摘要
最近引入了几个大型的完形填空样式【context-question-answer】的数据集:CNN和Daily Mail新闻数据以及儿童阅读测试。由于这些数据集的大小,与其他方法相比,使用了深度学习技术的文本理解任务是非常适合的。我们提出了一个新的简单模型,该模型使用注意力直接从上下文中选择答案,而不是像在类似模型中通常那样使用文档中单词的混合表示来计算答案。这使得该模型特别适用于答案是文档中单个单词的情况。我们模型在所有评估的数据集上都达到了新的技术水平。
1.介绍

到目前为止,人类收集的大多数信息都以纯文本形式存储。因此,在人工智能领域,教学机器如何理解这些数据的任务至关重要。测试文本理解水平的一种方法就是简单地问系统问题,然后从文本中推断出答案。可以利用大量非结构化文档来回答问题的系统就是一个著名的例子,例如IBM的Watson系统被用于Jeopardy挑战。
完形填空式的问题,即通过从句子中删除短语形成的问题,是此类问题的一种有趣的形式(例如,见图1)。虽然任务易于评估,但可以改变上下文,问题句子或问题中缺少的特定短语,从而显着改变任务的结构和难度。
改变任务难度的一种方法是改变被替换的单词类型,如(Hill等,2015)。这种变化的复杂性来自这样一个事实,即正确预测不同类型的单词所需的上下文理解水平差异很大。虽然可以使用相对简单的模型(几乎不需要上下文知识)轻松完成介词的预测,但是预测命名实体需要对上下文有更深入的了解。
而且,与从文本中选择随机句子相反,问题可以从文档的特定部分形成,例如文本的摘要或标签列表。由于此类句子通常以简明形式释义,因此特别适合测试文本理解能力。
完形填空样式问题的一个重要属性是,可以从现实世界文档中自动生成大量此类问题。这为需要大量数据的技术(例如深度学习)开辟了解决任务的途径。与较小的机器理解数据集相比,这是一个优势,后者只有数百个训练样例,因此性能最好的系统通常依赖于手工构建的功能。
在本文的第一部分中,我们介绍了手头的任务以及相关数据集。然后,我们提出自己的模型来解决该问题。随后,我们将模型与先前提出的体系结构进行比较,最后描述关于模型性能的实验结果。
2.任务和数据集
在本节中,我们介绍了我们要解决的任务以及最近为此任务引入的相关大规模数据集。
2.1 任务说明
任务包括回答完形填空样式的问题,答案取决于与问题相关的上下文文档的理解。该模型还提供了一组可能的答案,从中可以选择正确的答案。可以将其形式化如下:
训练数据由元组
组成,其中
是一个问题,
是一个包含问题
答案的文档,
是一组可能的答案,
是真值答案。
和
都是来自词汇
的单词序列。我们还假设所有可能的答案都是词汇表中的单词,即
,并且真值答案
出现在文档中,即
。
2.2 数据集
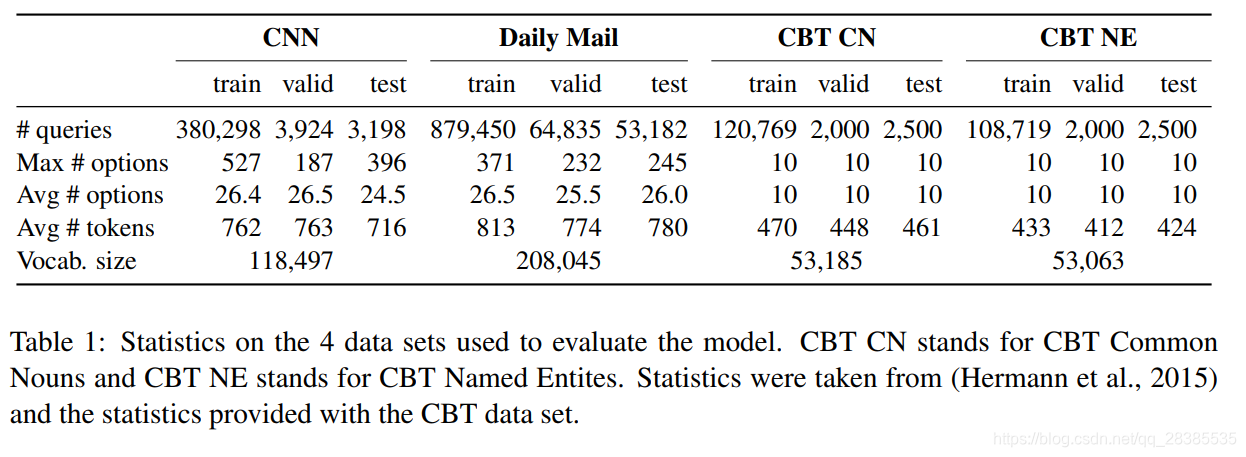
现在,我们将简要概述数据集的重要特征。
2.2.1 新闻文章—CNN和Daily Mail
前两个数据集是根据CNN和Daily Mail网站上的大量新闻文章构建的。每篇文章的主体构成一个上下文,而完形填空样式问题由出现在每篇文章页面顶部的短的高亮句子之一构成。具体而言,问题是通过从摘要语句中替换命名实体来创建的(例如,“Producer X will not press charges against Jeremy Clarkson, his lawyer says.”)。
此外,整个数据集中的命名实体被匿名字符替换,每个示例都对其进行了重新排序,因此该模型无法建立有关该实体的任何世界知识,因此必须真正依赖于上下文文档来寻找答案。
(Chen et al.,2016)提供了对CNN数据集中回答问题所需的推理模式以及人类在此任务上的表现的定性分析。
2.2.2 儿童阅读测试
第三个数据集,即儿童阅读测验(CBT)是根据古腾堡计划免费提供的图书构建而成的。每个上下文文档由20个连续的句子组成,这些句子取自儿童读物。由于缺少摘要,因此根据后续句子(第21句)构造完形填空样式问题。
人们还可以看到任务复杂度如何随所省略单词(命名实体,常用名词,动词,介词)的类型而变化。 (Hill et al.,2015)表明,尽管标准LSTM语言模型在预测动词和介词方面具有人类水平的性能,但在命名实体和普通名词上却落后于人。因此,在本文中,我们仅关注预测前两个单词的类型。
表1总结了有关CNN,Daily Mail和CBT数据集的基本统计信息。
3.Attention Sum Reader
我们的模型称为Attention Sum Reader(AS Reader),是量身定制的,以利用答案是上下文文档中的单词这一事实。这是一把双刃剑。尽管它在所有提到的数据集上都达到了最好的结果(在此假设成立的情况下),但它无法提供文档中未包含的答案。直观地,我们的模型结构如下:
- 我们计算问题的嵌入向量。
- 我们计算整篇文档中每一个独立单词的嵌入向量(上下文嵌入)。
- 在问题嵌入和文档中每次出现候选答案的上下文嵌入之间使用点积,我们选择最可能的答案。
3.1 形式化描述
我们的模型使用一个词嵌入函数和两个编码器函数。词嵌入函数
将单词转换为矢量表示。第一个编码器函数是文档编码器
,它在整个文档的上下文中对文档
中的每个单词进行编码。我们称其为上下文嵌入。为方便起见,我们将
中第
个单词的上下文嵌入表示为
。第二编码器
用于将问题
转换为与每个
具有相同维的固定长度向量表示。两种编码器均使用
计算的词嵌入作为输入。然后,我们计算文档中每个单词的权重,作为其上下文嵌入和问题嵌入的点积。该权重可以被视为问题
对文档
的注意力。
为了使文档中的单词上形成适当的概率分布,我们使用
函数对权重进行归一化。这样,我们对概率
建模,以使问题
的答案出现在文档
中的位置
处。以函数形式表示为:
最后,我们计算出单词
是正确答案的概率为:
其中
是
在文档
中出现的一组位置集合。我们称这种机制为指针总和注意力,因为我们将注意力用作上下文文档中离散字符的指针,然后我们将所有出现的单词的注意力直接求和。这不同于sequence-to-sequence模型中通常使用的注意力,在这种模型中,注意力用于将单词的表示混合到新的嵌入向量中。我们对注意力的使用受到Pointer Networks(Ptr-Nets)的启发。
我们模型的一个高级结构展示在图2中。
3.2 模型细节

在我们的模型中:
(1)文档编码器
被实现为双向门控循环单元(GRU)网络,其每一时刻的隐藏状态形成上下文词嵌入,即
,其中
表示向量级联,
和
表示循环网络的前向和后向上下文嵌入。
(2)问题编码器
由另一个双向GRU网络实现。这次将前向网络的最后一个隐藏状态与后向网络的最后一个隐藏状态连接起来以形成问题嵌入,即
。
(3)词嵌入函数
以通常的方式实现为查找表
。
是一个矩阵,其行表示为词汇表中的单词索引,即
。因此,
的每一行都包含来自词汇表的一个单词的嵌入。
在训练期间,我们共同优化
,
和
的参数。
4.相关工作
几种最新的深度神经网络架构被应用于文本阅读理解的任务。最后两种架构是在我们研究的同时独立开发的。所有这些体系结构都使用一种注意力机制,使它们能够突出显示文档中可能与问题有关的单词位置。现在,我们将简要描述这些体系结构并将它们与我们的方法进行比较。
4.1 Attentive and Impatient Readers
Attentive and Impatient Readers在(Hermann et al.,2015)中提出。更简单的Attentive Reader与我们的体系结构非常相似。它同样使用双向文档和问题编码器以与我们类似的方式计算注意力。更为复杂的Impatient Reader会在阅读问题的每个单词后计算出对文档的关注度。但是,经验评估表明,这两种模型在CNN和Daily Mail数据集上的表现几乎相同。
Attentive Reader与我们的模型之间的主要区别在于,Attentive Reader使用注意力来计算文档
的固定长度表示
,该表示等于
中单词的上下文嵌入的加权和,即
。然后,联合问题和文档嵌入
是
和问题嵌入
的非线性函数。最后,该联合嵌入m使用点积
与所有候选答案
比较,最后将分数用softmax归一化。即:
。
与Attentive Reader相反,我们直接使用计算的注意力从上下文中选择答案,而不是对单个表示的加权求和这种注意力方式(请参见等式2)。进行这种简化的动机如下。
考虑一个上下文:“
” 和问题“
”
由于January和March都是不错的候选答案,因此注意力机制可能会在上下文中对这两个候选答案给予相同的关注。上述混合机制将计算这两个单词的表示形式之间的向量,并提出最接近的单词作为答案-这很可能发生在2月(对于在Google新闻上训练的Word2Vec确实是这种情况)。相比之下,我们的模型将正确建议一月或三月。
4.2 Chent et al. 2016
(Chen et al.,2016)中提出的模型是受Attentive Reader的启发。一个区别是注意力权重是用双线性函数而不是简单的点积计算的,即:
。嵌入文档的
是使用加权总和来计算的,如在Attentive Reader中:
。最后,
,其中
是新的嵌入函数。
即使是Attentive Reader的简化版,该模型的性能也比原始模型好得多。
4.3 Memory Networks
MemNN被应用于(Hill et al.,2015)的文本理解任务。
性能最佳的记忆网络模型设置(窗口内存)使用以候选字为中心的固定长度(8)的窗口作为记忆单元。由于上下文窗口的限制,模型无法捕获该窗口范围之外的依赖项。此外,在该窗口内的表示被简单地计算为该窗口中单词嵌入的总和。相比之下,在我们的模型中,每个单词的表示都是使用循环网络计算的,这不仅使它可以从整个文档中捕获上下文,而且嵌入计算比简单的总和要灵活得多。
为了提高初始准确性,Hill等人使用了一种称为自我监督的启发式方法,以帮助网络使用与我们的相似之处的注意力机制来选择正确的支持“记忆”。没有这种启发式的普通MemNN在这些机器读取任务上没有竞争力。我们的模型不需要任何类似的启发式方法。
4.4 Dynamic Entity Representation
动态实体表示模型具有复杂的架构,该架构也基于加权注意力机制和每个命名实体的向量上下文嵌入的最大池化。
4.5 Pointer Networks
我们的模型架构受PtrNets的启发,使用注意力机制来选择上下文中的答案,而不是将上下文中的单词融合为答案表示。PtrNet由一个编码器和一个解码器组成,它们在每个步骤都需要使用注意力选择输出,而我们的模型则在一个步骤中输出答案。 此外,指针网络假定序列中的任何输入都不会出现多次,这在我们的设置中不是这种情况。
4.6 总结
我们的模型结合了上述架构中的最好特点。我们使用循环网络来“读取”文档和问题,并且我们以类似于Ptr-Nets的方式使用注意力。我们还以类似于MemNNs的方式使用注意力权重的总和。
从较高的角度来看,我们通过删除注意力步骤之后的所有转换来简化所有讨论的文本理解模型,并直接使用注意力来计算答案概率。