文章目录
Abstract
大型卷积网络模型最近在ImageNet基准上展示了优越的分类性能(如Krizhevsky等人的18)。然而,为什么他们表现得这么好,或者他们如何才能得到改善,对于这些目前还没有明确的理解。在本文中,我们将探讨这两个问题。我们介绍了一种新的可视化技术,该技术可以深入了解中间特征层的功能和分类器的操作。在诊断方面,这些可视化使我们能够在ImageNet分类基准上找到比Krizhevsky等人更好的模型架构。我们还进行了消融研究,以发现模型不同层的性能贡献。我们展示了我们的ImageNet模型可以很好地推广到其他数据集:当softmax分类器被重新训练时,它超越当前在Caltech-101和Caltech-256数据集上的最先进的结果。
1. Introduction
卷积网络(convnets)自上世纪90年代初由LeCun等人[20]引入以来,在手写数字分类和人脸检测等方面表现出了优异的性能。在过去的18个月里,一些论文已经表明,它们也可以在更具挑战性的视觉分类任务中提供出色的性能。Ciresan等人用[4]演示了在NORB和CIFAR-10数据集上的最佳性能。最值得注意的是,Krizhevsky等人的18在2012年ImageNet分类基准上显示了破纪录的性能,他们的卷积网络模型获得了16.4%的错误率,而第二名的结果是26.1%。在这项工作的基础上,Girshick等人的10在PASCAL VOC数据集上显示出了领先的检测性能。有几个因素导致了这种显著的性能改善:(i)更大的训练集的出现:数百万个标记的例子;(ii)强大的GPU实现:使得超大型模型的训练成为现实;(iii)更好的模型正则化策略,如Dropout[14]。
尽管这些进展鼓舞人心,但对于这些复杂模型的内部操作和行为,以及它们如何实现如此良好的性能,我们仍然知之甚少。从科学的角度来看,这是非常令人失望的。如果不清楚它们是如何以及为什么工作的,那么只能通过试错法来开发更好的模型。在这篇论文中,我们介绍了一种可视化技术,它展示了在模型的任何层中激发单个特征映射的输入刺激。它还允许我们在训练过程中观察特征的演变,并诊断模型的潜在问题。我们提出的可视化技术是利用Zeiler等人提出的多层反卷积网络(deconvnet)将特征激活投影回输入像素空间。我们还通过遮挡输入图像的部分来对分类器的输出进行敏感性分析,揭示场景的哪些部分对分类是重要的。
使用上述这些工具,我们从Krizhevsky等人的18架构开始,探索不同的架构,以发现在ImageNet上表现更好的架构。然后,我们研究了该模型对其他数据集的泛化能力(只是重新训练了最后的softmax分类器)。因此,这是一种监督预训练的形式,不同于Hinton等人[13]和其他人[1,26]推广的非监督前训练方法。
1.1 Related Work
Visualization: 通过可视化特征来获得对网络的直觉是一种常见的做法,但主要用于第一层(在第一层中,可以对像素空间进行投影)。在较高的层中,必须使用替代方法。[8]在图像空间中通过梯度下降的方式寻找每个单元的最优刺激,使单元的激活最大化。这需要仔细的初始化,并且不提供关于单元不变性的任何信息。受后一种方法的启发,19展示了如何围绕最优响应计算给定单元的Hessian,从而得到了一些对不变性的了解。问题是,对于更高的层,不变性是非常复杂的,所以很难用简单的二次逼近来捕捉。相比之下,我们的方法提供了不变性的非参数视图,显示了训练集中的哪些模式激活了特征图。我们的方法类似于Simonyan等人的当前工作,他们演示了如何通过从网络的全连接层(而不是我们使用的卷积特征)投影来从卷积网络获得显著性映射。Girshick等人的10展示了识别数据集中的patch的可视化,这些patch负责模型中较高层次的强激活。我们的可视化的不同之处在于,它们不仅是输入图像的裁剪,而且是自顶向下的投影,显示每个刺激特定特征图的patch中的结构。
Feature Generalization: 同时,Donahue等人的[7]和Girshick等人的[10]也探讨了我们对卷积网络特征泛化能力的论证。前者使用卷积网络特性在Caltech-101和Sun scene数据集上获得最先进的性能,后者在PASCAL VOC数据集的对象检测上获得最先进的性能。
2. Approach
我们在论文中使用了标准的全监督卷积神经网络模型,如LeCun等人[20]和Krizhevsky等人[18]定义的。这些模型通过一系列的层将彩色二维输入图像xi映射到概率向量yi^上的C个不同的类。每一层包括:
(i)前一层输出(对于第一层是输入图像)与一组已学习滤波器的卷积;
(ii)通过校正后的线性函数(relu(x) = max(x, 0))传递响应;
(iii)[可选]局部区域上的最大池;
(iv)[可选]局部对比操作,规范化特征图间的响应。
有关这些操作的更多细节,请参见[18]和[16]。网络的顶层是传统的全连接网络,最后一层是softmax分类器。图3显示了我们在许多实验中使用的模型。

图3:我们的8层convnet模型的架构。一个224×224的裁剪图像(有3个彩色通道)作为输入。输入与96种不同的第一层卷积过滤器(红色)进行卷积,每个滤波器大小为7×7,x和y中的步长都是2。得到特征图谱后:(i)通过修正线性函数(图中未显示);(2)池化(3x3的区域内取最大值,步长2);(3)对比度归一化特征图以得到96个不同的55×55元素特征图。类似的操作在第2、3、4、5层重复。最后两层是全连接层,以顶层卷积层的特征作为矢量输入(6·6·256 = 9216维)。最后一层是C-way softmax函数,C表示类的数量。所有的过滤器和特征图都是正方形的。
我们使用一组N个标记图像{x, y}来训练这些模型,其中标记yi是一个表示真实类的离散变量。利用一个适合于图像分类的交叉熵损失函数来比较yi和yi^。通过反向传播整个网络中参数损失的导数对网络中的参数(卷积层中的滤波器、全连接层中的权矩阵和偏差)进行训练,并通过随机梯度下降更新参数。训练细节见第3节。
2.1 Visualization with a Deconvnet
理解卷积神经网络的操作需要解释中间层中的特征激活。我们提出了一种将这些激活映射回输入像素空间的新方法,显示了最初是什么输入模式导致了特征映射中的给定激活。我们使用反卷积网络(deconvnet) (Zeiler等人的[29])来执行这个映射。可以将deconvnet看作是使用相同组件(过滤、池化)但反过来使用的convnet模型,因此与其将像素映射到特性,不如反过来使用。在Zeiler等人的[29]中,deconvnets被提出作为一种执行无监督学习的方法。在本文中,它们没有任何学习能力,只是作为一个已经训练过的卷积神经网络的探针。
为了检查一个卷积神经网络,我们在它的每一层上都附加了一个反卷积神经网络,如图1(顶部)所示,提供了一条返回图像像素的连续路径。首先,将输入图像喂给卷积神经网络,并计算各层的特征。为了检查给定的convnet激活,我们将该层中的所有其他激活设置为0,并将特征映射作为输入传递到附加的deconvnet层。然后我们依次(i)unpool;(ii) rectify;(iii)filter来重建使所选激活的底活动。然后重复此操作,直到到达输入像素空间。
 图1:顶部:一个反卷积网络层(左)连接到一个卷积网络层(右)。反卷积网络将从下面的层重建卷积网络特征的近似版本。下图:使用在convnet的池化过程中记录每个池化区域(彩色区域)的最大位置的switch,来演示deconvnet中的反池化操作。黑/白条是特征图中的负/正激活。
图1:顶部:一个反卷积网络层(左)连接到一个卷积网络层(右)。反卷积网络将从下面的层重建卷积网络特征的近似版本。下图:使用在convnet的池化过程中记录每个池化区域(彩色区域)的最大位置的switch,来演示deconvnet中的反池化操作。黑/白条是特征图中的负/正激活。
**Unpooling:**在convnet中,最大池化操作是不可逆的,但是我们可以通过记录switch变量集合中每个池区域内的最大值位置来获得近似的逆。在deconvnet中,反池化操作使用这些switches将来自上一层的重构放到适当的位置,保持刺激的结构。有关该过程的说明,请参见图1(底部)。
**Rectification:**该卷积神经网络采用relu非线性激活函数,对特征图进行校正,从而保证特征图总是正的。为了在每一层得到有效的特征重构(也应该是正的),我们通过一个relu非线性函数传递重构信号。(我们还尝试使用前馈relu操作施加的二进制掩码进行矫正,但是结果的可视化效果明显不太清晰。)
**Filtering:**该卷积神经网络使用已学得的滤波器对前一层的特征图进行卷积。为了近似地反转它,deconvnet使用相同过滤器的换位版本(如其他自动编码器模型,如RBMs),但应用于校正后的映射,而不是下面那层的输出。在实践中,这意味着垂直和水平翻转每个过滤器。
注意,在此重建路径中,我们不使用任何对比归一化操作。从较高的层次向下投射使用convnet上行通道的最大池化层所产生的switch设置。由于这些switch设置是特定输入图像所特有的,因此,通过单个激活得到的重构类似于原始输入图像的一小块,其结构根据其对特征激活的贡献进行加权。由于模型是有区别地训练的,它们隐式地显示了输入图像的哪些部分是有区别的。注意,这些投影不是来自模型的样本(而是原始输入的patch),因为不涉及生成过程。整个过程类似于支持单个强激活(而不是通常的梯度),即计算
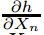
,其中h是具有强激活的特征图的元素,Xn是输入图像。(理解:xn对h的响应有多大)但是,它的不同之处在于(i) relu是独立施加的;(ii)没有使用对比度归一化操作。我们的方法的一个普遍缺点是,它只可视化单个激活,而不是层中存在的联合活动。然而,如图6所示,这些可视化是刺激模型中给定特征图的输入模式的精确表示:当部分原始输入图像的对应模式被遮挡,我们可以看到特征图中激活的明显下降。
3. Training Details
我们现在描述将在第4节中可视化的大型convnet模型。该体系结构如图3所示,与Krizhevsky等人[18]用于ImageNet分类的体系结构相似。一个不同之处在于,在Krizhevsky的3、4、5层中使用的稀疏连接(由于模型被分割为2个gpu)在我们的模型中被替换为密集连接。在图5的可视化检查之后,还发现了与层1和层2相关的其他重要差异,如4.1节所述。
模型在ImageNet 2012训练集(130万张图像,1000多个不同的类)[6]上进行训练。每个RGB图像的预处理是通过调整最小尺寸为256,裁剪中心256x256区域,减去每个像素的平均值(所有训练图像),然后使用10个大小为224x224的不同的裁剪(四角+中心,水平翻转)。使用小型批量大小为128的随机梯度下降来更新参数,从学习率为10(-2)开始,动量为0.9。当验证错误趋于稳定时,我们会在整个培训过程中手动对学习率进行衰减。Dropout[14]用于全连接层(6和7),速率为0.5。所有的权值初始化为10(-2),偏差设置为0。
在训练过程中对第一层过滤器的可视化显示,它们中有几个占主导地位。为了解决这个问题,我们对卷积层中每个均方根值超过这个固定半径10^(-1)倍的过滤器进行了重新标准化。这是至关重要的,特别是在模型的第一层,其中输入图像大致在[-128,128]范围内。与Krizhevsky等人的[18]一样,我们对每个训练示例生成多个不同的裁剪和翻转,以增加训练集的大小。我们在70个epoch之后停止了训练,这在一个GTX580 GPU上需要花费大约12天,使用基于[18]的实现。
4. Convnet Visualization
使用第3节中描述的模型,我们现在使用deconvnet来可视化ImageNet验证集上的特性激活。
Feature Visualization: 图2显示了训练完成后模型的特征可视化。对于给定的特征图,我们显示了最大的9个激活,每个激活都分别投射到像素空间,显示了激活该map的不同结构,并显示了其对输入变形的不变性。在这些可视化的同时,我们展示了相应的图像patch。这些比可视化有着更大的变化,可视化只关注每个patch中的判别结构。例如,在第5层第1行第2列,这些patch看起来没有什么共同点,但是可视化显示,这个特殊的特征映射集中在背景的草地上,而不是前景的对象上。
每一层的投影显示了网络中特征的层次性。第2层响应角落和其他边缘/颜色连接。第三层有更复杂的不变性,捕捉相似的纹理(如网格模式(R1,C1);文本(R2,C4))。第4层变化明显,且更具有类特异性:狗的脸(R1,C1);鸟的腿(R4,C2)。第5层显示了具有显著姿态变化的整个对象,例如键盘(R1,C11)和狗(R4)。


图2:在完全训练的模型中可视化特征。对于第2-5层,我们在验证集特征图的随机子集中显示最大的9个激活,使用反卷积网络方法投射到像素空间。我们的重构不是来自模型的样本:它们是来自验证集的重构模式,在给定的特征图中引起高激活。对于每个feature map,我们也给出了相应的图像patch。注:(i)每个特征图的强分组,(ii)更高层次的不变性和(iii)图像中有区别的部分(如狗的眼睛和鼻子(第4层,第1行,第1列))的放大。以电子形式观看效果最佳。压缩工件是30Mb提交限制的结果,而不是重构算法本身。
Feature Evolution during Training: 图4显示了在将给定的特征映射映射回像素空间的过程中,最强激活(所有训练示例中)的训练过程。外观的突然跳跃是由生成最强响应的图像的改变(变为另一张图)引起的。可以看到模型的较低层在几个epochs内收敛。然而,较高层只有在大量量的epoch(40-50)之后才会发展,这表明需要让模型训练直到完全收敛。

图4:训练中随机选择的模型特征子集的演化。每一层的特征都显示在不同的块中。在每个块中,我们在epoch(1、2、5、10、20、30、40、64)显示随机选择的特征子集。可视化显示了给定特征图的最强激活(在所有训练示例中),使用我们的deconvnet方法将其投射到像素空间。色彩对比度被人为地增强,图形以电子形式显示效果最佳。
4.1 Architecture Selection
可视化一个训练过的模型不仅可以提供了对它操作的深入理解,也可以在第一时间用于选择好的架构。通过可视化Krizhevsky等人的体系结构的第一层和第二层(图5(a)&©),各种问题是显而易见的。第一层滤波器混合了极高和极低频率的信息,覆盖的中频很少。此外,第二层可视化显示了由第一层卷积中使用的大步长4造成的混叠伪影(aliasing artifacts)。为了解决这些问题,我们(i)将1层滤波器的大小从11x11减小到7x7, (ii)使卷积的步长由4变为2。这种新的架构在第一层和第二层特征中保留了更多的信息,如图5(b)&(d)所示。更重要的是,它还改进了如5.1节所示的分类性能。

图5:(a):没有特征尺度裁剪的第一层特征。请注意,有一个特性占主导地位。(a):Krizhevsky等人[18]的第一层特征。(b):我们的第一层功能。更小的步长(2vs4)和过滤器大小(7x7vs11x11)导致更明显的特征和更少的死特征。©:Krizhevsky等人[18]对第二层特征的可视化。(d):我们的第二层功能的可视化。这些是干净的,没有(d)中可见的混叠伪影。
4.2 Occlusion Sensitivity
对于图像分类方法,一个自然的问题是,模型是真正地确定了图像中对象的位置,还是仅仅使用了周围的环境。图6试图回答这个问题,系统地用一个灰色正方形遮挡输入图像的不同部分,并监控分类器的输出。示例清楚地表明,模型正在场景中定位对象,因为当对象被遮挡时,正确类的概率显著下降。图6还显示了顶层卷积层最强的特征图的可视化,以及该图中(空间位置的总和)的激活性作为遮挡点位置的函数。当遮挡器覆盖了在可视化中出现的图像区域时,我们在特征图中看到了激活的强烈下降。这表明可视化真正符合刺激该特征图的图像结构,从而验证了图4和图2中所示的其他可视化。

图6:三个测试例子,我们系统地用一个灰色的正方形(第一列)覆盖场景的不同部分,看看顶部(第5层)的特征如何映射(b&c),分类器输出如何(d&e)变化。(b):对于灰度图的每个位置,我们在第五层某个特征图中记录总激活量(在未遮挡图像中响应最强的一个)。©:将此特征图投射到输入图像(黑色方块)的可视化,以及此映射从其他图像获得的可视化。第一行的例子显示了最强的特征是狗的脸。当它被掩盖时,特征图中的激活减少((b)中的蓝色区域)。(d):一个正确概率的映射,作为灰色方块位置的函数。当狗的脸被遮挡住时,博美犬被发现的几率会显著下降。(e):最可能的标签作为遮挡位置的函数。例如,在第一排,大多数位置它是博美犬,但如果狗的被遮挡,但不是球,那么它预测网球。在第二个例子中,汽车上的文本是第5层中最强的特征,但是分类器对轮子最敏感。第三个示例包含多个对象。第5层最强的特征是提取人脸,但分类器对dog敏感((d)中的蓝色区域),因为它使用多个特征映射。
5. Experiments
5.1 ImageNet 2012
该数据集由1.3M/50k/100k的训练/验证/测试示例组成,超过1000个类别。表1显示了我们在这个数据集的结果。

*表1:ImageNet 2012/2013分类错误率。表示在ImageNet 2011和2012训练集上训练的模型。
使用Krizhevsky等人的[18]中指定的精确架构,我们试图在验证集上复制他们的结果。我们在ImageNet 2012验证集上的误差率和他们报告的结果相差不到0.1%。
接下来,我们通过4.1节中概述的架构更改来分析模型的性能(在层1中有7个过滤器,在层1和层2中卷积stride为1)。如图3所示,该模型显著优于Krizhevsky等人的[18]架构,其单一模型结果低1.7% (test top-5)。当我们组合多个模型时,我们得到了14.8%的测试误差,提高了1.6%。这个结果与Howard[15]的数据扩充方法产生的结果很接近,它可以很容易地与我们的体系结构相结合。然而,我们的模型离2013年Imagenet分类竞赛的冠军还有一段距离[28]。
Varying ImageNet Model Sizes: 在表2中,我们首先讨论Krizhevsky等人的[18]架构,方法是调整层的大小,或者完全删除它们。在每种情况下,模型都是使用修改后的体系结构从零开始训练的。删除完全连接的层(6,7)只会略微增加错误(在下面的示例中,我们将参考top-5验证错误)。这令人惊讶,因为它们包含了大部分的模型参数。去掉两个中间的卷积层对错误率的影响也相对较小。然而,去掉中间的卷积层和全连接层后,得到的模型只有4层,其性能显著下降。这表明模型的整体深度对于获得良好的性能是很重要的。然后我们修改模型,如图3所示。改变全连接层的大小对性能影响不大(Krizhevsky等人的模型[18]也是如此)。然而,增加中间卷积层的大小在性能上得到了有益的提高。但增加这些,同时也扩大了完全连接层,导致过拟合。

表2:ImageNet 2012对Krizhevsky等人的模型和我们的模型在不同架构下的分类错误率(见图3)
5.2 Feature Generalization
上面的实验表明了我们的ImageNet模型的卷积部分在获得最新性能方面的重要性。这可以从图2的可视化中得到支持,图2显示了在卷积层中学习到的复杂不变性。我们现在探索这些特征提取层的能力,以推广到其他数据集,即Caltech-101 [9], Caltech-256[11]和PASCAL VOC 2012。为此,我们保持imagenet训练的模型的1-7层不变,并使用新数据集的训练图像在上层训练一个新的softmax分类器(用于适当数量的类)。由于softmax包含的参数相对较少,因此可以从相对较少的示例中快速训练它,就像某些数据集的情况一样。
实验将我们从ImageNet获得的特征表示与其他方法使用的手工特征进行了比较。在我们的方法和现有的方法中,Caltech/PASCAL训练数据仅用于训练分类器。由于它们具有相似的复杂度(我们:softmax,其他的:linear SVM),因此特征表示对性能至关重要。需要注意的是,这两种表示都是使用Caltech和PASCAL训练集以外的图像构建的。例如,通过对行人数据集的系统实验确定了HOG描述符中的超参数[5]。
我们还尝试了另一种从头开始训练模型的策略,即将图层1-7重置为随机值,并在PASCAL/Caltech数据集的训练图像上训练它们和softmax。
一个复杂的问题是一些Caltech数据集有一些图像也在ImageNet的训练数据中。使用相关归一化,我们识别出这几幅重叠的图像,并将它们从我们的Imagenet训练集中移除,然后重新训练我们的Imagenet模型,从而避免了训练/测试污染的可能性。
Caltech-101: 我们遵循[9]的程序,(从每个类最多50张图片的数据集中)每个类随机选择15或30张图像进行训练和测试,表3报告了每个类的平均准确率,使用5个训练/测试折叠。当每类包含30张图片时,训练时间为17分钟。预训练的模型(30张图像/类别)以2.2%的优势击败了最佳报告结果[3]。我们的结果与Donahue等人最近发表的[7]的结果一致,他们获得了86.1%的准确率(30 imgs/class)。然而,从零开始训练的convnet模型效果很差,仅达到46.5%,这表明在如此小的数据集上训练一个大型convnet是不可能的。

Caltech-256: 我们按照[11]的步骤,每个类选择15、30、45或60个训练图像,在表4中报告每个类的平均准确率。我们的imagenet -pretrained模型以显著的优势击败了Bo等人[3]获得的当前最先进的结果:74.2% vs 55.2%(60张训练图像/类).然而,和Caltech-101一样,从头开始训练的模型表现很差。在图7中,我们探讨了“one-shot learning”[9]的机制。在我们的预训练模型中,只需要6张Caltech-256训练图像就可以击败用10倍的图像的领先方法。这显示了ImageNet特征提取器的强大功能。


图7:Caltech-256分类性能随着每个类的训练图像数量的变化而变化。使用我们预训练的特征提取器,每个类只使用6个训练示例,我们超过了Bo等人的最佳报告结果。
PASCAL 2012: 我们使用标准的训练和验证图像在imagenet预训练的convnet顶层训练一个20-way softmax。这并不理想,因为PASCAL图像可以包含多个对象,而我们的模型仅为每个图像提供一个排他的预测。表5显示了测试集结果与领先的方法的比较:该比赛中的第二名以及来自Oquab等人(他们使用了一个更合适的分类器)的当前工作。Pascal和ImageNet的图像在本质上有很大的不同,前者是完全不同于后者的完整场景。这也许能解释为什么我们的平均性能比竞赛中的佼佼者[27]的低3.2%,不过我们在5个类别上(有时以很大的优势)击败了他们。

5.3 Feature Analysis
我们探索了我们的imagenet预训练模型的每一层的特征有多大区别。我们通过改变从ImageNet模型中保留的层数来做到这一点,并在顶层放置一个线性SVM或softmax分类器。表6显示在Caltech-101和Caltech-256上的结果。对于这两个数据集,我们可以看到一个稳定的改进,因为我们提升了模型,通过使用所有层获得最佳结果。这支持这样一个假设:随着特性层次结构变得更深入,它们将学习到越来越强大的特性。

表6:在我们的imagenet预训练的卷积神经网络中,分析每一层特征图所包含的鉴别信息。我们从卷积网络的不同层(如括号所示)的特征训练一个线性支持向量机或softmax。更高的层次通常产生更多的区别性特征。
6. Disscussion
我们以多种方式探索了用于图像分类的大型卷积神经网络模型。首先,我们提出了一种新颖的方法来可视化模型中的激活。这表明这些特性不是随机的、不可解释的模式。相反,它们显示出许多直观上令人满意的特性,如构成性、增加的不变性和随着层次的上升而产生的类型鉴别力。我们还展示了如何使用这些可视化来识别模型中的问题,从而获得更好的结果,例如改进Krizhevsky等人的[18]在ImageNet 2012中令人印象深刻的结果。然后,我们通过一系列的遮挡实验证明,该模型经过了分类训练后,对图像中的局部结构高度敏感,而不只是使用广泛的场景上下文。对模型的消融研究表明,网络的最小深度(而不是任何单独的部分)对模型的性能至关重要。
最后,我们展示了ImageNet预训练模型如何能很好地推广到其他数据集。对于Caltech-101和Caltech-256,数据集足够相似,因此我们可以击败最好的报告结果,在后者上以较大优势击败。我们模型在PASCAL数据及上的泛化性能不佳,可能是因为数据集间的差异[25]。尽管如此它仍在最佳报告结果的3.2%以内,且没有对任务进行调优。例如,使用了一个不同的损失函数,允许每个图像有多个对象,那么我们的性能可能会提高。这自然也会使网络能够处理对象检测。
