算法背景
论文全称:Cascade R-CNN: Delving into High Quality Object Detection
论文链接:https://arxiv.org/abs/1712.00726
论文时间:2017.12.3
本文是在R-CNN算法上的拓展,针对目标检测问题,我们利用IoU(intersection over union)来定于正样本与负样本,IoU的阈值的定义是非常重要的。IoU阈值太低,eg.0.5,会产生很多带有噪声的样本。
问题
但随着阈值的升高也会导致检测表现下降:
- IoU阈值太高,会导致正样本的数量太少,从而导致过拟合(overfit)。正样本数量会呈指数下降。
- 训练与推断使用不一样的阈值会导致不匹配现象。
解决方案
本文提出了一个多阶段的目标检测模型。核心就是利用不断提高的阈值,在保证样本数不减少的情况下训练出高质量的检测器,通过级联检测网络来达到由于预测结果的目的。优化的假设的重采样确保所有的检测器都有一个相当尺寸的正样本集,从而减少过拟合问题。
算法介绍
目标检测问题可以被分为分类与定位两个复杂问题,定位问题由于近似误分类为正样本( “close” false positives)问题而变得难以解决。这些边界框“close but not correct”。
现阶段的提取候选区域的目标检测算法都是两阶段的R-CNN,这样就把检测算法的框架分为分类与定位两个分支。
阈值u = 0.5时,正样本有许多噪声,检测结果不准确。因此,我们在 IoU ≥ 0.5 上做实验。
quality of an hypothesis :IoU with the ground truth
quality of the detector :the IoU threshold u used to train it

- 根据图c可以看出,每一个边界框回归在输入的IoU值在用于训练检测器的IoU阈值的附近表现的最好,在超过训练的IoU阈值之后就会导致过拟合问题。
- 根据图d可以看出,对于低IoU输入示例,u = 0.5的检测器优于u =
0.6的检测器,在较高的IoU水平下表现不佳,在单个IoU级别优化的检测器在其他级别上不一定是最佳的。
这些观察结果表明,更高质量的检测需要检测器与其处理的假设之间更接近的质量匹配。 一般而言,如果提供高质量的候选区,探测器只能具有高质量。
算法结构
在faster-RCNN的两阶段的结构上进行了拓展,
第一阶段是进行候选区域提取的子网络(H0),应用于整张图片。
第二个阶段进行RoI检测的子网络(H1),最后会有一个分类分数(C),边界框(B)。

(d)cascade-R-CNN中的检测模型是基于前面一个阶段的输出进行训练,而不是像(b)一样3个检测模型都是基于最初始的数据进行训练。对输出bbox的标签界定采取不同的IOU阈值,因为当IOU较高时,虽然预测得到bbox很准确,但是也会丢失一些bbox。
(d)cascade-R-CNN中是迭代式的bbox回归,前一个检测模型回归得到的bbox坐标初始化下一个检测模型的bbox,然后继续回归
边界框回归
与fast-RCNN相同,使用L1损失函数,在此我们采用一个回归方程f(x, b):
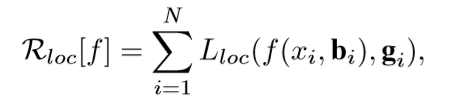
对于回归方程,我们采用迭代的方法:
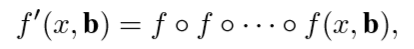
- 开始采用阈值为u=0.5的阈值,然后将输出结果作为下一次的输入,但当u>0.85时定位准确度会下降。
- 每次迭代后,边界框的分布都会发生显着变化。虽然回归量对于初始分布是最佳的,但在此之后它可能是非常不理想的。每一层输入的BBox都要优化,输入上一次生成的BBox。

第一行横纵轴分别是回归目标中的box的x方向和y方向偏移量;第二行横纵轴分别是回归目标中的box的宽、高偏差量。从第一阶段到第三阶段,proposal已经发生了很大变化,很多噪声经过回归也提高了IoU值(图中的红点),这些红点其实属于outliers,如果不提高阈值来去掉它们,就会引入大量噪声干扰,对结果很不利。所以需要重新选择IoU阈值,是一个resample的过程。
分类
分类损失函数使用交叉熵损失函数。
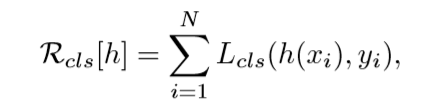
检测质量
推测标签:
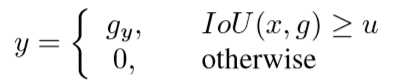

1st stage大于0.5的,到2nd stage大于0.6的,到3rd stage大于0.7的,在这一个过程中proposal的样本数量确实没有特别大的改变,甚至还有稍许提升。
- 迭代BBOX是用于改进边界框的后处理过程,而级联回归是一种重采样过程,它改变了不同阶段要处理的假设的分布。
- 由于它既用于训练又用于推理,因此训练和推理分布之间没有差异。
- cascaded重采样后的每个检测器,都对重采样后的样本是最优的,没有mismatch问题。
级联损失函数
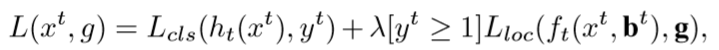
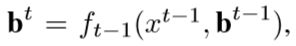
g是x^t对应的真值,
λ=1是折中系数,
[·]指示函数,
yt is the label of xt given ut by (5).
实验
总之,Cascade R-CNN有四个阶段,一个RPN和三个检测U={0.5,0.6,0.7},重采样是通过简单地使用前一阶段的回归输出来实现的,除标准水平图像翻转外,不使用数据增强。推理是在单一的图像尺度上进行的,没有其他操作。