Introduction
Cascade R-CNN的本质是 “ Cascade Regressor ” 。
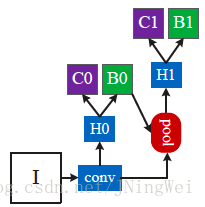
传统的Faster R-CNN结构如下:
在train阶段,其最终的输出结果是通过如下一个简单的IoU阈值判断来决定哪些proposal作为output:
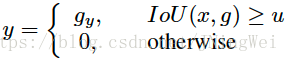
对IoU阈值设置的探索
由于早前VOC只以 作为唯一的性能衡量标准,为了overfit该数据集,算法的IoU阈值在train阶段和inference阶段常被简单地设定为 0.5,而这会导致train阶段对bbox的质量要求过低。
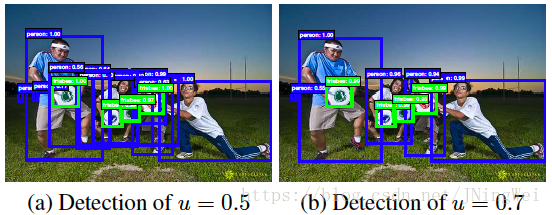
inference阶段,如果IoU阈值设为0.5,最终输出可能如下的左图所示,带有不少错分为object的bbox;如果我们把IoU阈值调高到0.7,如下右图所示,就可以把一堆IoU介于0.5~0.7之间的bbox给过滤掉:
那我们直接在train阶段就把IoU阈值改为0.7,test阶段依然为0.5,不就好了吗?
不行。
原因:
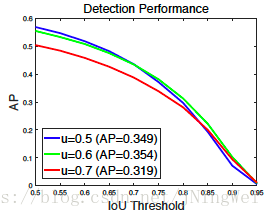
如下图,IoU=0.7训练出来的detector
[红线],在IoU=0.5的输入上定位效果甚至不如IoU=0.5训练出来的detector[蓝线]:
其原因有二:
- train阶段IoU设为0.7会导致positive bbox的数量骤降,导致最终训出的模型overfit。
- inference阶段,RPN丢给regressor的大多是low-quality proposal。单个regressor再强也只能稍微regress一点点location,那么最终的output还是得GG。
那我们train阶段为0.5,只在test阶段把IoU阈值改为0.7呢?
不行。
原因:
- train阶段 和 inference阶段 的 IoU阈值 设置得不一样,反而会影响性能。
那就同时把train阶段和test阶段都改为0.7呢?
还是不行。
原因:
- 自从更大更全的COCO数据集提出来后,评价标准变得“多IoU阈值化”了。在原先的 基础上,又增加了 等等一系列指标。也就是说,不管你怎么改,都会导致某些IoU阈值标准是你在train的阶段无法顾及到的。
对regressor数量的探索
作者发现,假设待输入regressor的bbox为Input,回归后的输出bbox为Output,则经过Output的IoU质量普遍优于Input:
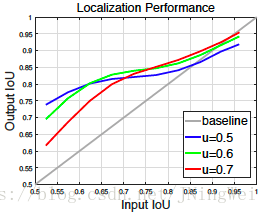
等于证明了:
经过location regression的bbox明显更high-quality。
故而,多次叠加RoI-wise subnet,就等于多regress几次bbox,自然可以获得更high-quality的output bbox,从而刷高COCO测评性能。
那么直接简单地在RoI-wise subnet后面再叠加RoI-wise subnet可以么?
不行。
原因:
因为如果这么做的话,对bbox的回归公式就变成了如下所示:
此时对应的网络结构就会不能很好地挖掘多级regression的作用:
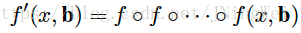
Innovation
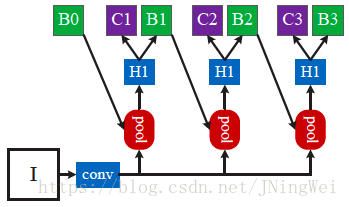
作者的Idea,是设计cascade的bbox regression机制:
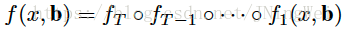
总共有三个RoI-wise subnet相cascade (级联) ,每个RoI-wise network采用不同的IoU阈值。依次为0.5、0.6、0.7。
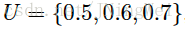
对应的网络结构如下:
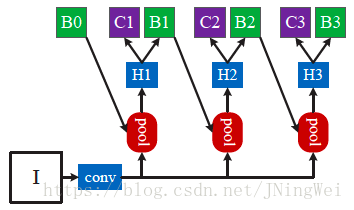
该设计有如下四大优势:
- 实现起来简单;
- 可以end-to-end训练;
- 适用于任何two-stage的检测算法;
- 普遍都能涨点2~4。
Result
经过试验,发现cascade regressor可以逐步过滤非object的bbox,并提升object的bbox质量:
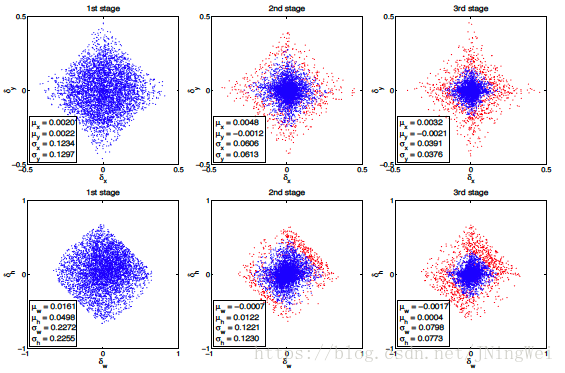
经过三个级联的regressor,可以明显看出最后一个regressor输入的待处理bbox(如下最右边的子图)质量明显高了很多:
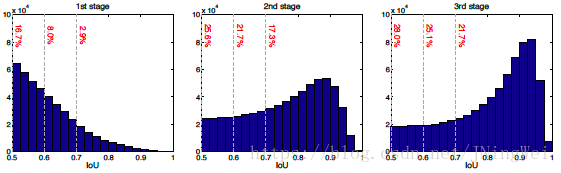
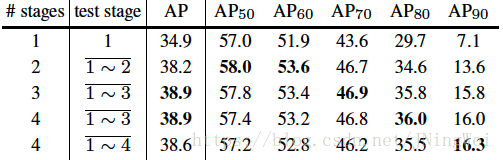
经过实验,发现取三个RoI-wise subnet级联的效果最好:
Thinking
- 如文中引用文献的情况所示,Cascade R-CNN的灵感很大程度上来自作者的细心观察和face-detection惯用的cascade boostrapping (级联引导) 做法的启发。
Faster R-CNN将Detection从4-stage简化到了2-stage,而Cascade R-CNN又将2– stage发展回了4-stage。其实这是一种“螺旋式地上升”吧。
- Cascade R-CNN的根本动机就是:
通过在每个stage调整bbox来获得越来越high-quality的bbox,从而将COCO的一系列metric一锅端。
Note:
如果第一个RoI-wise subnet的输入是300个bbox(有positive也有negative),那么第三个RoI-wise subnet输入的是依然是这300个bbox;
所有proposal(除了那些完全不cover ground truth的)在每一轮regression中都可以提升location质量,更加逼近ground truth。所以最后这些proposal的质量明显越来越高了:
[1] Cascade R-CNN: Delving into High Quality Object Detection