论文信息
Zhaowei Cai, Nuno Vasconcelos. Cascade R-CNN: Delving into High Quality Object Detection. CVPR 2018.
前言
或是说前言加摘要.
当使用一个较低的IOU阈值训练object detector, 通常会导致noisy detection. 当提高阈值后发现性能会有所提升. 这主要可能是又两个原因:
- 当提升阈值之后正样本会"指数式地"减少.
- 已经优化的模型所适应的IOU和输入的proposal不匹配.
本文提出的Cascade R-CNN主要就是为了解决此问题.
它是由一系列逐级递增IOU的detector训练并顺序组合得到的. 要指出每一阶段都输出都分布地比较好, 这样就方便顺序进行下一阶段. 对这些逐级递增地proposal(原文称作hypotheses, 下同)resampling保证positive set的尺寸都相等, 这样能缓解过拟合问题(可能是因为逐级提升的缘故, 因此可以使用一些比较差的数据, 这样就扩充了positive set从而对过拟合缓解).
Introduction
R-CNN等模型常使用IOU阈值0.5, 这样会对positives的要求太过于loose, 着就会导致产生太多不达标的proposal(原文说法是noise bbox), 如图, 图中比较了0.5和0.7的差别:
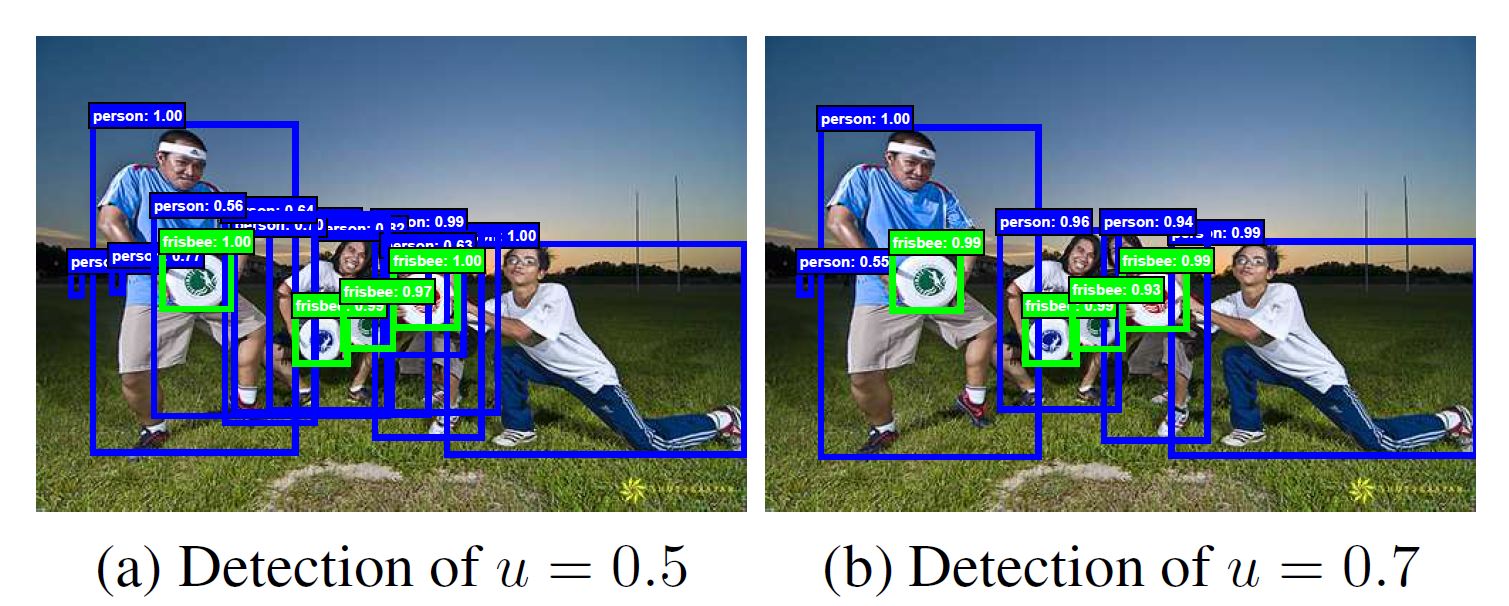
从图中我们可以很容易看出左图比右图多了很多bbox, 且多的bbox大多无意义.
假设大多数人类能在IOU大于0.5的情况下能够比较容易地分辨出那些本不含物体而被机器判断为有物体(false positive, FP for short)的example. 对于那些小于0.5的内容丰富多样example来说, 人和机器都很难高效地分出那些FP example.
本文的工作就是首先生成(原文用define)某个IOU的一些列proposal, 其后对和其IOU对应的detector进行训练. 这样似乎就把作者提出的两个问题都解决了 - 解决学习高质量object detectors的困难(此前的detectors输出常包含很多FP样本).
本文解决的重要思想是每一个单独的detector只对一个单独的IOU(原文称quality level)进行优化. 此前有类似的工作, 但本文的思想与其不同, 此前是对FP rate优化, 本文是对一个给定的IOU阈值优化.
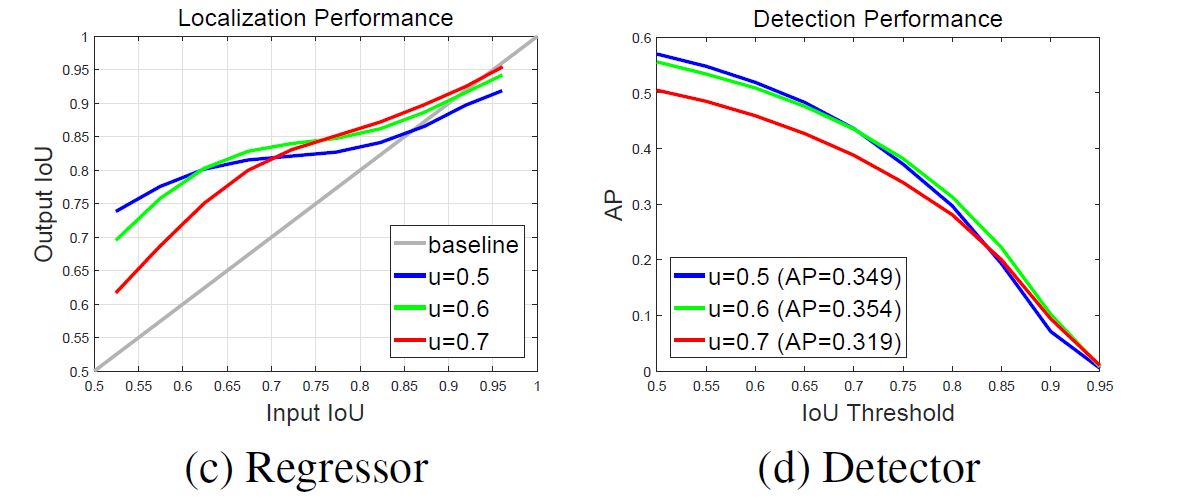
从这两张图来看, 总体都变现出高IOU预设在输入高IOU样本时输出较好, 低IOU预设在输入低IOU样本时输出较好. 也就是说预设值与输入值匹配的情况下表现最好.
然而, 要生成一个高质量的detector, 光是简单地提高阈值也没什么用, 右图中也可以看出, 提高阈值输出还是不断下降, 作者认为这样的原因可能是因为提高阈值之后会使positive samples太少. 本来神经网络就很脆弱, 这么少的样本很容易造成过拟合. 另一个问题是刚才提到的预设与输入IOU阈值不匹配的问题.
Object Detection
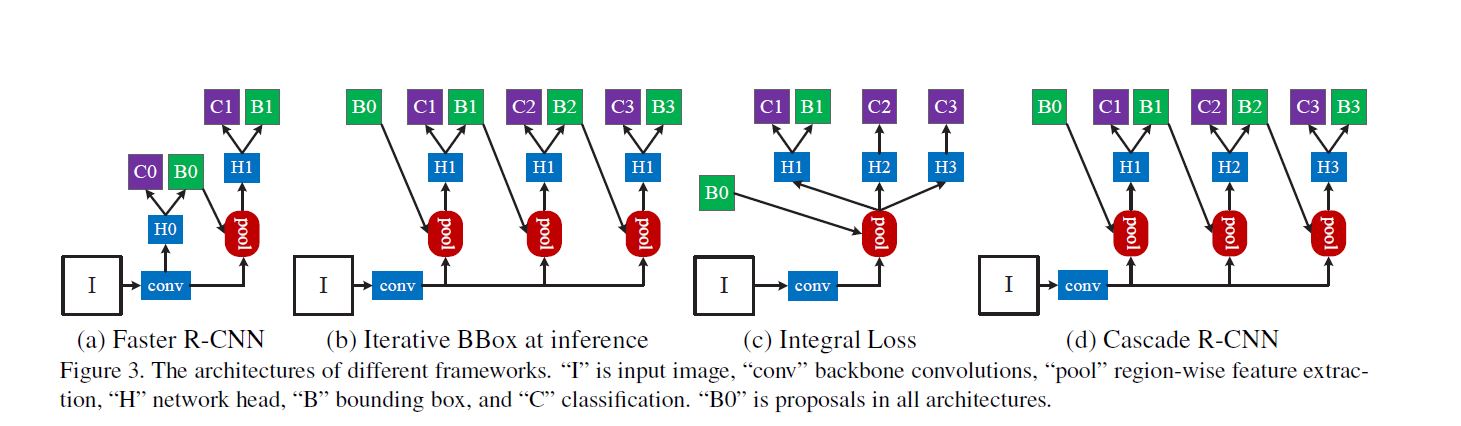
作者首先给了一张当时比较流行的方法示意图, 此图后文用到多次, 我们称之为结构图, 各大写字母含义图中也给出解释:
Bounding Box Regression
我们知道bbox对于所框选的图片块\(x\)通常由四个坐标构成: \(\b = (b_x, b_y, b_w, b_h)\), bbox regression就是将这个预测的bbox对实际bbox \(g\)进行regress, 这个过程借助regressor \(f(x, b)\)进行, 因此最终就是优化这样一个函数:
\[ R_{loc}[f] = \sum\limits_{i = 1}^{N}L_{loc}(f(x_i, b_i), g_i) \]
其中\(L_{loc}\)在R-CNN是一个\(L_2\) loss, 而在Fast R-CNN, 是一个\(L_1\) loss. 为了使预测尽可能与实际接近, \(L_{loc}\)实际操作一个距离向量:
\[ \Delta = (\delta_x, \delta_y, \delta_w, \delta_h) \]
其中:
\[ \delta_x = (g_x - b_x) / b_w\\ \delta_y = (g_y - b_y) / b_h\\ \delta_w = log(g_w / b_w)\\ \delta_h = log(g_h / b_h) \]
想要指出的是, bbox regression中一般b差异不大, 那么就会使\(L_{loc}\)很小, 为了提升他的effectiveness, 那么一般会使其归一化\(~N(0, 1)\), 也就是\(\delta_x' = (\delta_x - \mu) / \sigma_x\).
此前有工作argue单独用一次regression step of f定位精度不够, 因此他们就重复进行f regress:
\[ f'(x, b) = f \circ f \circ \cdots \circ f(x, b) \]
即所谓迭代bbox regression(iterative bounding box regression), 此方法对应上图中(b), 但此方法还是有两个问题:
regressor f是在0.5的阈值训练, 对于更高阈值的proposal, regressor欠优化, 对于IOU大于0.85的proposal抑制尤为明显.
每次迭代之后的分布都在明显变化, 很可能初始分布较好, 但经过几次迭代之后反而表现更差了. 下图给出一例.
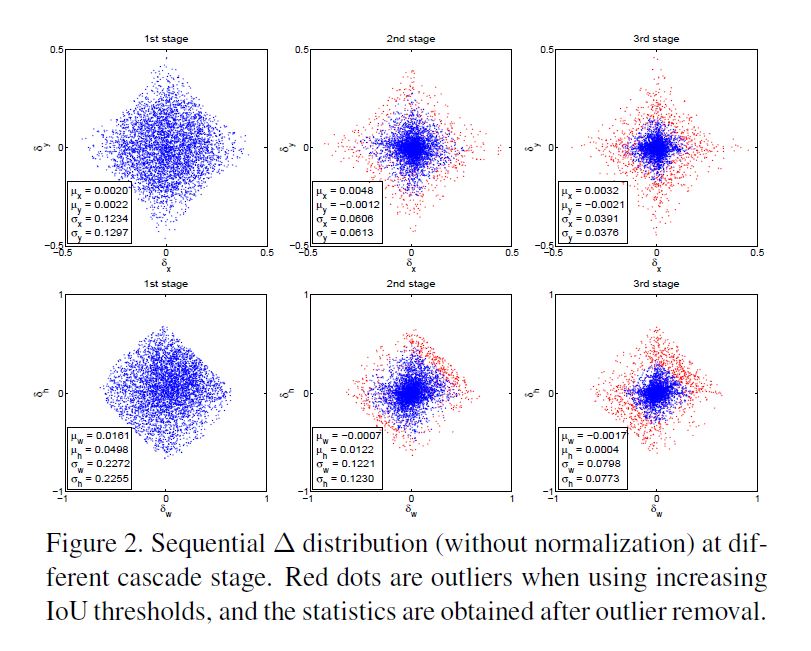
正因为其特性, 此方法需要一些后期处理. 此方法因此也是不稳定的, 通常迭代超过两次以后基本再无太大变化.
Classification
和先前的方法基本不变, 分类时对于proposal分成\(M + 1\)类, 其中第0类是bg, 预测结果\(h_k(x) = p(y = k | x)\), 其中\(y\)是指被预测对象类别, 那么最终得到被优化的函数:
\[ R_{cls}[h] = \sum\limits_{i = 1}^NL_{cls}(h(x_i), y_i) \]
这里\(l_{cls}\)是经典交叉熵损失.
Detection Quality
和以前一样, 当proposal IOU大于某个阈值, 则预测label y, 否则为bg(label y = 0). IOU设置高或低的优缺点此前已经讲过, 此前有通过结构图中(c)的做法对多level的输出计算损失并优化:
\[ L_{cls}(h(x), y) = \sum\limits_{u \in U}L_{cls}(h_u(x), y_u) \]
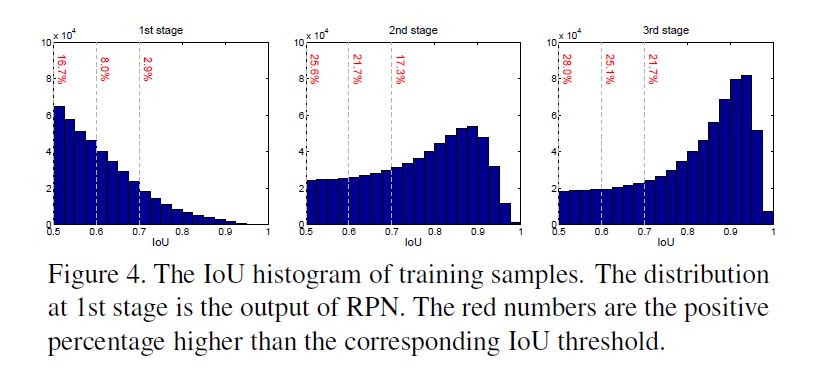
U就是多IOU阈值. 因此所有classifiers在推理过程中一起使用, 但有个关键问题是不同classifier接收的positives的数量不同! 在下图中的左图就是这种情况, 首先高IOU样本数量太少, 很容易过拟合; 其次高预设IOU classifier又不得不处理众多不适宜的第IOU样本. 另外这张图也请牢记, 我们称之为分布图.
Cascade R-CNN
结构如结构图(d)所示.
Cascaded Bounding Box Regression
既然单个classifier很难适应多IOU, 那么作者就设计了顺序的多个classifier, 与iterative bounding box regression相对应, 本文的结构:
\[ f'(x, b) = f_T \circ f_{T - 1} \circ \cdots \circ f_1(x, b) \]
这里每个regressor\(f_t\)都是预优化过的,
它与iterative bounding box regression(IBBR for short)的不同有以下几点:
- IBBR是对同一个网络重复迭代优化, cascaded regression是通过resample使每一级输出都能被下级使用.
- cascaded regressor是既用于训练又用于推理, 那么训练集和推理集就不会有不匹配的情况了.
- 每一级输出需要resample, 其后对每一级都会进行优化而不是向IBBR一样只是最终相当于对输入优化.
我想解释一下, 为什么输入为低IOU最后还会优出适应较高IOU的regressor, 这利用到全文第二张图的左图, 我再贴出来一边便于观察:
左图中我们可以看出输出在大多数情况都是好于输入的, 那么我们逐级递增地设置regressor, 最终输出的也就是单一regressor几乎不可能达到的高IOU.
Cascade Detection
在分布图中我们可以发现, 每一阶段处理之后分布重心都会向高IOU移动,这样有两个好处:
- 不容易过拟合.
- detector就可以对高IOU example训练, 而减轻以前的不匹配问题.
在每个阶段\(t\), R-CNN都要对classifier\(h_t\)和regressor\(f_t\)在阈值\(u^t, u^t > u^{t - 1}\)的状态下优化, loss为:
\[ L(x^t, g) = L_{cls}(h_t(x^t), y^t) + \lambda[y^t \geq 1]L_{loc}(f_t(x^t, b^t), g) \]
其中\(b^t = f_{t - 1}(x^{t -1}, b^{t - 1})\), g是\(x^t\)的ground truth. \(\lambda\)是调节参数. \([y^t \geq 1]\)是指只有不是bg时才计算\(L_{loc}\).
Experimental Results
这里只使用了水平翻转, 在没有使用其他trick.
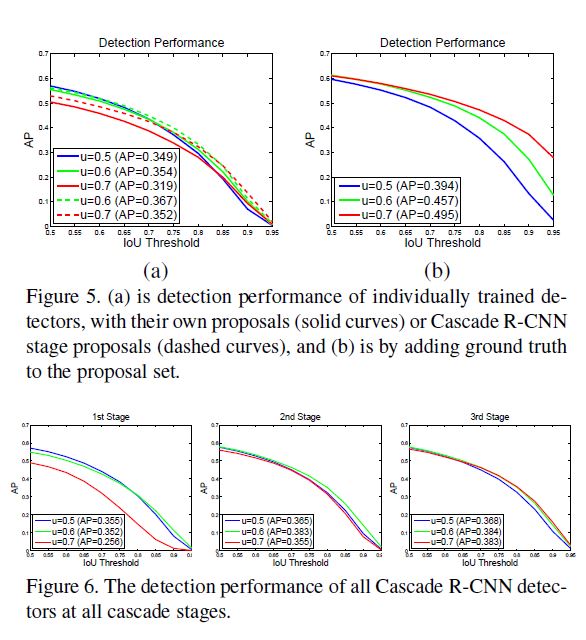
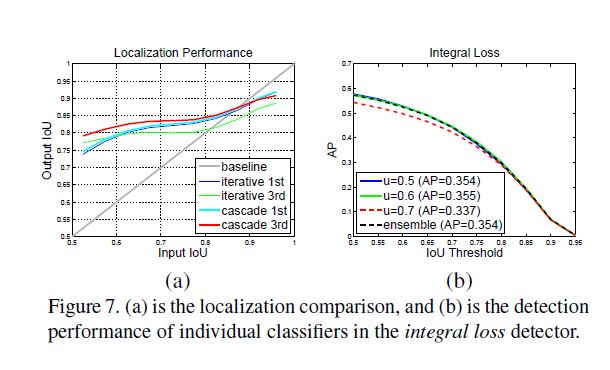
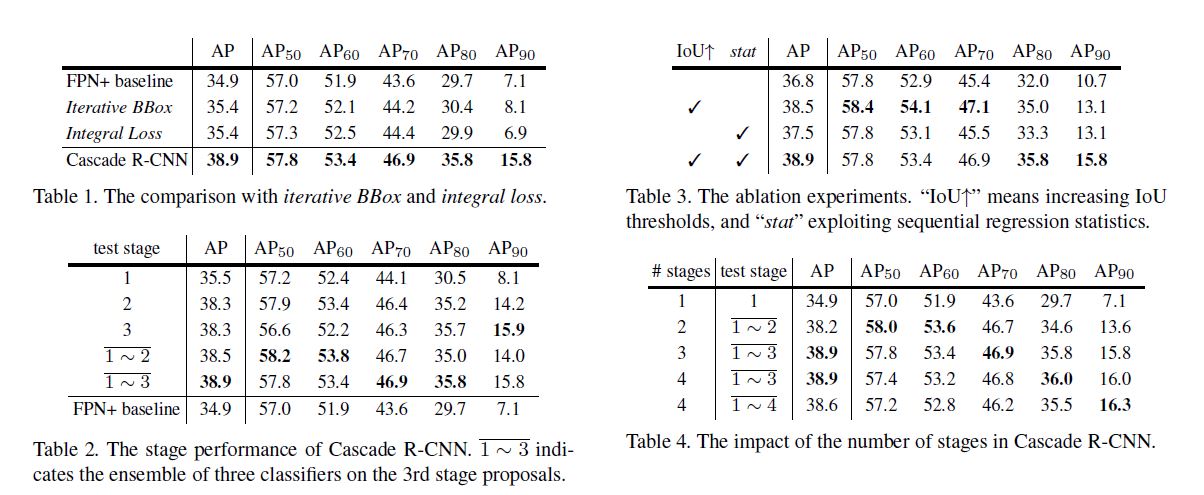
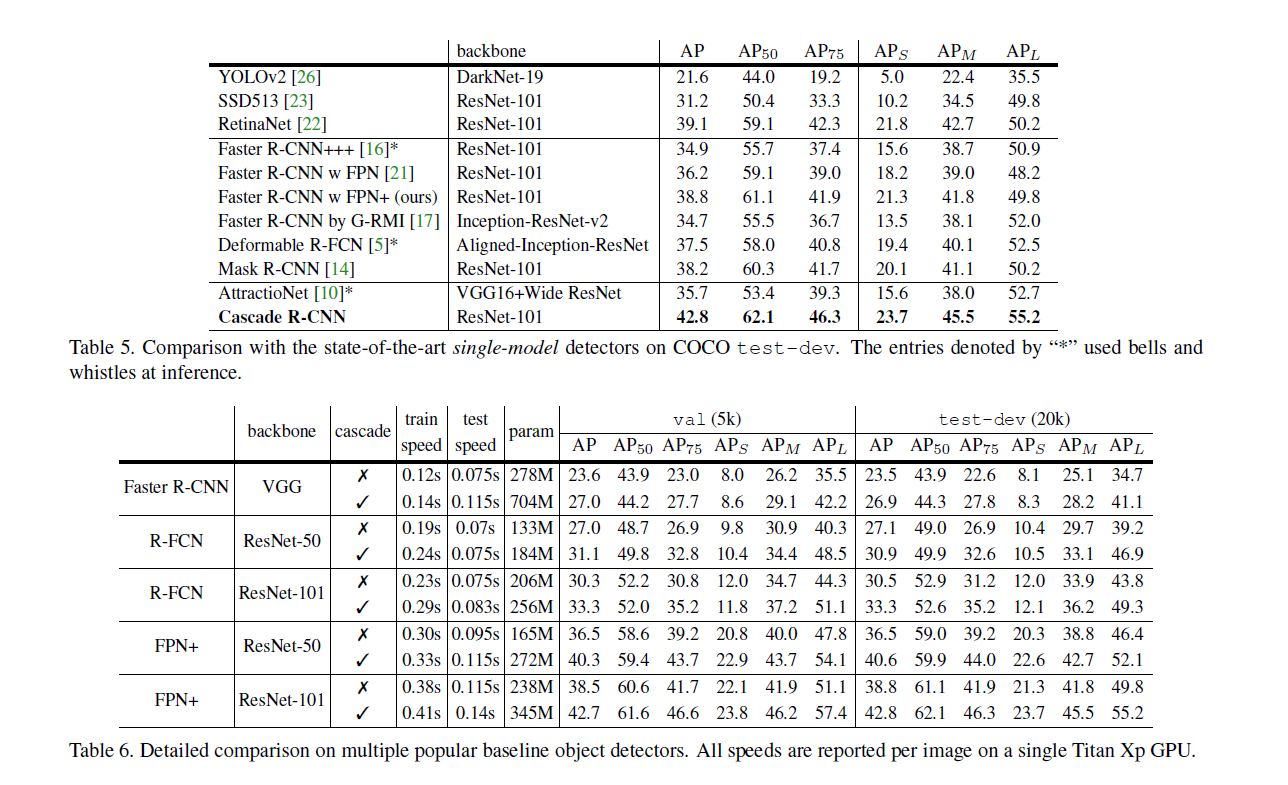
以下与各模型对比实验, 因为内容都比较直观, 以后可能不会补充对他们的分析.
Conclusion
正如一开始提到的两点问题, 作者在本文也是在尽力解决这些问题:
- 采用多阶段逐步提升IOU, 从而在低IOU样本中获取更多的"高IOU"样本.
- 对于最后一个阶段输出了高IOU样本, 训练classifier从而使其适应高IOU样本, 当其推理时对于高IOU的样本处理表现也更好.