今天复习的算法超级超级超级简单!!就是KNN!!!
一、算法介绍
算法思想:给定一个带标检的训练数据集(就是带分类结果的样本),对于一个新的输入实例,我们在训练数据集中以某种距离度量方式找出与该输入实例距离最近邻的k个实例。找出这k个实例(这也是knn中k的含义)中类别出现最多的那个类别,最后我们就将该新的输入实例划分为此类别。(没啦,是不是超简单~~哈哈哈)
在此我们解释一下算法中的一些概念:
KNN算法如果用大多都用来分类,很少用于回归,虽然可以做回归!
k值:当 k = 1 的时候就是表示最近邻算法,即对于一个新输入的实例,它的所属类别就是和训练样本中和它最近的实例类
别。当k过大,会导致近似误差大,较远的实例都会对最终的判定起作用;k过小,估计误差大,对近邻的点敏感。所以一般
在没有先验知识下都是采用交叉验证的方式选取。
距离度量:一般情况下是Lp距离,
Lp距离定义为:
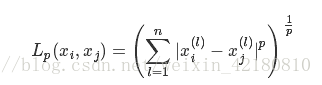
当 p = 1 时为曼哈顿距离;
当 p = 2 时为欧氏距离;
当 p为无穷时,它是各个坐标距离的最大值,即
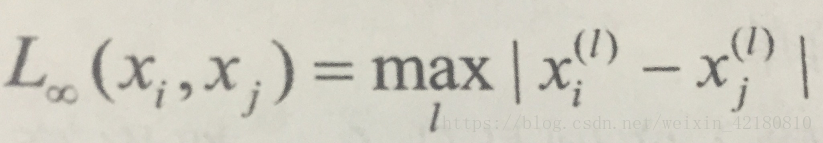
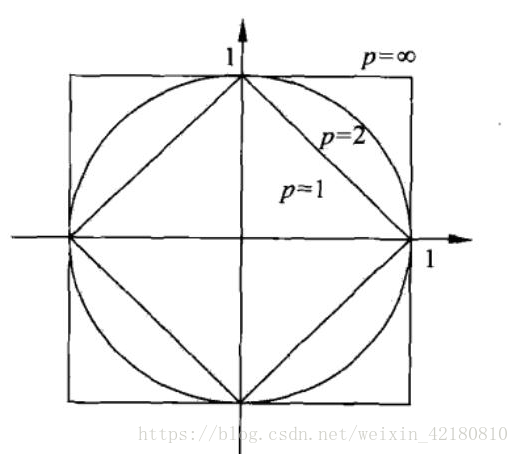
下面给出在二维空间中p取不同值是,与原点的Lp距离为1的点的图形。
二、优缺点
优点: (1)易于理解,易于实现,参数少;
(2)特别适用多分类。
缺点: (1)计算量大,内存开销大;
(2)理论说服力粗糙。
三、sklearn中的函数(基于python)
from sklearn.neighbors import KNeighborsClassifier
KNeighborsClassifier()中的参数介绍(我在此只介绍一部分用到概率较大的):
(1)n_neighbors:默认值为5,就是上面讲到的最近的k个点中的k值;
(2)weights:表权重的意思,默认值为平均权值"uniform",可以选择"distance"代表越近的点权重越高,或者传入自己编写的以距离为参数的权重计算函数;
(3)algorithm:快速k近邻搜索算法,默认为"auto"(会自己根据输入的数据用最好的算法进行搜索);
(4)p:默认为2,表上面提到的距离度量方式,p = 2 即欧式距离,所以默认的距离度量方式为欧式距离。
主要参考
李航 《统计学习方法》