博客里要用的资源在这里
资源 点我啊
多项式回归
应用场景
在分析数据的时候,我们会遇到不同的数据分布情况,当数据点呈现带状分布的时候我们会选择线性回归的方法去拟合,但是如何数据点是一条曲线的时候使用线性回归的方法去拟合效果就不是那么好了,这个时候我们可以使用多项式回归的方法,本文主要讲述了一元多项式回归
一元多项式回归
处理方法分析:
y=w0 + w1 x + w2 x2 + w3 x3 + … + wd xd
将高次项看做对一次项特征的扩展得到:
y=w0 + w1 x1 + w2 x2 + w3 x3 + … + wd xd
也就是说把一元多项式转为了多元线性回归去训练得到模型,求得的w0,w1…wn同样使用于原来的一元多项式,
多项式特征扩展:
如果我们使用线性回归的模型去拟合散点图,得到结果为一条直线
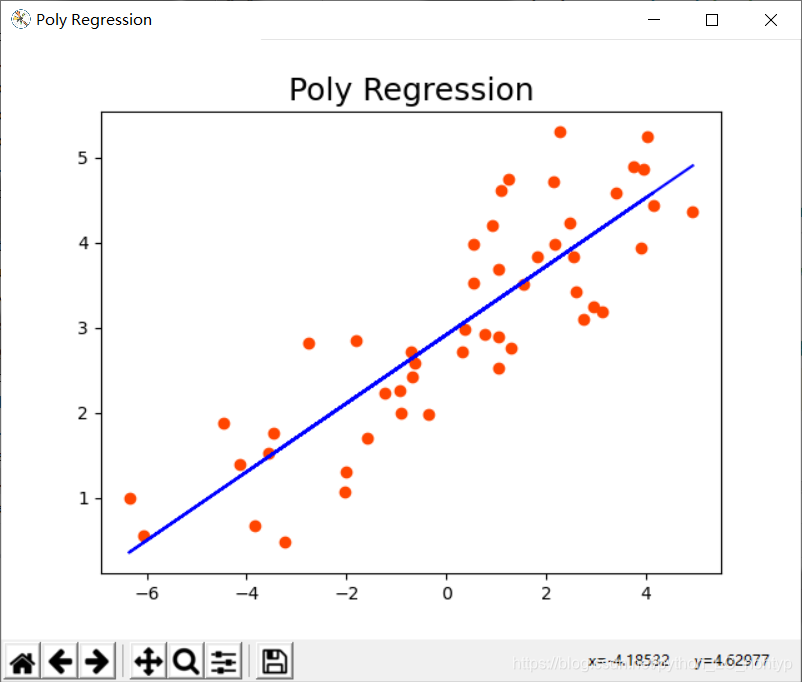
那么如果我们想让这条直线拐弯应该怎么做呢? 答案很简单,加上二次项或者多次项即可,在加上二次型和多此项的过程中同时也会增加特征值,这样就可以完成特征值的拓展,下面我们写一下具体的推导过程
双变量线性回归模型形如下面式子:
所以一元多项式回归的实现需要两个步骤:
通过结合二阶多项式的特征,添加二次方项,将它从平面转换为抛物面:
用z代替x可得:
那么就可以写成这种方式:
本质上就是做了一个变量替换,这样就又变回了线性回归模型
那么一元多项式回归即可以看做为多元线性回归,可以使用LinearRegression模型对样本数据进行模型训练。
- 将一元多项式回归问题转换为多元线性回归问题(只需给出多项式最高次数即可)。
- 将1步骤得到多项式的结果中 w1 w2 … 当做样本特征,交给线性回归器训练多元线性模型。
使用sklearn提供的数据管线实现两个步骤的顺序执行:
import sklearn.pipeline as pl
import sklearn.preprocessing as sp
import sklearn.linear_model as lm
model = pl.make_pipeline(
sp.PolynomialFeatures(10), # 多项式特征扩展器
lm.LinearRegression()) # 线性回归器
案例:
import numpy as np
import sklearn.pipeline as pl
import sklearn.preprocessing as sp
import sklearn.linear_model as lm
import sklearn.metrics as sm
import matplotlib.pyplot as mp
# 采集数据
x, y = np.loadtxt('../ml_data/single.txt', delimiter=',', usecols=(0,1), unpack=True)
x = x.reshape(-1, 1)
# 创建模型(管线)
model = pl.make_pipeline(
sp.PolynomialFeatures(10), # 多项式特征扩展器
lm.LinearRegression()) # 线性回归器
# 训练模型
model.fit(x, y)
# 根据输入预测输出
pred_y = model.predict(x)
test_x = np.linspace(x.min(), x.max(), 1000).reshape(-1, 1)
pred_test_y = model.predict(test_x)
mp.figure('Polynomial Regression', facecolor='lightgray')
mp.title('Polynomial Regression', fontsize=20)
mp.xlabel('x', fontsize=14)
mp.ylabel('y', fontsize=14)
mp.tick_params(labelsize=10)
mp.grid(linestyle=':')
mp.scatter(x, y, c='dodgerblue', alpha=0.75, s=60, label='Sample')
mp.plot(test_x, pred_test_y, c='orangered', label='Regression')
mp.legend()
mp.show()
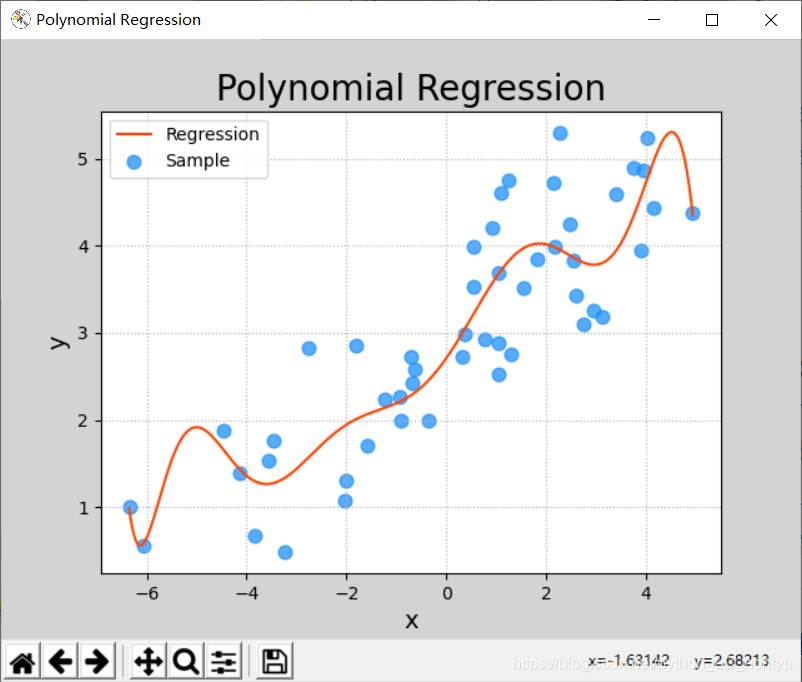
过拟合和欠拟合
过于简单的模型,无论对于训练数据还是测试数据都无法给出足够高的预测精度,这种现象叫做欠拟合。
过于复杂的模型,对于训练数据可以得到较高的预测精度,但对于测试数据通常精度较低,这种现象叫做过拟合。
一个性能可以接受的学习模型应该对训练数据和测试数据都有接近的预测精度,而且精度不能太低。
训练集R2 测试集R2
0.3 0.4 欠拟合:过于简单,无法反映数据的规则
0.9 0.2 过拟合:过于复杂,太特殊,缺乏一般性
0.7 0.6 可接受:复杂度适中,既反映数据的规则,同时又不失一般性
