本教程介绍如何用Python的机器学习库scikit-learn去编写逻辑回归分类器。
首先介绍一下IRIS数据集,IRIS数据集包含了150条花的数据,前4列是花的4个特征(feature),第五列是花的类别(label),下图展示了IRIS的特性,可以看出,选任意2个特征看(每个小图),都很难直接用简单的IF-ELSE语句用人工规则根据feature判断label。
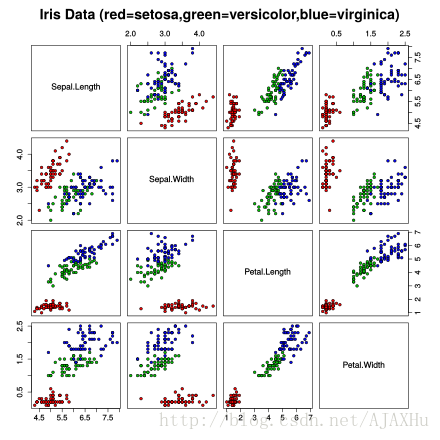
下面介绍如何用Python机器学习库scikit-learn(sklearn)利用逻辑回归对IRIS进行分类。在介绍代码前先介绍一些基础知识,以便顺利地运行或阅读代码:
1.本代码需要依赖的第三方Python库有scikit-learn、requests和matplotlib,其中一些库使用pip安装会特别麻烦(尤其在Windows上)。
对于Ubuntu:
sudo apt-get install python-scipy
sudo apt-get install python-matplotlib
sudo pip install scikit-learn
sudo pip install requests对于Windows:
- 安装Anaconda
- 进入Anaconda Prompt,
使用conda create -n scipy python=2.7新建一个conda环境(以后就不需要运行这个命令了) 进入Anaconda Prompt,使用activate scipy激活Python环境,执行命令:
conda install scikit-learn
conda install matplotlib
pip install requests
2.在训练分类器时,往往选择数据集的80%作为训练集,20%作为测试集。测试时不在80%的训练集上进行,只在20%的测试集上进行,这是为了检测算法是否过拟合。
3.教程代码中用到了map语法,即将一个数组的每个元素进行相同的变换,映射为另一个数组。如有一个数组x = [2,3,4,5,6],语句[ v + 1 for v in x]会返回一个新数组[3,4,5,6,7],x自身不会变化。
4.教程代码中将原始的字符串label(3种)转换为了3个label_id(整数型,0,1,2)。
代码:
#coding=utf-8import requests
import random
#下载IRIS数据集
data_url = "https://raw.githubusercontent.com/CrawlScript/Tensorflow-AutoEncoder/master/tutorial_datasets/iris/iris.data"
raw_data = requests.get(data_url).text
features_list = [] #用于存放所有特征
label_list = [] #用于存放所有label
label_dict = {} #字典,用于存放label名和label id的映射
last_label_id = -1
#输入label名,获取label id
#如果label_dict中已经包含了label_name,直接获取其中的label_name
#如果label_dict不包含label_name, 用当前最大的label id加1作为label id,并将其加入label_dict
def convert_label(label_name):
global last_label_id
if label_name in label_dict:
return label_dict[label_name]
else:
last_label_id += 1
label_dict[label_name] = last_label_id
return last_label_id
line_list = raw_data.split() #把数据按行切分
random.shuffle(line_list) #打乱数据
#将每行数据转换为features和label
for line in line_list:
values = line.split(",")
features = [float(value) for value in values[:-1]] #从每行提取特征
features_list.append(features)
label_id = convert_label(values[-1])
label_list.append(label_id)total_size = len(label_list) # 计算总数据量
split_size = total_size * 4 // 5 # 取80%作训练集
#切分训练集和测试集
train_features_list = features_list[:split_size]
train_label_list = label_list[:split_size]
test_features_list = features_list[split_size:]
test_label_list = label_list[split_size:]
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(C = 1e5) #C是正则项参数的倒数,C越小正则项参数越大,正则项参数用于防止过拟合
#用训练集训练逻辑回归分类器
classifier.fit(train_features_list, train_label_list)
predict_label_list = classifier.predict(test_features_list) #分类器在测试集上预测
print("features | target | predict") #按照特征、真实label、预测label进行排版
for i in range(len(test_label_list)):
features = test_features_list[i]
features = [str(feature) for feature in features]
target = test_label_list[i]
predict = predict_label_list[i]
print("{} | {} | {}".format(features, target, predict))输出:
features | target | predict
['5.5', '2.3', '4.0', '1.3'] | 1 | 1
['5.4', '3.4', '1.5', '0.4'] | 2 | 2
['5.2', '3.4', '1.4', '0.2'] | 2 | 2
['6.4', '2.8', '5.6', '2.2'] | 0 | 0
['6.6', '2.9', '4.6', '1.3'] | 1 | 1
['4.9', '3.0', '1.4', '0.2'] | 2 | 2
['5.7', '2.5', '5.0', '2.0'] | 0 | 0
['4.8', '3.0', '1.4', '0.3'] | 2 | 2
['4.6', '3.1', '1.5', '0.2'] | 2 | 2
['5.2', '4.1', '1.5', '0.1'] | 2 | 2
['5.0', '3.0', '1.6', '0.2'] | 2 | 2
['6.8', '3.0', '5.5', '2.1'] | 0 | 0
['6.3', '2.7', '4.9', '1.8'] | 0 | 0
['6.1', '2.6', '5.6', '1.4'] | 0 | 0
['6.7', '3.1', '4.7', '1.5'] | 1 | 1
['6.7', '3.3', '5.7', '2.5'] | 0 | 0
['4.7', '3.2', '1.6', '0.2'] | 2 | 2
['5.0', '3.4', '1.5', '0.2'] | 2 | 2
['5.7', '2.8', '4.1', '1.3'] | 1 | 1
['5.8', '2.7', '5.1', '1.9'] | 0 | 0
['4.3', '3.0', '1.1', '0.1'] | 2 | 2
['5.4', '3.9', '1.3', '0.4'] | 2 | 2
['5.4', '3.7', '1.5', '0.2'] | 2 | 2
['4.4', '2.9', '1.4', '0.2'] | 2 | 2
['4.8', '3.4', '1.9', '0.2'] | 2 | 2
['6.2', '3.4', '5.4', '2.3'] | 0 | 0
['5.1', '3.8', '1.9', '0.4'] | 2 | 2
['6.1', '2.8', '4.7', '1.2'] | 1 | 1
['6.7', '3.0', '5.2', '2.3'] | 0 | 0
['5.9', '3.0', '4.2', '1.5'] | 1 | 1
可加QQ群426491390讨论机器学习、数据挖掘等相关知识。