN上使用transductive inference。

上图是关于RN和CAN的数据,图中的T表示transductive inference,通过该方法增加更多的support image确实可以提升性能。

上图是关于GNN的数据。miniImagenet是训练和验证集,其它四个是测试集。作者在下文中给出了相比于miniImagenet上的结果,其他数据集上性能不够好的原因:FSC使用的方法是移除与判别无关的信息,而在一个episodes中无用的信息可能在其他episodes是关键的。
说一下我个人的看法。
第一:可能miniImagenet中的数据与CUB和Places两个集合中数据的相关度更高,从而造成:在不同的设置上,这两个数据集上的性能明显要优于其它两个数据集。
第二:和原始的CN、CAN、GNN相比,基于LRP提升的性能很少甚至是没有提升。我在相关资料里看到,这可能是因为:作者实际做的只是获得了一个相对较好的feature ,而不是真正的解决了CD-FSC面临的跨域和少样本的问题。(诚如作者在简介中提到的)
4.3 Explanation-guided training与LFT的结合
LFTmodel用假装看过(pseudo-seen)的domain和假装没有看过(pseudo-unseen)的domain训练。在本实验中,miniImagenet是pseudo-seen domain,而其它四个集合中的三个是pseudo-unseen domain,剩下一个set用于测试。Pseudo-unseen domain用于训练特征转换层,pseudo-seen domain用于更新model中其它可训练的参数。如果特征转换层的参数固定了,那么就得到了FT:在确定的中间层添加分布固定的噪声。
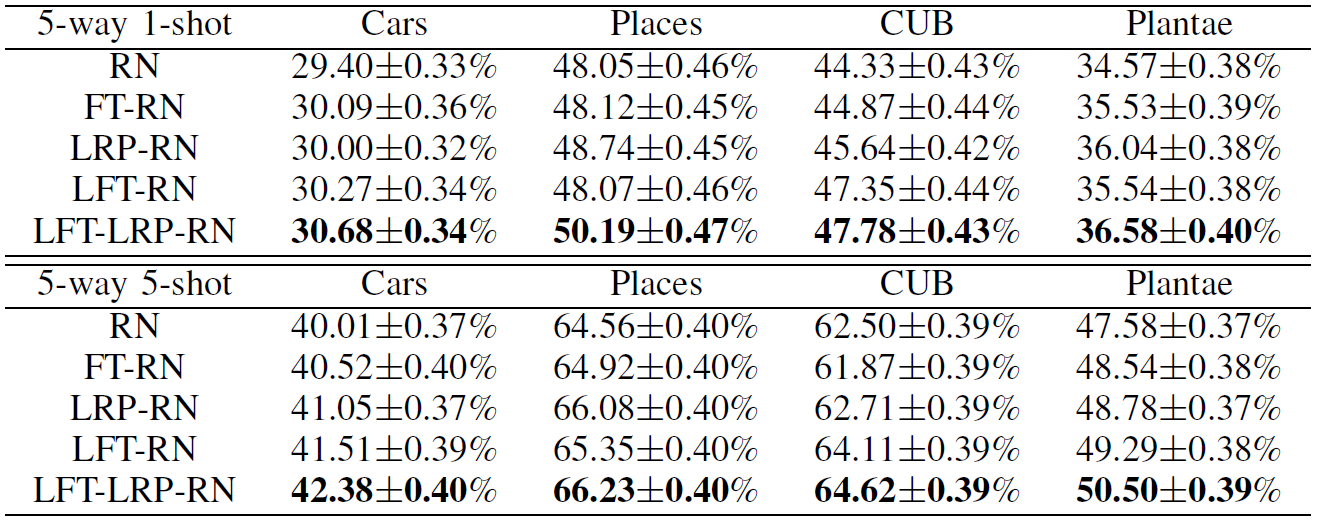
由上图可以看到,随着各种模块的逐渐加入,性能逐渐提升。
4.4 解析explanation-guided training的效果
本方法源于信息瓶颈(information bottleneck)框架:训练一个判别(discriminative)分类器,学习滤除无关的特征。信息的移除意味着与这些信息相关的通道(channel)没有被激活。
传统的分类任务只针对固定类别进行分类,所以移除无关信息没有影响。而对于FSC,在不同的episodes中,类别是变化的。在一个episodes中无用的信息可能在其他episodes是关键的,所以就造成了测试集相比于验证集的性能下降。
如果分类器过度拟合并且经常预测错误的类别标签,则explanation-guided training将识别错误预测类别的相关特征,并对其进行强化,随后的loss将对这些强化的特征进行更多惩罚。这避免了中间特征倾向于某一类别,从而实现更好的泛化性能。
实验结果显示,explanation-guided training可以避免过度的信息移除,从而避免对source domain的overfitting。
4.5 LRP的量化分析
本节,把输入图像的LRP explanation视觉化为热力图(heatmap)。从热力图中,可以轻松地观察到图像的哪一部分被用于预测。

上图第一行是support images,对于每一个query image,都给出了attention heatmap和LRP heatmap。对于正确分类的Q1和Q3,正确标签的LRP heatmap高亮了相关特征。特别地,LRP heatmap可以捕获bus的窗户特征以及malamute的头部特征。
虽然其他错误标签的LRP heatmap显示了更多的负面证据,但我们仍然可以在query image和被解释标签之间找到相似。例如,当我们解释Q3:malamute的标签时,LRP heatmap突出了圆形结构内的纹理。
5. 参考
Sun J, Lapuschkin S, Samek W, et al. Explanation-guided training for cross-domain few-shot classification[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 7609-7616.