1 过拟合问题
1.1 线性回归拟合
以房价预测为例:

- 左边图:我们可以获得拟合数据的这样一条直线,但是,实际上这并不是一个很好的模型。我们看看这些数据,很明显,随着房子面积增大,住房价格的变化趋于稳定或者说越往右越平缓。因此线性回归并没有很好拟合训练数据。我们把此类情况称为欠拟合(underfitting),或者叫作叫做高偏差(bias)。
- 中间图:我们在中间加入一个二次项,也就是说对于这幅数据我们用二次函数去拟合。自然,可以拟合出一条曲线,事实也证明这个拟合效果很好。
- 右边图:对于该数据集用一个四次多项式来拟合。因此在这里我们有五个参数θ0到θ4,这样我们同样可以拟合一条曲线,通过我们的五个训练样本,我们可以得到如右图的一条曲线。一方面,我们似乎对训练数据做了一个很好的拟合,因为这条曲线通过了所有的训练实例。但是,这实际上是一条很扭曲的曲线,它不停上下波动。因此,事实上我们并不认为它是一个预测房价的好模型。所以,我们把这类情况叫做过拟合(overfitting),也叫高方差(variance)。
与高偏差一样,高方差同样也是一个历史上的叫法。从第一印象上来说,如果我们拟合一个高阶多项式,那么这个函数能很好的拟合训练集(能拟合几乎所有的训练数据),但这也就面临函数可能太过庞大的问题,变量太多。
同时如果我们没有足够的数据集(训练集)去约束这个变量过多的模型,那么就会发生过拟合。
过度拟合的问题通常发生在变量(特征)过多的时候。这种情况下训练出的方程总是能很好的拟合训练数据,也就是说,我们的代价函数可能非常接近于 0 或者就为 0。
但是,这样的曲线千方百计的去拟合训练数据,这样会导致它无法泛化到新的数据样本中,以至于无法预测新样本价格。在这里,术语"泛化"指的是一个假设模型能够应用到新样本的能力。新样本数据是指没有出现在训练集中的数据。
1.2 逻辑回归的拟合
线性回归中的过拟合也适用于逻辑回归中。
1.3 如何避免过拟合
方法一:尽量减少选取变量的数量
具体而言,我们可以人工检查每一项变量,并以此来确定哪些变量更为重要,然后,保留那些更为重要的特征变量。至于,哪些变量应该舍弃,我们以后在讨论,这会涉及到模型选择算法,这种算法是可以自动选择采用哪些特征变量,自动舍弃不需要的变量。这类做法非常有效,但是其缺点是当你舍弃一部分特征变量时,你也舍弃了问题中的一些信息。例如,也许所有的特征变量对于预测房价都是有用的,我们实际上并不想舍弃一些信息或者说舍弃这些特征变量。
方法二:正则化
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。
这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。正如我们在房价预测的例子中看到的那样,我们可以有很多特征变量,其中每一个变量都是有用的,因此我们不希望把它们删掉,这就导致了正则化概念的发生。
接下来我们会讨论怎样应用正则化和什么叫做正则化均值,然后将开始讨论怎样使用正则化来使学习算法正常工作,并避免过拟合。
2 代价函数正则化
2.1 正则化思想
以房价预测为例,在前面的介绍中,我们看到了如果用一个二次函数来拟合这些数据,那么它给了我们一个对数据很好的拟合。
然而,如果我们用一个更高次的多项式去拟合,最终我们可能会得到一个曲线,它能很好地拟合训练集,但却并不是一个好的结果,因为它过度拟合了数据,因此,一般性并不是很好。这是为什么呢?
我们优化目标是,也就是说我们需要尽量减少代价函数的均方误差:

让我们考虑下面的假设,我们要加上惩罚项,对于这个函数我们对它添加一些项,加上 1000 乘以![]() 的平方,再加上 1000 乘以
的平方,再加上 1000 乘以![]() 的平方,如下:
的平方,如下:
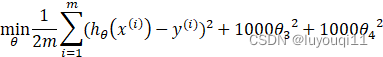
1000 只是随便写的某个较大的数字而已。
现在,为了最小化这个新的代价函数,我们要让![]() 和
和![]() 尽可能小。
尽可能小。
因为,如果你在原有代价函数的基础上加上 1000 乘以![]() 这一项 ,那么这个新的代价函数将变得很大,所以,当我们最小化这个新的代价函数时,我们将使
这一项 ,那么这个新的代价函数将变得很大,所以,当我们最小化这个新的代价函数时,我们将使![]() 的值接近于 0,同样
的值接近于 0,同样 ![]() 的值也接近于 0,就像我们忽略了这两个值一样。如果我们做到这一点(
的值也接近于 0,就像我们忽略了这两个值一样。如果我们做到这一点(![]() 和
和![]() 接近 0 ),那么我们将得到一个近似的二次函数。
接近 0 ),那么我们将得到一个近似的二次函数。
因此,我们最终恰当地拟合了数据,我们所使用的正是二次函数加上一些非常小,贡献很小项(因为这些项的![]() 、
、![]() 非常接近于0)。显然,这是一个更好的假设。这就是正则化的思想。
非常接近于0)。显然,这是一个更好的假设。这就是正则化的思想。
2.2 正则化
正则化不是减少样本的特征值,而是降低高阶特征值的权重(如上面的![]() 、
、![]() 非常接近于0),使得拟合曲线更平滑,更接近于低阶特征值的平滑曲线。防止过度拟合。
非常接近于0),使得拟合曲线更平滑,更接近于低阶特征值的平滑曲线。防止过度拟合。
还是以房价为例,有n=100个输入特征值,有101个参数。
样本特征值:![]()
参 数:![]()
和上面的情况不同,我们对于101个参数,不知道那些参数的权重应该大(即不知道哪个特征值对房价的影响大),也不知道哪些参数的权重应该小(即不知道哪个特征值对房价的影响小)。因此正则化的工作就是在理想的代价函数

中加上![]() ,如下
,如下

项![]() 其作用就是缩小每一个参数
其作用就是缩小每一个参数![]() 的影响。需要注意的是,不需要对
的影响。需要注意的是,不需要对![]() 正则化。
正则化。
正则化项和正则化参数

就是正则化项。式中![]() 做正则化参数,λ 要做的就是控制在两个不同的目标中的平衡关系。
做正则化参数,λ 要做的就是控制在两个不同的目标中的平衡关系。
这样
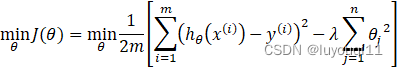
2.3 参数正则化后的目标
- 正则化后的代价函数:

- 目标:
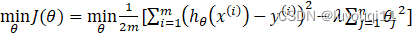
- 第一个目标就是我们想要训练,使假设更好地拟合训练数据。我们希望假设能够很好的适应训练集。i=1mhθxi-yi2

- 第二个目标是我们想要保持参数值较小。(通过正则化项λj=1nθj2
 )
)
正则化参数λ正是需要控制的是这两者之间的平衡,即平衡拟合训练的目标和保持参数值较小的目标。从而来保持假设的形式相对简单,来避免过度的拟合。
对于我们的房屋价格预测来说,我们之前所用的非常高的高阶多项式来拟合,我们将会得到一个非常弯曲和复杂的曲线函数,现在我们只需要使用正则化目标的方法,那么你就可以得到一个更加合适的曲线,但这个曲线不是一个真正的二次函数,而是更加的流畅和简单的一个曲线。这样就得到了对于这个数据更好的假设。
再一次说明下,这部分内容的确有些难以明白,为什么加上参数的影响可以具有这种效果?但如果你亲自实现了正规化,你将能够看到这种影响的最直观的感受。
2.4 正则化示例说明
在正则化线性回归中,如果正则化参数值 λ 被设定为非常大,那么将会发生什么呢?
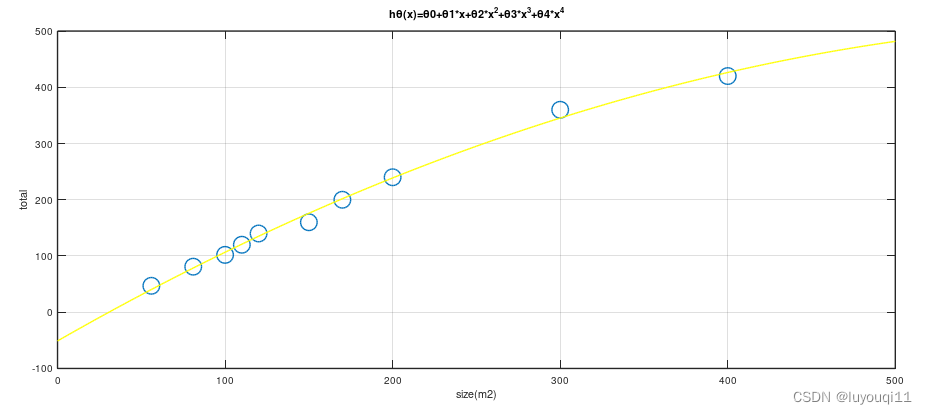
我们若拼命加大惩罚参数![]() 也就是说,我们最终惩罚
也就是说,我们最终惩罚![]() 在一个非常大的程度,那么我们会使所有这些参数接近于零。
在一个非常大的程度,那么我们会使所有这些参数接近于零。
如果我们这么做,那么就是我们的假设中相当于去掉了这些项,并且使我们只是留下了一个简单的假设,这个假设只能表明房屋价格等于 ![]() 的值,那就是类似于拟合了一条水平直线,对于数据来说这就是一个欠拟合 (underfitting)。这种情况下这一假设它是条失败的直线,对于训练集来说这只是一条平滑直线,它没有任何趋势,它不会去趋向大部分训练样本的任何值。这句话的另一种方式来表达就是这种假设有过于强烈的"偏见" 或者过高的偏差 (bais),认为预测的价格只是等于 θ0 。对于数据来说这只是一条水平线。
的值,那就是类似于拟合了一条水平直线,对于数据来说这就是一个欠拟合 (underfitting)。这种情况下这一假设它是条失败的直线,对于训练集来说这只是一条平滑直线,它没有任何趋势,它不会去趋向大部分训练样本的任何值。这句话的另一种方式来表达就是这种假设有过于强烈的"偏见" 或者过高的偏差 (bais),认为预测的价格只是等于 θ0 。对于数据来说这只是一条水平线。
因此,为了使正则化运作良好,我们应当注意一些方面,应该去选择一个不错的正则化参数 λ 。当我们以后讲到多重选择时我们将讨论一种方法来自动选择正则化参数 λ ,为了使用正则化,接下来我们将把这些概念应用到到线性回归和逻辑回归中去,那么我们就可以让他们避免过度拟合了。