一.介绍
k近邻算法(k-nearnest neighbor,kNN)是一种基本分类与回归方法。
思想:给定测试案例,基于某种距离度量找出训练集中与其最靠近的k个实例点,然后基于这k个最近邻的信息来进行预测。
在分类任务中,使用“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;
在回归任务中,使用“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;还可以基于距离远近进行加权或者加权投票,距离越近的实例权重越大。
k近邻算法不具有显式的学习过程,事实上,它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为0,待收到测试样本后再进行处理。
二.k近邻算法三要素
k近邻算法是1968年Cover和Hart提出。距离度量、k值的选择及分类决策规则是k近邻法的三个基本要素。
根据距离度量(如曼哈顿距离或者欧式距离),可计算测试实例与训练集中的每个实例点的距离,根据k值选择k个最近邻,最后根据分类决策规则将测试实例分类。
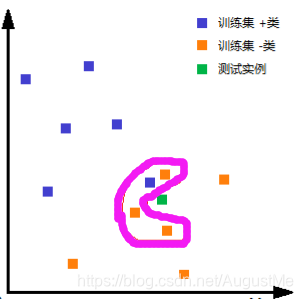
如上图所示,
首先,我们根据欧式距离,选择k=4个离测试实例最近的训练实例;
然后,再根据多数表决的分类决策规则,即这4个训练实例中3个属于“-类”,1个属于“+类”,少数服从多数,我们将测试实例归为“-类”。
1.距离度量
特征空间中的两个实例点的距离是两个实例点相似程度的反映。k近邻算法的特征空间一般是n维实数向量空间Rn。使用的距离是欧氏距离,但也可以是其他距离,如更一般的Lp距离或Minkowski距离。
各种距离度量详解:https://blog.csdn.net/AugustMe/article/details/91387370
2.k值的选择
k值的选择会对k近邻算法的结果产生重大影响。
在应用中,k值一般选取一个比较小的数值,通常采用交叉验证法来选取最优的k值。
3.分类决策规则
k近邻算法中分类决策规则往往是投票表决,即由输入实例的k个近邻的训练实例中的多数类决定输入实例的类。
二.Python代码实现kNN
1.算法伪代码

2.python代码
# -*- coding: UTF-8 -*-
import numpy as np
import operator
import collections
"""
group - 数据集
labels - 分类标签
"""
def createDataSet():
#四组二维特征
group = np.array([[1,101],[5,89],[108,5],[115,8]])
#四组特征的标签
labels = ['爱情片','爱情片','动作片','动作片']
return group, labels
"""
函数说明:kNN算法,分类器
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
def classify0(inx, dataset, labels, k):
# 计算距离
dist = np.sum((inx - dataset)**2, axis=1)**0.5
# k个最近的标签
k_labels = [labels[index] for index in dist.argsort()[0 : k]]
# 出现次数最多的标签即为最终类别
label = collections.Counter(k_labels).most_common(1)[0][0]
return label
if __name__ == '__main__':
#创建数据集
group, labels = createDataSet()
#测试集
test = [101,20]
#kNN分类
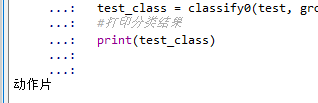
test_class = classify0(test, group, labels, 3)
#打印分类结果
print(test_class)
结果:
调用sklearn
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
x = np.array([[1,101],[5,89],[108,5],[115,8]])
y = [1,1,0,0]
#y = ['爱情片','爱情片','动作片','动作片']
k = 3
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(x,y)
x_test = np.array([[101,20]])
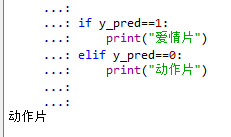
y_pred = knn.predict(x_test)
if y_pred==1:
print("爱情片")
elif y_pred==0:
print("动作片")
结果:
三.k如何取值
举一个具体的例子
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#读取鸢尾花数据集
iris = load_iris()
x = iris.data
y = iris.target
k_range = range(1, 31)
k_error = []
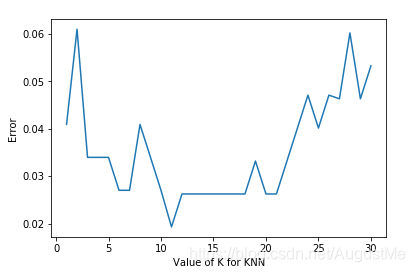
#循环,取k=1到k=31,查看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
k_error.append(1 - scores.mean())
#画图,x轴为k值,y值为误差值
plt.plot(k_range, k_error)
plt.xlabel('Value of K for KNN')
plt.ylabel('Error')
plt.show()
结果
四.KNN的优缺点
KNN算法的优点:
1、思想简单,理论成熟,既可以用来做分类也可以用来做回归;
2、可用于非线性分类;
3、训练时间复杂度为O(n);
4、准确度高,对数据没有假设,对outlier(离群点)不敏感;
缺点:
1、计算量大;
2、样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
3、需要大量的内存;
其伪代码如下:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选择与当前距离最小的k个点;
- 确定前k个点所在类别的出现概率
- 返回前k个点出现频率最高的类别作为当前点的预测分类。
参考与引用:
https://blog.csdn.net/eeeee123456/article/details/79927128
https://www.cnblogs.com/further-further-further/p/9670187.html
https://blog.csdn.net/qq_41995574/article/details/90343759
https://scikit-learn.org/stable/modules/neighbors.html#classification
https://cloud.tencent.com/developer/article/1336144
https://blog.csdn.net/hanshuobest/article/details/77484668
仅用来个人学习和分享,如若侵权,留言立删。
尊重他人知识产权,不做拿来主义者!
喜欢的可以关注我哦QAQ,
你的关注和喜欢就是我write博文的动力