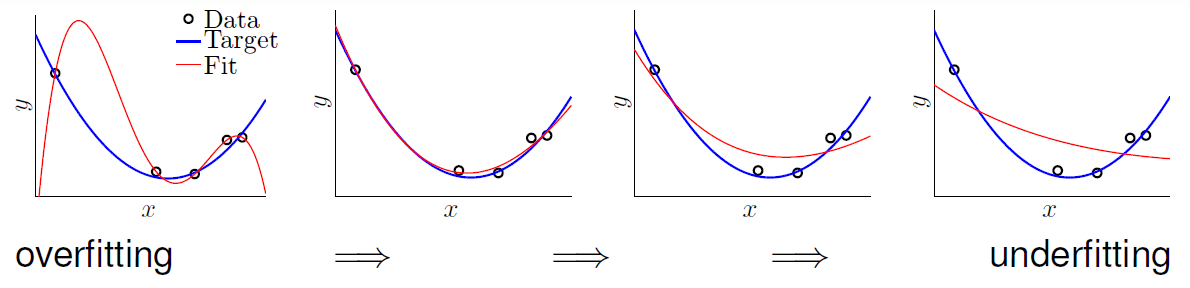
欠拟合(underfitting):
E
in
E_{\text {in}}
E in
E
out
E_{\text {out}}
E out
过拟合(overfitting):
E
in
E_{\text {in}}
E in
E
out
E_{\text {out}}
E out
常见的过拟合原因有:数据量(data size)太少,随机噪声(stochastic noise)太大,目标函数(deterministic noise)太复杂,dvc过高(excessive power)。
示例如下:
一般而言欠拟合很好处理。过拟合却很难解决,比较实用的解决方案有以下五个:
start from simple model(从简单的模型开始)
data cleaning/pruning(数据清理和裁剪)
data hinting(数据提示)
regularization(正则化)
validation(验证)
其中数据清理实际上就是纠正数据错误,而数据裁剪便是删除无用或冗余样本。而数据提示则是数据构造(加入构造样本),以图像处理为例:可以通过移动或旋转(shifting/rotating)已知图像构造虚拟样本数据。
下面介绍两个实用的工具正则化与验证。
正则化的本质是减少无用项的比重,从而减小 $d_{\mathbf{vc}} $ ,进而抑制过拟合。最理想的状态是通过学习使得某些不重要的项的系数为0,但是这是一种 NP-hard 问题,所以降低要求至减小比重。
min
w
∈
R
Q
+
1
E
in
(
w
)
=
1
N
∑
n
=
1
N
(
w
T
z
n
−
y
n
)
2
⏟
(
Z
w
−
y
)
T
(
Z
w
−
y
)
s.t.
∑
q
=
0
Q
w
q
2
⏟
w
T
w
≤
C
\begin{array} { r l } \min _ { \mathbf { w } \in \mathbb { R } ^ { Q + 1 } } & E _ { \text {in } } ( \mathbf { w } ) = \frac { 1 } { N } \underbrace { \sum _ { n = 1 } ^ { N } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } - y _ { n } \right) ^ { 2 } } _ { ( \mathbf { Z } \mathbf { w } - \mathbf { y } ) ^ { T } ( \mathbf { Z } \mathbf { w } - \mathbf { y } ) } \\ \text { s.t. } & \underbrace { \sum _ { q = 0 } ^ { Q } w _ { q } ^ { 2 } } _ { \mathbf { w } ^ { T } \mathbf { w } } \leq C \end{array}
min w ∈ R Q + 1 s.t. E in ( w ) = N 1 ( Z w − y ) T ( Z w − y )
n = 1 ∑ N ( w T z n − y n ) 2 w T w
q = 0 ∑ Q w q 2 ≤ C
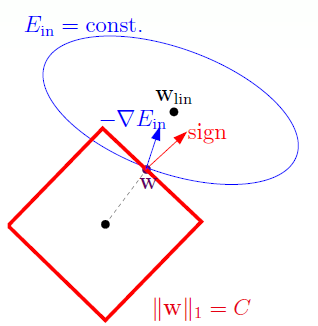
这个限制实际上是将比重系数限制在半径为
C
\sqrt{C}
C
w
R
E
G
\mathbf{w}_{REG}
w R E G
H
(
C
)
H(C)
H ( C )
可见这是一个有条件最优化问题,经典的解法是使用拉格朗日乘数。即找一个拉个朗日乘数(Lagrange multiplier)
λ
>
0
\lambda > 0
λ > 0
w
R
E
G
\mathbf { w } _ { \mathrm { REG } }
w R E G
∇
E
in
(
w
R
E
G
)
+
2
λ
N
∣
w
R
E
G
∣
=
0
\nabla E _ { \text {in } } \left( \mathbf { w } _ { \mathrm { REG } } \right) + \frac { 2 \lambda } { N } \left| \mathbf { w } _ { \mathrm { REG } } \right| = \mathbf { 0 }
∇ E in ( w R E G ) + N 2 λ ∣ w R E G ∣ = 0
当现在有一个球需要向负梯度方向(谷底)滚,但是呢现在有一个限制条件,不能超出半径为
C
\sqrt{C}
C
根据上述拉格朗日乘数方程,可以写出:
∇
E
i
n
(
w
R
E
G
)
+
2
λ
N
w
R
E
G
=
0
2
N
(
Z
T
Z
W
R
E
G
−
Z
T
y
)
+
2
λ
N
W
R
E
G
=
0
\nabla E _ { \mathrm { in } } \left( \mathbf { w } _ { \mathrm { REG } } \right) + \frac { 2 \lambda } { N } \mathbf { w } _ { \mathrm { REG } } = \mathbf { 0 }\\ \frac { 2 } { N } \left( \mathrm { Z } ^ { T } \mathrm { ZW } _ { \mathrm { REG } } - \mathrm { Z } ^ { T } \mathbf { y } \right) + \frac { 2 \lambda } { N } { \mathbf { W } _ { \mathrm { REG } } } = \mathbf { 0 }
∇ E i n ( w R E G ) + N 2 λ w R E G = 0 N 2 ( Z T Z W R E G − Z T y ) + N 2 λ W R E G = 0
w
R
E
G
\mathbf { w } _ { \mathrm { REG }}
w R E G
w
R
E
G
←
(
Z
T
Z
+
λ
I
)
−
1
Z
T
y
\mathbf { w } _ { \mathrm { REG } } \leftarrow \left( \mathrm { Z } ^ { T } \mathrm { Z } + \lambda \mathrm { I } \right) ^ { - 1 } \mathrm { Z } ^ { T } \mathbf { y }
w R E G ← ( Z T Z + λ I ) − 1 Z T y
这个在统计上叫做岭回归(ridge regression)。其中
Z
T
Z
\mathrm { Z } ^ { T } \mathrm { Z }
Z T Z
λ
I
\lambda \mathrm { I }
λ I
实际上上述拉格朗日乘数方程,等同于下面这个优化问题
E
in
(
w
)
+
λ
N
w
T
w
⏞
regularier
⏟
augmented error
E
aug
E _ { \text {in } } ( \mathbf { w } ) + \underbrace{\frac { \lambda } { N } \overbrace { \mathbf { w } ^ { T } \mathbf { w } }^{\text{regularier}}}_{\text{augmented error } E _ { \text {aug } }}
E in ( w ) + augmented error E aug
N λ w T w
regularier
所以将有约束的最优化问题转换为用扩大误差的正则化(regularization with augmented error instead of constrained
E
in
E_{\text{in}}
E in
w
R
E
G
←
argmin
w
E
aug
for given
λ
>
0
or
λ
=
0
\mathbf { w } _ { \mathrm { REG }} \leftarrow \mathop { \text{argmin} }_{\mathbf{w}} E _ { \text {aug } } \text{ for given }\lambda > 0 \text { or } \lambda = 0
w R E G ← argmin w E aug for given λ > 0 or λ = 0
即最小化无约束
E
aug
E _ { \text {aug } }
E aug
E
in
E_{\text{in}}
E in
E
aug
E _ { \text {aug } }
E aug
E
in
E_{\text{in}}
E in
因为该正则化方法有效的减小了无用项权重系数的大小,所以
+
λ
N
w
T
w
+ \frac { \lambda } { N } \mathbf { w } ^ { T } \mathbf { w }
+ N λ w T w
min
w
∈
R
Q
+
1
1
N
∑
n
=
0
N
(
w
T
Φ
(
x
n
)
−
y
n
)
2
+
λ
N
∑
q
=
0
Q
w
q
2
\min _ { \mathbf { w } \in \mathbb { R } ^ { Q + 1 } } \frac { 1 } { N } \sum _ { n = 0 } ^ { N } \left( \mathbf { w } ^ { T } \mathbf { \Phi } \left( x _ { n } \right) - y _ { n } \right) ^ { 2 } + \frac { \lambda } { N } \sum _ { q = 0 } ^ { Q } w _ { q } ^ { 2 }
w ∈ R Q + 1 min N 1 n = 0 ∑ N ( w T Φ ( x n ) − y n ) 2 + N λ q = 0 ∑ Q w q 2
单纯的多项式转换(naïve polynomial transform):
Φ
(
x
)
=
(
1
,
x
,
x
2
,
…
,
x
Q
)
\Phi ( x ) = \left( 1 , x , x ^ { 2 } , \ldots , x ^ { Q } \right)
Φ ( x ) = ( 1 , x , x 2 , … , x Q )
x
n
∈
[
−
1
,
+
1
]
,
x
n
q
x _ { n } \in [ - 1 , + 1 ] , x _ { n } ^ { q }
x n ∈ [ − 1 , + 1 ] , x n q
w
q
\mathbf{w}_q
w q
Φ
(
x
)
=
(
1
,
L
1
(
x
)
,
L
2
(
x
)
,
…
,
L
Q
(
x
)
)
\Phi ( x ) = \left( 1 , L _ { 1 } ( x ) , L _ { 2 } ( x ) , \ldots , L _ { Q } ( x ) \right)
Φ ( x ) = ( 1 , L 1 ( x ) , L 2 ( x ) , … , L Q ( x ) )
这叫 正交基函数 ‘orthonormal basis functions’,该多项式叫做勒让德多项式(Legendre polynomials)。
minimizing
E
aug
E _ { \text {aug } }
E aug
indirectly getting VC guarantee without confining to
H
(
C
)
H(C)
H ( C )
(heuristically) operating with
E
aug
E _ { \text {aug } }
E aug
E
out
E _ { \text {out} }
E out
E
in
E _ { \text {in} }
E in
H
H
H
E
aug
E _ { \text {aug } }
E aug
E
in
E _ { \text {in} }
E in
E
out
E _ { \text {out} }
E out
Ω
(
w
)
\Omega(\mathbf{w})
Ω ( w )
Ω
(
H
)
\Omega(H)
Ω ( H )
H
H
H
d
v
c
(
H
)
d_{\mathbf{vc}}(H)
d v c ( H )
d
E
F
F
(
H
;
A
⏟
min
E
aug
)
=
d
v
c
(
H
(
C
)
)
d_{\mathbf{EFF}}(H;\underbrace{\mathcal{A}}_{\min E _ { \text {aug } }}) = d_{\mathbf{vc}}(H(C))
d E F F ( H ; min E aug
A ) = d v c ( H ( C ) )
d
v
c
(
H
)
d_{\mathbf{vc}}(H)
d v c ( H )
正则化的目标是限制目标函数的 ‘ 学习方向 ’(constraint in the ‘direction’ of target function)。
正则化有三个特性:
target-dependent:some properties of target(应该目标函数的属性或者范围有关)
plausible:direction towards smoother or simpler (应该是合理的,让算法筛选出比较光滑或简单的hypothesis)
friendly: easy to optimize (比较友好,更容易优化)
值得注意的是正则项中的的
λ
\lambda
λ
λ
\lambda
λ
示意图如下:
其惩罚项表达式如下:
Ω
(
w
)
=
∑
q
=
0
Q
∣
w
q
∣
=
∥
w
∥
1
\Omega ( \mathbf { w } ) = \sum _ { q = 0 } ^ { Q } \left| w _ { q } \right| = \| \mathbf { w } \| _ { 1 }
Ω ( w ) = q = 0 ∑ Q ∣ w q ∣ = ∥ w ∥ 1 L1范数正则化常常用于稀疏解(sparse solution) 。
示意图如下:
其惩罚项表达式如下:
Ω
(
w
)
=
∑
q
=
0
Q
w
q
2
=
∥
w
∥
2
2
\Omega ( \mathbf { w } ) = \sum _ { q = 0 } ^ { Q } w _ { q } ^ { 2 } = \| \mathbf { w } \| _ { 2 } ^ { 2 }
Ω ( w ) = q = 0 ∑ Q w q 2 = ∥ w ∥ 2 2
因为该正则化方法有效的减小了无用项权重系数的大小,所以 L2 范数正则化又叫做权重衰减正则化(weight-decay regularization)。
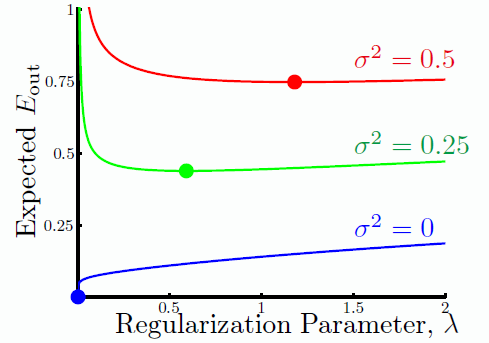
λ
\lambda
λ 在随机噪声(stochastic noise)下的
λ
\lambda
λ
在确定噪声(deterministic noise)下的
λ
\lambda
λ
可见噪声越大,应当使用更多的正则化。但是噪声是不知道,如何进行选择呢,这便用到了下一节课的交叉验证进行模型选择了。
验证实际上就是为了解决模型选择的问题(Model Selection Problem),当然在可行性分析时有证明说,当
N
N
N
E
in
≈
E
out
,
E
in
≈
0
E_{\text {in}} \approx E_{\text {out}}, E_{\text {in}} \approx 0
E in ≈ E out , E in ≈ 0
E
out
≈
0
E_{\text {out}} \approx 0
E out ≈ 0
E
in
E_{\text {in}}
E in
N
N
N
一个简答的方法便是针对测试集进行测试,验证模型的准确率。即使用
D
test
\mathcal{D} _ { \text {test } }
D test
E
test
E _ { \text {test } }
E test
m
∗
=
argmin
1
≤
m
≤
M
(
E
m
=
E
test
(
A
m
(
D
)
)
)
m ^ { * } = \underset { 1 \leq m \leq M } { \operatorname { argmin } } \left( E _ { m } = E _ { \text {test } } \left( \mathcal { A } _ { m } ( \mathcal { D } ) \right) \right)
m ∗ = 1 ≤ m ≤ M a r g m i n ( E m = E test ( A m ( D ) ) )
E
o
u
t
(
g
m
∗
)
≤
E
t
e
s
t
(
g
m
∗
)
+
O
(
log
M
N
t
e
s
t
)
E _ { \mathrm { out } } \left( g _ { m ^ { * } } \right) \leq E _ { \mathrm { test } } \left( g _ { m ^ { * } } \right) + O ( \sqrt { \frac { \log M } { N _ { \mathrm { test } } } } )
E o u t ( g m ∗ ) ≤ E t e s t ( g m ∗ ) + O ( N t e s t log M
)
E
test
E _ { \text {test } }
E test
D
test
\mathcal{D} _ { \text {test } }
D test
所以这里提出一种想法 通过验证集(validation set)
D
val
∈
D
,
D
v
a
l
∼
iid
P
(
x
,
y
)
,
select K examples from
D
at random
\mathcal { D }_{\text{val}} \in \mathcal { D },\mathcal { D } _ { \mathrm { val } } \stackrel { \text { iid } } { \sim } P ( \mathbf { x } , y ),\text{select K examples from } \mathcal{D} \text { at random}
D val ∈ D , D v a l ∼ iid P ( x , y ) , select K examples from D at random
D
val
\mathcal { D }_{\text{val}}
D val
A
m
\mathcal { A }_{\text{m}}
A m
D
val
∩
D
train
=
∅
,
D
val
∪
D
train
=
D
\mathcal { D }_{\text{val}} \cap \mathcal { D }_{\text{train}} = \empty , \mathcal { D }_{\text{val}} \cup \mathcal { D }_{\text{train}} = \mathcal { D }
D val ∩ D train = ∅ , D val ∪ D train = D
基本的结构如下所示:
E
in
(
h
)
E
val
(
h
)
↑
↑
D
⏟
size
N
→
D
train
⏟
size
N
−
K
∪
D
val
⏟
size
K
↓
↓
g
m
=
A
m
(
D
)
g
m
−
=
A
m
(
D
train
)
\begin{array}{ c c c c c } E_{\text {in}}(h) &&&& E_{\text {val}}(h)\\ \uparrow &&&& \uparrow \\ \underbrace { \mathcal { D } } _ { \text {size } N } &\rightarrow &\underbrace { \mathcal { D } _ { \text {train } } } _ { \text {size } N - K } &\cup &\underbrace { \mathcal { D } _ { \text {val } } } _ { \text {size } K }\\ \downarrow && \downarrow && \\ g _ { m } = \mathcal { A } _ { m } ( \mathcal { D } ) &&g _ { m } ^ { - } = \mathcal { A } _ { m } \left( \mathcal { D } _ { \text {train } } \right)&& \end{array}
E in ( h ) ↑ size N
D ↓ g m = A m ( D ) → size N − K
D train ↓ g m − = A m ( D train ) ∪ E val ( h ) ↑ size K
D val
E
o
u
t
(
g
m
−
)
≤
E
v
a
l
(
g
m
−
)
+
O
(
log
M
K
)
E _ { \mathrm { out } } \left( g _ { m } ^ { - } \right) \leq E _ { \mathrm { val } } \left( g _ { m } ^ { - } \right) + O ( \sqrt { \frac { \log M } { K } } )
E o u t ( g m − ) ≤ E v a l ( g m − ) + O ( K log M
)
从
N
−
K
N - K
N − K
N
N
N
E
out
(
g
m
∗
⏟
A
m
∗
(
D
)
)
≤
E
out
(
g
m
∗
−
⏟
A
m
∗
(
D
tann
)
)
E _ { \text {out } } ( \underbrace { g _ { m ^ { * } } } _ { A _ { m ^ { * } } ( \mathcal { D } ) } ) \leq E _ { \text {out } } ( \underbrace { g _ { m ^ { * } } ^ { - } } _ { A _ { m ^ { * } } \left( \mathcal { D } _ { \text {tann } } \right) } )
E out ( A m ∗ ( D )
g m ∗ ) ≤ E out ( A m ∗ ( D tann )
g m ∗ − )
E
o
u
t
(
g
m
∗
)
≤
E
o
u
t
(
g
m
∗
−
)
≤
E
v
a
l
(
g
m
∗
−
)
+
O
(
log
M
K
)
E _ { \mathrm { out } } \left( g _ { m ^ { * } } \right) \leq E _ { \mathrm { out } } \left( g _ { m ^ { * } } ^ { - } \right) \leq E _ { \mathrm { val } } \left( g _ { m ^ { * } } ^ { - } \right) + O ( \sqrt { \frac { \log M } { K } } )
E o u t ( g m ∗ ) ≤ E o u t ( g m ∗ − ) ≤ E v a l ( g m ∗ − ) + O ( K log M
)
g
g
g
g
m
∗
−
g _ { m ^ { * } } ^ { - }
g m ∗ −
g
m
∗
g _ { m ^ { * } }
g m ∗
那在实际中K应当如何选择呢,下面以在
H
Φ
5
\mathcal { H } _ { \boldsymbol { \Phi } _ { 5 } }
H Φ 5
H
Φ
10
\mathcal { H } _ { \boldsymbol { \Phi } _ { 10 } }
H Φ 1 0
其中
g
m
^
g_{\hat m}
g m ^
E
in
E_{\text{in}}
E in
g
m
∗
−
g _ { m ^ { * } } ^ { - }
g m ∗ −
E
val
E_{\text{val}}
E val
D
train
\mathcal{D}_{\text{train}}
D train
g
m
∗
g _ { m ^ { * } }
g m ∗
E
val
E_{\text{val}}
E val
D
\mathcal{D}
D
E
test
E_{\text{test}}
E test
E
out
E_{\text{out}}
E out
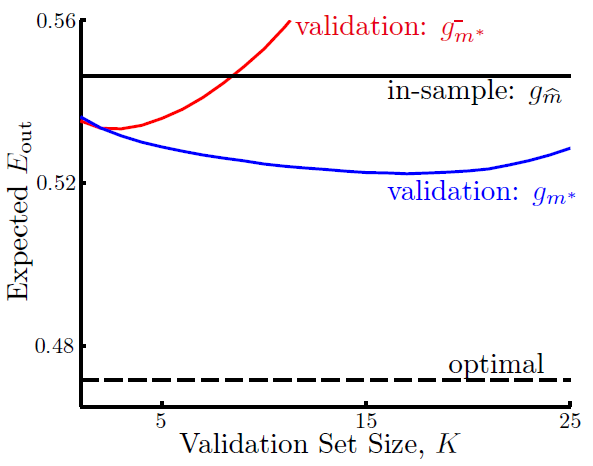
可见
E
out
(
g
m
∗
−
)
>
E
out
(
g
m
∗
)
E_{\text{out}}(g _ { m ^ { * } } ^ { - }) > E_{\text{out}}(g _ { m ^ { * } } )
E out ( g m ∗ − ) > E out ( g m ∗ )
同时随着验证集大小
K
K
K
g
m
∗
−
g _ { m ^ { * } } ^ { - }
g m ∗ −
E
out
E_{\text{out}}
E out
g
g
g
g
−
g^-
g −
g
g
g
g
−
g^-
g −
g
−
g^-
g −
E
out
E_{\text{out}}
E out
E
val
E_{\text{val}}
E val
E
val
E_{\text{val}}
E val
E
out
E_{\text{out}}
E out
g
g
g
E
out
E_{\text{out}}
E out
E
out
(
g
)
≈
(
small
K
)
E
out
(
g
−
)
≈
(
big
K
)
E
val
(
g
−
)
E _ { \text {out } } ( g ) \quad \mathop{\approx}_{(\text{small }K)} \quad E _ { \text {out } } \left( g ^ { - } \right) \quad \mathop{\approx}_{(\text{big }K)} \quad E _ { \text {val } } \left( g ^ { - } \right)
E out ( g ) ≈ ( small K ) E out ( g − ) ≈ ( big K ) E val ( g − )
K
=
N
5
K = \frac{N}{5}
K = 5 N
那怎么才能使得
E
val
(
g
−
)
≈
E
o
u
t
(
g
)
E _ { \text {val } }(g^{-}) \approx E _ { \mathrm { out } } ( g )
E val ( g − ) ≈ E o u t ( g )
E
loocv
(
H
,
A
)
=
1
N
∑
n
=
1
N
e
n
=
1
N
∑
n
=
1
N
err
(
g
n
−
(
x
n
)
,
y
n
)
≈
hope
E
out
(
g
)
E _ { \text {loocv } } ( \mathcal { H } , \mathcal { A } ) = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } e _ { n } = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \operatorname { err } \left( g _ { n } ^ { - } \left( \mathbf { x } _ { n } \right) , y _ { n } \right) \mathop{\approx}^{\text{hope}} E_{\text{out}}(g)
E loocv ( H , A ) = N 1 n = 1 ∑ N e n = N 1 n = 1 ∑ N e r r ( g n − ( x n ) , y n ) ≈ hope E out ( g )
实际上就是每次取出一个样本作为验证集,使用剩下的
N
−
1
N-1
N − 1
E
val
E _ { \text {val }}
E val
E
D
\mathop{\mathcal { E }} _ { \mathcal { D } }
E D
D
\mathcal{D}
D
E
D
E
loocv
(
H
,
A
)
=
E
D
1
N
∑
n
=
1
N
e
n
=
1
N
∑
n
=
1
N
E
D
e
n
→
由
于
独
立
同
分
布
(
i
i
d
)
所
以
E
D
可
拆
为
E
D
n
E
(
x
n
,
y
n
)
=
1
N
∑
n
=
1
N
E
D
n
E
(
x
n
,
y
n
)
err
(
g
n
−
(
x
n
)
,
y
n
)
⏟
=
1
N
∑
n
=
1
N
E
D
n
E
out
(
g
n
−
)
→
一
个
固
定
的
g
在
各
式
各
样
的
样
本
下
的
误
差
均
值
=
1
N
∑
n
=
1
N
E
out
‾
(
N
−
1
)
=
E
out
‾
(
N
−
1
)
\begin{aligned} \mathop{\mathcal { E }} _ { \mathcal { D } } E _ { \operatorname { loocv } } ( \mathcal { H } , \mathcal { A } ) &= \mathop{\mathcal { E }} _ { \mathcal { D } } \frac { 1 } { \mathcal { N } } \sum _ { n = 1 } ^ { N } e _ { n } = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \mathop{\mathcal { E }} _ { \mathcal { D } } e _ { n } \rightarrow 由于独立同分布(iid)所以 \mathop{\mathcal { E }} _ { \mathcal { D } }可拆为\mathop{\mathcal { E }} _ { \mathcal { D_n } }\mathop{\mathcal { E }} _ { \mathcal { (\mathbf{x}_n, y_n) } } \\ &= \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \mathop{\mathcal { E }} _ { \mathcal { D_n } } \underbrace{\mathop{\mathcal { E }} _ { \mathcal { (\mathbf{x}_n, y_n) } } \operatorname { err } \left( g _ { n } ^ { - } \left( \mathbf { x } _ { n } \right) , y _ { n } \right) } \\ & = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \mathop{\mathcal { E }} _ { \mathcal { D_n} } \quad \quad \quad E _ { \text {out } } \left( g _ { n } ^ { - } \right) \rightarrow 一个固定的g在各式各样的样本下的误差均值 \\ & = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \overline { E _ { \text {out } } } ( N - 1 ) = \overline { E _ { \text {out } } } ( N - 1 ) \end{aligned}
E D E l o o c v ( H , A ) = E D N 1 n = 1 ∑ N e n = N 1 n = 1 ∑ N E D e n → 由 于 独 立 同 分 布 ( i i d ) 所 以 E D 可 拆 为 E D n E ( x n , y n ) = N 1 n = 1 ∑ N E D n
E ( x n , y n ) e r r ( g n − ( x n ) , y n ) = N 1 n = 1 ∑ N E D n E out ( g n − ) → 一 个 固 定 的 g 在 各 式 各 样 的 样 本 下 的 误 差 均 值 = N 1 n = 1 ∑ N E out ( N − 1 ) = E out ( N − 1 )
同时当
N
N
N
E
out
‾
(
N
−
1
)
≈
E
out
‾
(
N
)
\overline { E _ { \text {out} } } ( N - 1 ) \approx \overline { E _ { \text {out} } } ( N )
E out ( N − 1 ) ≈ E out ( N )
E
loocv
(
H
,
A
)
≈
E
out
(
g
−
)
E _ { \text {loocv } } ( \mathcal { H } , \mathcal { A } ) \approx E_{\text{out}}(g^{-})
E loocv ( H , A ) ≈ E out ( g − )
E
out
(
g
)
E_{\text{out}}(g)
E out ( g )
V折交叉验证(V-fold cross-validation):将
D
\mathcal{D}
D
E
c
v
(
H
,
A
)
=
1
V
∑
v
=
1
V
E
v
a
l
(
v
)
(
g
v
−
)
E _ { \mathrm { cv } } ( \mathcal { H } , \mathcal { A } ) = \frac { 1 } { V } \sum _ { v = 1 } ^ { V } E _ { \mathrm { val } } ^ { ( v ) } \left( g _ { v } ^ { - } \right)
E c v ( H , A ) = V 1 v = 1 ∑ V E v a l ( v ) ( g v − )
并依此找最优模型:
m
∗
=
argmin
1
≤
m
≤
M
(
E
m
=
E
c
v
(
H
m
,
A
m
)
)
m ^ { * } = \underset { 1 \leq m \leq M } { \operatorname { argmin } } \left( E _ { m } = E _ { \mathrm { cv } } \left( \mathcal { H } _ { m } , \mathcal { A } _ { m } \right) \right)
m ∗ = 1 ≤ m ≤ M a r g m i n ( E m = E c v ( H m , A m ) )
实践经验(practical rule of thumb)选择:
V
=
5
or
10
V = 5 \text{ or } 10
V = 5 or 1 0