1 简介
本文依据《Cascade R-CNN: Delving into High Quality Object Detection》翻译总结。Cascade R-CNN探究高质量物体检测。
物体检测有两种方法,一种是单步的,像YOLO、SSD是单步物体识别模型。还有一种是两步的,如R-CNN系列。
对于R-CNN物体检测方法,分为两步,第一步是proposal检测者(detector),产生假设(hypothesis)/box,第二步是region-wise检测者(detector)/分类器。
其中,IoU(intersection over union)阈值用来区分正的或负的box。采用0.5阈值的话,通常会产生噪声检测。但是如果增加阈值,又倾向于降低检测的能力,有两个原因吧,一是因为指数级别消失的正样本导致训练中的过拟合,二是预测时IoU(region-wise检测者对于该IoU是最优的)与输入假设间的不匹配。
如下图a,阈值u=0.5时会检测出来多余的box。但这些多余的box也许也富含丰富的信息。
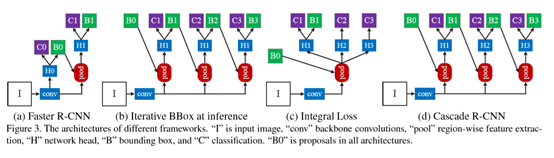
一个单独的region-wise检测者仅在一个单独的质量水平上是最优的。高质量的region-wise检测者仅仅对高质量的假设hypothesis是最优的,当它们在其他质量水平上的假设hypothesis进行工作时,其可能是次优的。如下图c、d,0.5阈值的region-wise检测者(detector)对低IoU输入有较好的检测能力;0.7阈值的region-wise检测者(detector)对高IoU输入有较好的检测能力

Cascade R-CNN就是为了克服上面问题提出的,它包括一系列递增IoU阈值的检测者(detector)。
2 物体检测
本文主要是扩展两步检测模型Fast R-CNN。如下图,H0是proposal 子网络,产生检测假设hypothesis,即object proposal。H1是第二步,对第一步的假设hypothesis进行处理,是对region感兴趣的子网络。最后的C、B分别是分类分数(classification score)、bounding box。
2.1 Bounding box 回归

避免受尺度等影响,经常换成距离向量。

因为该损失的值较分类损失会很小,所以距离向量通常用均值和方差归一化。
2.2 分类

2.3 检测质量
如果IoU高于阈值,样本才会被考虑为分类的样本。所以一个假设x的分类标签是u的函数。如下:
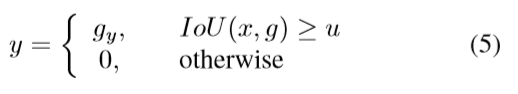
g_y表示ground truth object g的分类标签。
IoU的阈值u决定着检测者的质量。当u值较高时,正的样例中就包含很少的background,但它是很难来拥有足够的正训练样例。当u值较低时,拥有丰富多样的训练样例,但训练检测者会对拒绝错误的正样例不敏感
一种优化:积分损失integral loss
将各种不同质量水平的损失整合在一起,像积分损失。但这种方法只获得了一点点改进。因为不同损失要在不同数量的正样例上操作。

一种优化:迭代bbox
这种优化也只是获得了微小的改进。因为不同水平上的regressor f是不同的,如果用相同f不会达到最优。
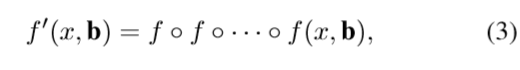
3 Cascade R-CNN
3.1 级联的regressor f
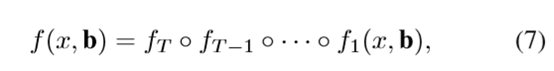
3.2 级联的检测:

4.实验结果
4.1迭代(iterative)bbox、integral loss结果
如下图a,迭代(iterative)bbox效果不如cascade r-cnn;如下图b,integral loss 并没有比u=0.6好多少。


4.2 Cascade stage数量
可以看到采用3个stage就很好,如果4个,AP下降了。

4.2 Cascade R-CNN结果
可以看到比faster R-CNN和mask R-CNN效果好。
