本篇论文是在ImageNet上大放异彩,将CNN应用于cv大舞台,论文的作者是Alex Krizhevsky,来自加拿大多伦多大学Hinton组,所以论文中的模型又叫AlexNet。
概述
ImageNet数据集共有150万张图片,分为22000个类别。Image Large-Scale Visual Recognition Competition(ILSVRC-2010)和ILSVRC-2012是其中的一个子集,AlexNet在ILSVRC-2010上取得了很好的成绩,top-1和top-5的错误率分别为37.5%和17.5%。在ILSVRC-2012上top-1和top-5的错误率分别为15.3%和26.2%。AlexNet具有6M参数和65万个神经元。文中提出了很多观点,如今仍然沿用,所以说这篇文文章具有开创性的贡献。
模型结构
AlexNet具有5个卷积层和3个全连接层,需要说明的是大部分参数都是在全连接层,每一个卷积层包含不到1%的参数。而且作者强调去掉模型中的任何一层都会影响模型的精度。模型结构图如下所示:
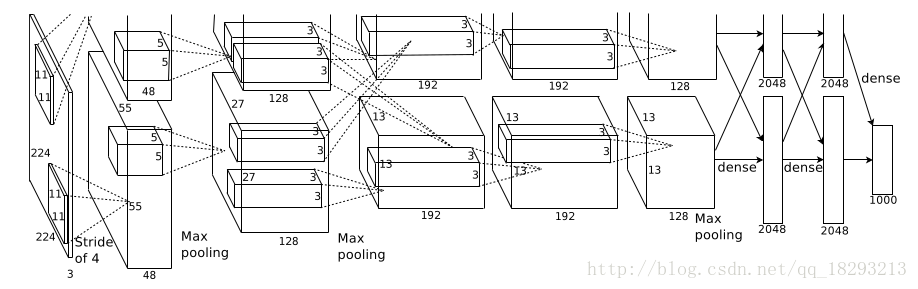
我们可以看出这是上下两个相同的结构,由于当时GPU的显存不够大,作者使用的GTX580只有3G的显存,所以采用两个GPU并行计算。模型结构为conv->max pooling->conv->max pooling->conv->conv->conv->max pooling->fc1->fc2->fc3。最后的全连接层有1000个神经元,目的是为了分1000个类别。以第一层为例,说明下参数分别为什么:
输入图像大小:224*224*3
卷积核大小:11*11 96个
步长:4
输出feature map为:96个size为55*55的feature map
ReLU Nonlinearity
作者提出在常见的激活函数为
和
,但是它们都有饱和区,在饱和区训练速度比非饱和区要慢很多。而且我们都知道饱和区非常容易造成梯度弥散,ReLU的出现就是为了解决这一个问题。
ReLU函数的表达式为
。
多GPU训练
由与参数数量巨大,单GPU无法完成训练,所以作者采用两块GPU一块训练,每一块GPU上具有一半的kernels。大家可以查看上面模型图,第一层具有96个kernels,作者在下面画了48个在上面画了48个。GPU之间通信只发生在部分层中。第2、4、5层仅与上一层驻留在同一个GPU中的kernels相连,第3层和全连接层与前层的两块GPU相连接。
Local Response Normalization局部响应归一化
局部响应归一化使得模型的top-1和top-5错误率分别降低了1.4%和1.2%。现在有了BatchNormalization这个好像用的不太多了。
上面这个公式中, 均为超参数,N为该层所有kernel的个数。就是在所有feature map的(x,y)位置处做一个归一化,我们可以想象其中一种情况。当 的范围为 时,就是把第 个feature map的 处的像素值比上第 个feature map的前后各 个feature map的 处的像素值的和。
Overlapping Pooling
下采样的过程中步长小于kernel的大小。这个方法使得top-1和top-5的错误率分别下降了0.4%和0.3%。
减少过拟合
1、数据增强
第一种数据增强的方法是数据裁剪,训练时从256*256大小的数据上提取224*224大小的数据,以及原图的水平和垂直翻转之后也进行这样的操作。这直接使数据集变为原来的2048倍。测试时,对输入数据从四个角和中心处提取224*224大小的patch,以及对输入数据的水平翻转之后也这样操作,所以测试数据共提取了10个块,对这10个块分别进行预测,然后取平均。
第二中数据增强的方法是采用PCA改变训练数据的RGB通道的像素值。
2、Dropout
Dropout以一定的概率将神经元的输出置0,使得这个神经元既不参与前向计算也不参与后向传播。降低了神经元之间的相互依赖性,迫使其它神经元必须学习更多的信息。由于每次丢弃神经元不同,也就使得模型每次都略有不同,所以也就相当于训练了多个模型,最终的结果 由多个模型共同计算得出。 在测试时间,我们使用所有的神经元,但将它们的输出乘以0.5,这对于采用指数衰减网络产生的预测分布的几何平均值是合理的近似。
训练
采用随机梯度下降法,并且网络参数的初始化方式为权重初始化方式是均值为0,标准差为0.01。第2、4、5和全连接层的偏置为1,这样可以使得神经元在初始阶段为正值,因为ReLU的负数部分激活值为0。其它层的偏置初始化为0。120万张图像在两块GTX580上训练了6天时间。
结果
ILSVRC-2010数据集上top-1和top-5的错误率分别为37.5%和17.0%。
而且在第一层卷积层中可视化96个kernels的结果如下:

上面3行为第一块GPU的结果,是颜色无关的。下面3行为第二块GPU的结果,是颜色有关的。
参数数量
AlexNet中有60million(6000万)个参数和650000+个神经元,如果算上输入图像的话共有约809800个神经元。
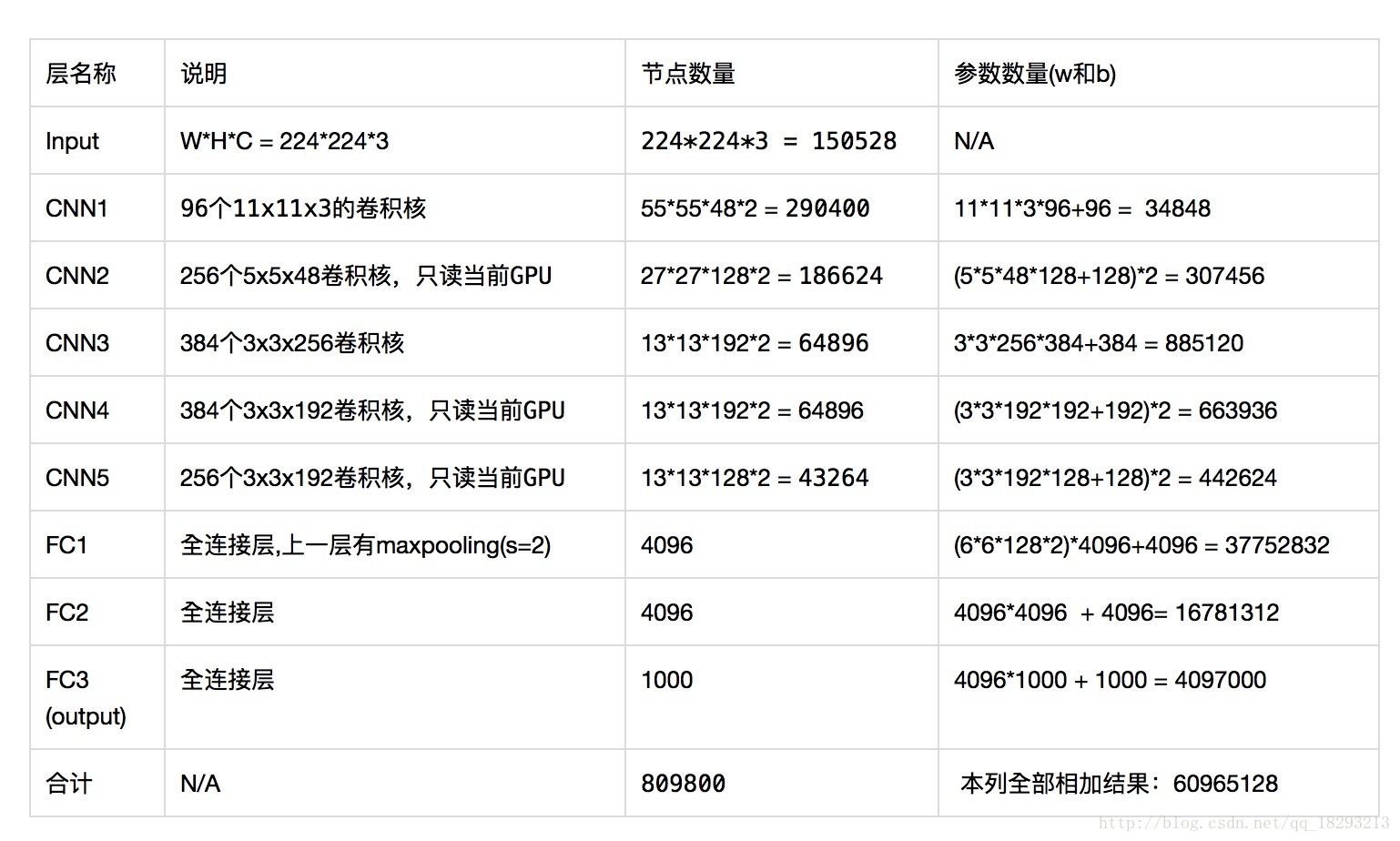
解析可能还有些问题,请批评指正。
reference
[1] https://vimsky.com/article/3664.html