转自:https://zhuanlan.zhihu.com/p/36095768
Cascade R-CNN: Delving into High Quality Object Detection
论文链接:https://arxiv.org/abs/1712.00726
代码链接:https://github.com/zhaoweicai/cascade-rcnn
CVPR2018的文章,最早是在知乎上看到https://zhuanlan.zhihu.com/p/35882192的介绍,大致读了下感觉是非常有趣的工作,想要了解大致的设计思想的可以看这篇文章。
本文主要针对的是检测问题中的IoU阈值选取问题,众所周知,阈值选取越高就越容易得到高质量的样本,但是一味选取高阈值会引发两个问题:
- 样本减少引发的过拟合
- 在train和inference使用不一样的阈值很容易导致mismatch(这一点在下面会有解释)
作者为了解决上述问题就提出了一种muti-stage的architecture,核心就是利用不断提高的阈值,在保证样本数不减少的情况下训练出高质量的检测器。
以下是论文的核心内容和一些实验,当然是按照我自己的理解组织的。
1.思想简介
我们知道,检测问题和分类问题有很大的不同,检测问题通过IoU来判断样本是否是正确的,因此IoU的选取对train和inference的影响都很大,来看作者做的一组实验:
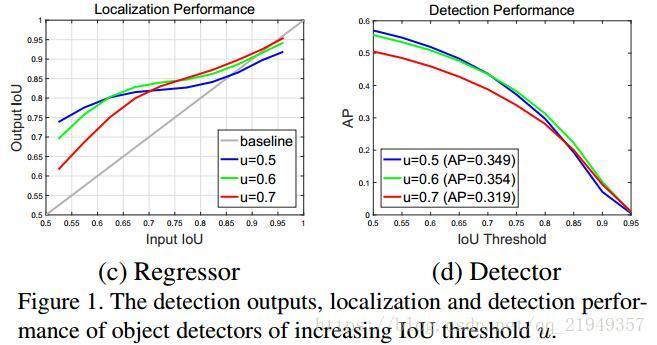
先看左图,横轴的是proposal的IoU,纵轴的是经过box reg得到的新的IoU,不同的线条代表不同阈值训练出来的detector,显然新的IoU越高,说明detector进行回归的性能越好。可以看到在0.55~0.6的范围内阈值为0.5的detector性能最好,在0.6~0.75阈值为0.6的detector性能最佳,而到了0.75之后就是阈值为0.7的detector了……
这就说明了,只有proposal自身的阈值和训练器训练用的阈值较为接近的时候,训练器的性能才最好,如果两个阈值相距比较远,就是我们之前说的mismatch问题了。
从图中我们可以意识到,单一阈值训练出的检测器效果非常有限,以现在最常见的阈值0.5为例,由于所有IoU大于0.5的proposal都会被选中,那么对于IoU0.6~0.95的proposal来说,detector的表现就很差了。那么,我能不能直接选用0.7的高阈值呢?毕竟这样子0.5~0.7的proposal都被排除了,横轴0.7~0.95之间,红色线条的表现似乎不差啊?但是看到右图你就会发现,实际上detector的性能反而是最低的,原因是这样子训练样本大大减少,过拟合问题非常严重。
如何能保证proposal的高质量又不减少训练样本?采用cascade R-CNN stages,用一个stage的输出去训练下一个stage,就是作者给出的答案。留意到左图大部分线条都是在y=x的灰色线条之上的,这就说明某个proposal在经过detector后的IoU几乎必然是增加的,那么再经过一个更大阈值训练的detector,它的IoU就会更好。
举个例子,有三个串联起来的用0.5/0.6/0.7的阈值训练出来的detector,有一个IoU约为0.55的proposal,经过0.5的detector,IoU变为0.75;再经过0.6的detector,IoU变为0.82;再经过0.7的detector,最终IoU变为0.87……比任何一个单独的detector的结果都要好。不仅仅只有IoU改善的好处,因为每经过detector,proposal的IoU都更高,样本质量更好了,那么即使我下一个detector阈值设置得比较高,也不会有太多的样本被刷掉,这样就可以保证样本数量避免过拟合问题。
2.相关工作及一些证明
作者还把他的工作和类似的几种工作做了实验比较,在论文中是分开的,我这里统一列出来方便大家对比。先来看一张图:
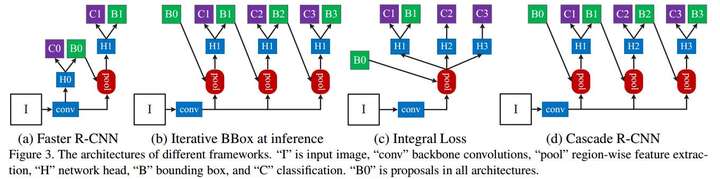
Iterative BBox及对比
这是目前几个非常典型的工作。图(b)的Iterative BBox为了定位准确,采用了级联结构来对Box进行回归,使用的是完全相同的级联结构。但是这样以来,第一个问题:单一阈值0.5是无法对所有proposal取得良好效果的,如第1部分的图所示,proposal经过0.5阈值的detector后IoU都在0.75以上,再使用这一阈值并不明智;第二个,detector会改变样本的分布,这时候再使用同一个结构效果也不好,看下图:
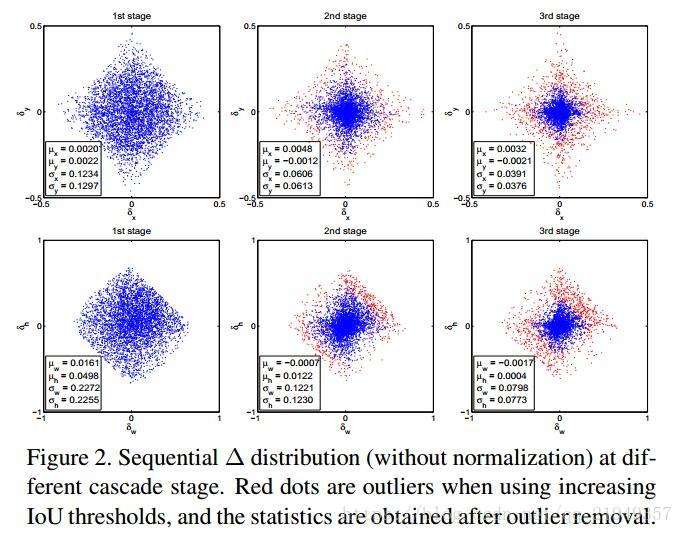
第一行横纵轴分别是回归目标中的box的x方向和y方向偏移量;第二行横纵轴分别是回归目标中的box的宽、高偏差量,由于比较基础这里不贴公式了。我们可以看到,从1st stage到2nd stage,proposal的分布其实已经发生很大变化了,因为很多噪声经过box reg实际上也提高了IoU,2nd和3rd中的那些红色点已经属于outliers,如果不提高阈值来去掉它们,就会引入大量噪声干扰,对结果很不利。从这里也可以看出,阈值的重新选取本质上是一个resample的过程,它保证了样本的质量。
当然,这里会有另一个问题,我们这样子真的不会减少样本数量么?虽然第1部分给了比较直观感性的解释,但是似乎还不够……作者给出了更加详细的实验证明:
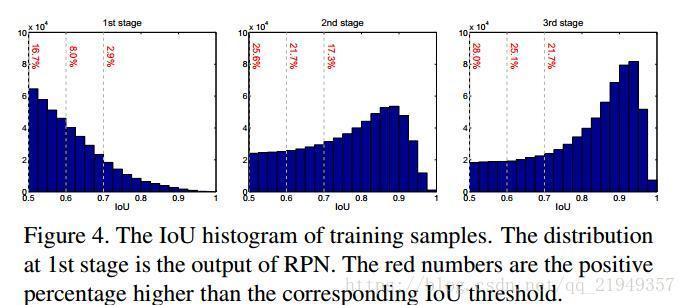
从这张图,我们可以看到,1st stage大于0.5的,到2nd stage大于0.6的,到3rd stage大于0.7的……在这一个过程中proposal的样本数量确实没有特别大的改变,甚至还有稍许提升,和2图结合起来看,应该可以说是非常强有力的证明了。
总结起来,就是:
- cascaded regression不断改变了proposal的分布,并且通过调整阈值的方式重采样
- cascaded在train和inference时都会使用,并没有偏差问题
- cascaded重采样后的每个检测器,都对重采样后的样本是最优的,没有mismatch问题
Iterative Loss
Iterative Loss实际上没有级联结构,从c图可以看出来,它只是使用了不同的阈值来进行分类,然后融合他们的结果进行分类推理,并没有同时进行Box reg。作者认为,从图4中的第一个图可以看出来,当IoU提高的时候,proposal的比重下降非常迅速,这种方法没有从根本上克服overfit问题;另外,这种结构使用了多个高阈值的分类器,训练阈值却只能有一个,必然会导致mismatch问题而影响性能。
3.Cascade R-CNN的实现与结果
Cascade R-CNN的结构图在第2部分的(d)图已经给出了……
最后总结一下,作者最终确定的结构一共是4个stages: 1个RPN+3个检测器(阈值设定分别为0.5/0.6/0.7)……其中RPN的实现想必大家都很清楚了,而后面三个检测器,则按照之前介绍的那样,每个检测器的输入都是上一个检测器进行了边框回归后的结果,实现思路应该类似于Faster RCNN等二阶段检测器的第二阶段。
贴一下结果吧:
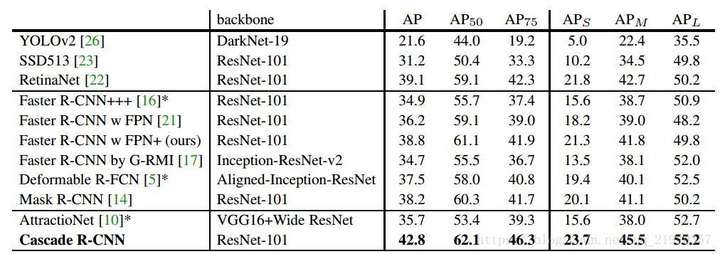
个人认为,这个提升还是相当惊艳的。特别需要说明的一点是,对于目前流行的检测结构来说,特征提取是耗时最多的,因此尽管Cascade R-CNN增加了比较多的参数,但是速度的影响并没有想象中的大,具体可以参考下表:
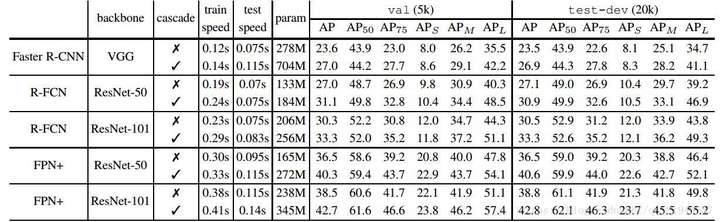
实际上,论文中还有相当多的部分没有提及。这篇文章还做了大量的对比实验,例如通过添加ground truth来提高proposal的质量从而验证mismatch问题;通过添加stages来分析适合的级联阶段数等等;包括一些和第2部分中提到的两种思路的对比等等,可以说是有理有据……再加上不俗的效果和晓畅通俗的语言,还是非常值得阅读的,另外作者的code也已经发布,有兴趣的同学可以前去观摩~
4.总结
其实像我这样的入门者是很难准确说出这篇文章好在哪里的,这里引用Naiyan Wang大神的评论吧:Detection其实并不是一个很合适的分类问题,没有一个明确的离散的正负样本的定义,而是通过IoU来连续定义的。但是IoU这个指标很难通过gradient descent来优化,虽然之前也有一些IoU loss的工作,但是效果并不理想。Cascade RCNN便是一个在这个方向上很好的尝试。