K近邻(K-Nearest Neighor,KNN)学习是一种常用的监督学习方法,它的思想非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的K个训练样本,然后基于这K个邻居的信息进行预测。KNN是一种基本的机器学习算法。KNN既可以用作分类,也可以用作回归。KNN做分类预测时,一般是选择多数表决法,即训练集里和预测的样本特征最近的K个样本,预测为里面有最多类别数的类别。而KNN做回归时,一般是选择平均法,即最近的K个样本的样本输出的平均值作为回归预测值。
一般通过交叉验证选择最优的K值。对于距离的度量方式,最常见的是欧氏距离:
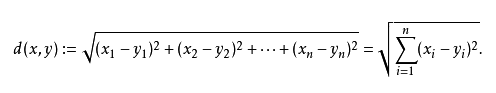
KNN的主要优点有:
1) 理论成熟,思想简单,既可以用来做分类也可以用来做回归
2) 可用于非线性分类
3) 训练时间复杂度比支持向量机之类的算法低,仅为O(n)
4) 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
5) 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
6)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分
KNN的主要缺点有:
1)计算量大,尤其是特征数非常多的时候
2)样本不平衡的时候,对稀有类别的预测准确率低
3)使用懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
4)相比决策树模型,KNN模型可解释性不强
# K近邻
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 随机生成数据
x, y = make_classification(n_clusters_per_class=1, n_samples=500, n_redundant=0, n_features=2, random_state=14)
# 数据划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=2)
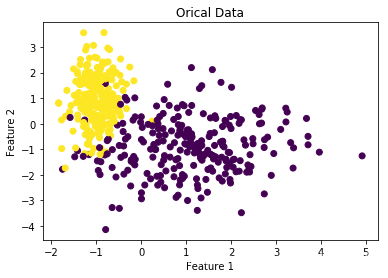
# 画出原始数据
plt.scatter(x[:, 0], x[:, 1], c=y)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Orical Data')
plt.show()
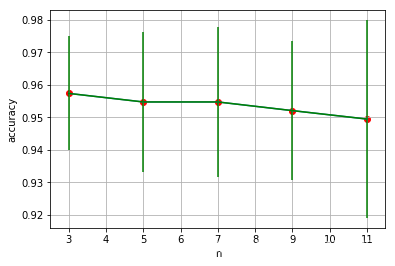
# 参数n_neighbor的选择
n_neighbors = [3, 5, 7, 9, 11]
# 平均值
accuracy_list = []
# 方差
accuracy_std = []
# 找到最优参数
for n in n_neighbors:
knn = KNeighborsClassifier(n_neighbors=n)
scores = cross_val_score(knn, x_train, y_train, cv=5)
accuracy_list.append(scores.mean())
accuracy_std.append(scores.std())
# 可视化
plt.grid()
plt.plot(n_neighbors, accuracy_list)
plt.scatter(n_neighbors, accuracy_list, c='r')
plt.errorbar(n_neighbors, accuracy_list, accuracy_std, c='g')
plt.xlabel('n')
plt.ylabel('accuracy')
plt.show()
# 由上图可以看出n_neighbor最优值为3
knn = KNeighborsClassifier(n_neighbors=3).fit(x_train, y_train)
y_pred = knn.predict(x_test)
print('tesing accuracy:', accuracy_score(y_pred, y_test))
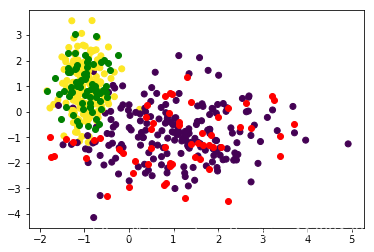
# 画出训练集样本点
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train)
# 画出测试集样本点
for i in range(len(x_test)):
if y_pred[i] == 0:
plt.scatter(x_test[i, 0], x_test[i, 1], c='r') # 标签为0的样本点
else:
plt.scatter(x_test[i, 0], x_test[i, 1], c='g') # 标签为1的样本点
plt.show()