Multi-view Deep Network for Cross-view Classification
CVPR 2016 IEEE Conference on Computer Vision and Pattern Recognition
Meina Kan1,2 Shiguang Shan1,2 Xilin Chen1
1Key Laboratory of Intelligent Information Processing of Chinese Academy of Sciences (CAS), Institute of Computing Technology, CAS, Beijing, 100190, China
2CAS Center for Excellence in Brain Science and Intelligence Technology {kanmeina, sgshan, xlchen}@ict.ac.cn
摘要
跨视图识别是计算机视觉中的一个重要问题,它主要是对不同视图之间的样本进行分类。不同的视图之间的巨大差异使得这个问题相当具有挑战性。为了消除复杂的(甚至是高度非线性的)视点差异以获得良好的跨视点识别,我们提出了一个多视点深度网络(multi-view deep network, MvDN),该网络寻求多个视点之间共享的非线性鉴别和视点不变表示。具体来说,我们提出的MvDN网络由两个子网络组成,视图特定的子网络试图消除视图特定的变化,下面的公共子网络试图获得所有视图共享的公共表示。作为MvDN网络的目标,从所有视图的样本中计算Fisher损失,即瑞利商目标,以指导整个网络的学习。因此,来自MvDN网络顶层的表示法对差异具有鲁棒性,并且具有区分性。分别在13和2个视图的3个数据集上进行的跨姿态和跨特征类型的人脸识别实验表明了该方法的优越性,特别是与典型的线性方法相比。
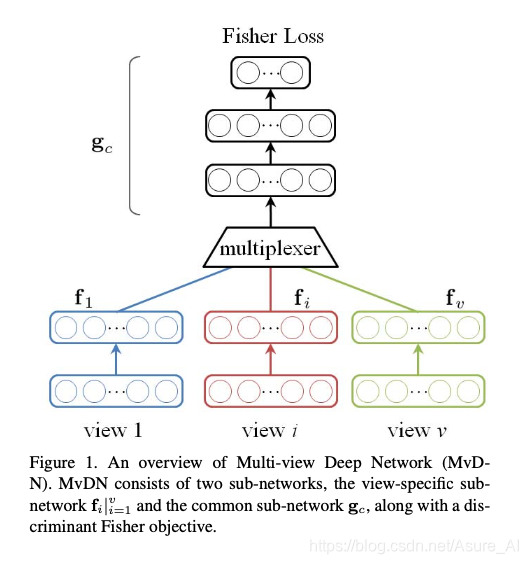
上图就是作者的主要思想,包含两个子网络。第一个网络是view-specific sub- network,另一个就是common sub-network gc。第一个网络的fi,即第i个视图所特有的子网络,负责消除第i个视图的特定信息,而gc即所有视图共享的公共子网络,则进一步提取所有视图共享的判别表示。
introduction(日常diss)
CCA:CCA只适用于双视图场景。
MCCA:通过最大化任意两个视图之间的总相关性,可以得到每个视图对应的v视图变换。虽然通过上述方法可以使视图差异最小化,但是没有明确考虑类标签等判别信息,不利于识别和分类。
MVDA(multi-view discriminant analysis):这些判别方法得益于有监督信息,通常优于无监督信息。这些方法大多是线性的,可能不足以应付具有挑战性的场景。
KCCA:核函数太难找
DCCA:比kcca好。但是也是无监督的呀
总的来说,许多研究都很好地解决了如何处理视点差异以进行视点识别或视点分类的问题。然而,它们是线性的,不能很好地处理具有挑战性的非线性场景,无监督的深度方法不能识别,或内核化的监督方法可能会吸出样本问题。为了解决这些问题,我们提出了一种显式非线性监督方法——多视点深度网络。
我们提出的多视点深度网络(MvDN)通过一个深度架构来同时处理视点的差异和区别,从而实现多视点之间的描述和视点不变表示。具体地说,我们提出的MvDN包括两个子网络,特定于视图的子网络和所有视图共享的公共子网络。采用所有视图样本的瑞利商目标来保证整个网络的判别。因此,来自MvDN顶层的特征表示对查看变化具有鲁棒性
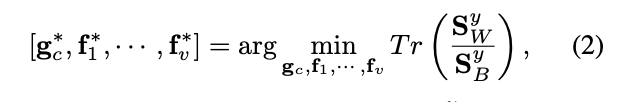
这就是这个网络优化函数,其实很多论文的优化目标都是这个。SyB 表示类间差距,SyW 表示类内差距。当然,一个好的分类肯定是类内差距越小越好,类间差距越大越好。
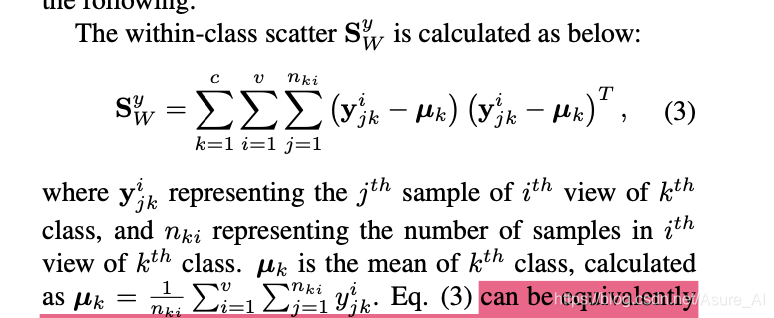
这个就是类内差距解释。就是求每一个类的每一个样本和这个类所有样本的平均值的差值(无视视图),然后把所有的类加起来就是总的类内间距。
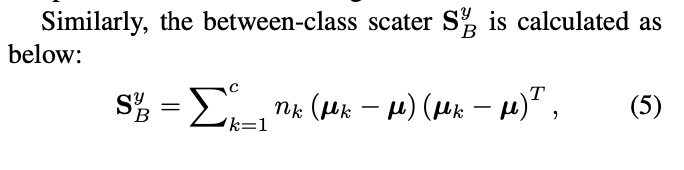
这个就是类间间距,nk是说的每个类有多少个,然后用这个nk乘以当前类的平均值减去所有样本的平均值(就是所有类的所有视图的所有样本),然后就得出。
然后接下来就是优化了
计算
先把网络权重啥的随机赋值,然后前向传播求出loss
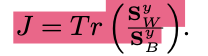
然后接下来算J对Y的导数

这里是数学变换,看不懂也没太大关系。。。要是解释起来就麻烦了。。。
然后接下来计算Y对gc网络的梯度

自然gc网络之后,就是计算Y对fi网络的梯度

然后最后用BFGS来优化整个网络


其实就是BP反向传播过程。最后整个网络就被训练好了。
然后你就可以用这个训练好的网络来对测试机进行分类。